
[TOC]
前文:以下是我入门PWN的记录,欢迎各位前来观看,小弟领教!
CTF是什么?
CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。发展至今,已经成为全球范围网络安全圈流行的竞赛形式。
CTF比赛形式主要为线上解题(jeopardy)和线下攻防(Attack With Defence)
线上赛题目大致方向有WEB、RE、PWN、MISC、CRYPTO,解出flag交给服务器验证通过才得分。
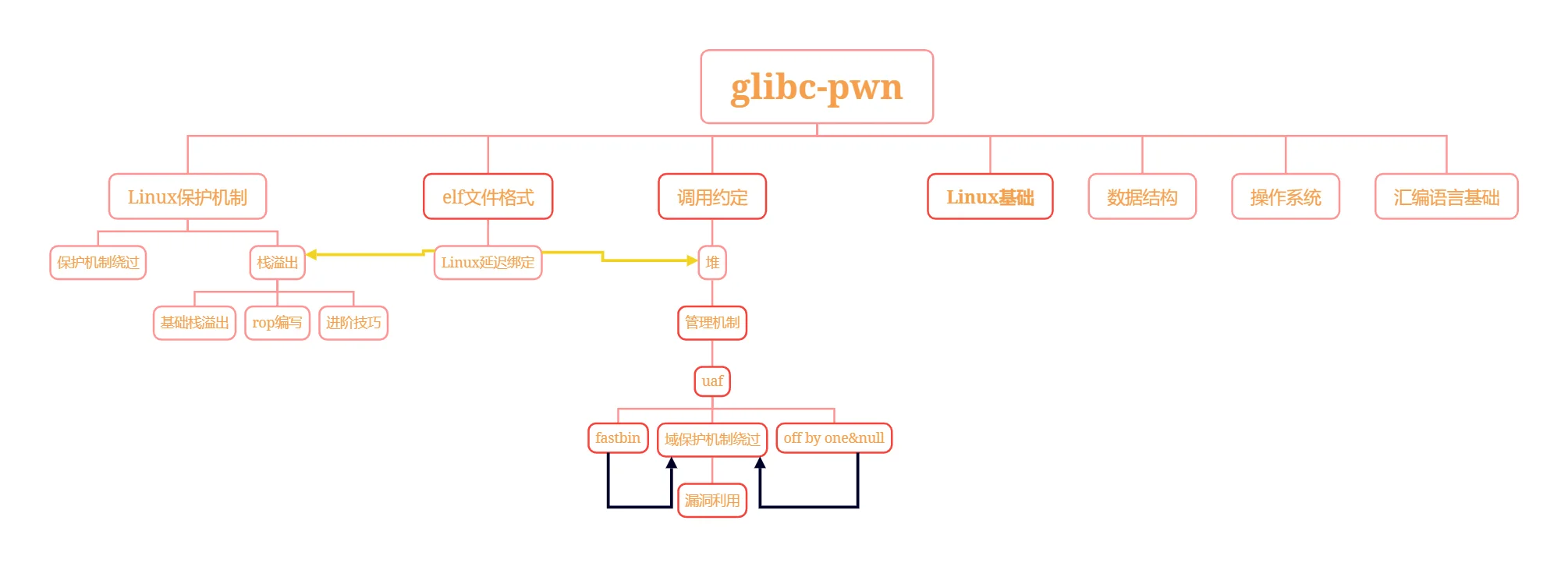
PWN简介
Pwn是什么?
"Pwn"是一个黑客语法的俚语词,是指攻破设备或者系统。发音类似“砰”,对黑客而言,这就是成功实施黑客攻击的声音一研的一声,被“黑”的电脑或手机就被你操纵了。CTF中的PWN主要是针对于二进制漏洞挖掘与利用,通常情况下选手需要对于一个有漏洞的可执行文件进行分析,找到漏洞,然后利用漏洞读取远程服务器上的FLAG。

Pwn传统出题方向:glibc PWN:堆、栈、shellcode编写、iofile等。进阶:arm架构、loT、内核、vm、浏览器等。
所需工具:pwntools、pwndbg、IDA、虚拟机(Ubuntu或Kali)、LibcSearcher、ropper&ROPgadgets、one_gadget、Ruby
实际生活中我们会遇到的pwn:
泄露通信数据:心脏滴血(cve-2014-0160)
Linux本地提权root:脏牛dirty cow(cve-2016-5195)
Wannacry:永恒之蓝勒索病毒
PWN入门劝退集......
汇编语言基础
我自己在打ctf逆向和pwn,也时常搞不懂bit和byte,在这里我先把一些计算机内的量词回忆一下:
| 名称 | 翻译 | 大小 |
|---|---|---|
| bit | 比特 | 1位(1b) |
| byte | 字节 | 8位(1B) |
| word | 字 | 16位 |
| dword | 双字 | 32位 |
| qword | 四字 | 64位 |
计算机寻址方式
在当前主流的操作系统中,都是以字节(B)为寻址单位进行寻址。
意味着计算机访问的最小单位是一个字节(B)。
类比于人口普查,普查员以每户(B)为单位统计,而不是访问到个人(b)。
寄存器
计算机的指令都是由CPU来执行。
在计算机系统结构中,CPU和内存是分开的。
寄存器存在于CPU中,是CPU的直接操作对象。
| 寄存器名称 | 作用 | 备注 |
|---|---|---|
| RAX | 通用寄存器 | 低32位:EAX;低16位:AX;低8位:AL |
| RBX | 通用寄存器 | 低32位:EAX;低16位:AX;低8位:AL |
| RCX | 通用寄存器 | 低32位:EAX;低16位:AX;低8位:AL |
| RDX | 通用寄存器 | 低32位:EDX;低16位:DX;低8位:DL |
| RDI | 通用寄存器 | 低32位:EDI |
| RSI | 通用寄存器 | 低32位:ESI |
| R8 | 通用寄存器 | 低32位:E8D |
| R9 | 通用寄存器 | 低32位:E9D |
| R10 | 通用寄存器 | 低32位:E10D |
| R11 | 通用寄存器 | 低32位:E11D |
| R12 | 通用寄存器 | 低32位:E12D |
| R13 | 通用寄存器 | 低32位:E13D |
| R14 | 通用寄存器 | 低32位:E14D |
| R15 | 通用寄存器 | 低32位:E15D |
| RSP | 栈顶指针 | 低32位:ESP |
| RBP | 栈底指针 | 低32位:EBP |
| EFLAGS | 标志寄存器 | 记录标志状态,包括AF、PF、SF、ZF、OF、CF等标识位 |
| RIP | 指令计数器 | 保存下一条将会执行的指令的地址 |
上述的通用寄存器,通常用于参数传递以及算数运算等通用场合。
RSP为栈顶指针,RBP为栈底指针,二者用于维护程序运行时的函数栈,在之后的调用约定一节会对其进行讲解。
EFLAGS为标志位寄存器,用于存储CPU运行计算过程中的状态,如进位溢出等。
RIP指针用于存储CPU下一条将会执行的指针,不能直接修改,正常情况下会每一次运行一条指令自增一条指令的长度,当发生跳转时才会以其他形式改变其值。
CPU的寻址方式
学过C语言都知道指针,它是一个变量,它存储的是另一个变量的内存地址,而不是直接存储数据本身。这里解释的是比较含糊,详细的还请搜索引擎。
| 寻址方式 | 示例 | 实际访问 |
|---|---|---|
| 立即寻址 | 1234h | 1234h这个数字本身 |
| 直接寻址 | [1234h] | 内存地址1234h |
| 寄存器寻址 | RAX | 访问RAX寄存器 |
| 寄存器间接寻址 | [RAX] | 访问RAX寄存器存储的值的这一内存地址 |
| 变址寻址 | [RAX+1234h] | 访问RAX寄存器存储的值+1234h这一内存地址 |
汇编指令
| 指令类型 | 操作码 | 例子(Intel格式) | 实际效果 |
|---|---|---|---|
| 数据传送指令 | mov | mov rax rbx | rax = rbx |
| 取地址指令 | lea | lex rax [rbx] | rax =&*rbx |
| 算数运算指令+ | add | add rax rbx | rax = rax + rbx |
| - | sub | sub rax rbx | rax = rax - rbx |
| 逻辑运算指令 | and | and rax rbx | rax = rax&rbx |
| xor | xor rax rbx | rax = rax | rbx | |
| 函数调用指令 | call | call 1234h | 执行内存地址1234h处的函数 |
| 函数返回指令 | ret | ret | 函数返回 |
| 比较 | cmp | cmp rax rbx | 比较rax与rbx,结果保存在EFLAG寄存器 |
| 无条件跳转 | jmp | jmp 1234h | eip = 1234h |
| 栈操作指令 | push | push rax | 将rax存储的值压栈 |
| pop | pop rax | 将栈顶的值赋值给rax,rsp+=8 |
不难发现两个操作数指令的目的寄存器都是第一个寄存器,刚开始看的话有些奇怪。
细心的同学可能会注意到call和jmp指令看起来效果都一样,但是描述却有些不同,call的话是函数调用,需要一些函数地址的保存压栈参数传递的操作,而jmp指令类似于C、Python语言的函数中的if、else语句,只涉及跳转,不能作为函数调用来使用。
另外在pop时rsp为何是+8而不是-8。
上述问题留到之后的调用约定中讲解......
了解到上述汇编语言后,感觉生词特别多,这对我感觉也是,不过我建议还是学过C语言和有一点入门Python之后再去看汇编语言,不然会很坐牢的,因为:
计算机在执行汇编代码时,只会顺序执行。
通过call、jmp、ret这种指令来完成跳转,所以汇编指令代码的执行流并不像高级语言程序一样流程明确。(在学习了C语言的指针这块的知识点,这会让你学汇编比较有利的)
汇编指令代码会经常跳转导致可读性差一些,但执行效果是和高级语言(C、Python语言)差不多的。
给点表格太懵了,我列出些例子(assembly--C)来看看:
|
|
不难发现,汇编语言的类似条件语句的jmp、jge不像if、else那样会有个比较符号(>=、<、!=、==)这样明显区分的,而是jge默认有条件跳转——大于等于>=则跳转,jmp则是强制跳转(而不是小于<就跳转),这点需要记住咯。
这里的jge是通过eflag寄存器中的标志位来判断的,而eflag的标志位是通过之前的cmp来设置的。
loop的情况稍些复杂,这里单独为其解释下:
|
|
loop自带a- -、a =a -1的作用,所以rcx=5的话,那就循环执行5次,rcx=0就退出循环。
好难啊,要长脑子了......
还是用C语言开开路吧:
|
|
数值上下限/溢出
计算机不能存储无限大的数,这个数的数值有一定上限和下限。在这里了解下就好,学C语言都知道的。
| 类型 | 存储空间大小 | 最小值(一一对应) | 最大值(一一对应) |
|---|---|---|---|
| char | 1个字节 | -128 或 0 | 127 或 255 |
| unsigned char | 1个字节 | 0 | 255 |
| signed char | 1个字节 | -128 | 127 |
| int | 2个或4个字节 | -32 768 或 -2 147 483 648 | 32767 或 2 147 483 647 |
| unsigned int | 2个或4个字节 | 0 | 65535或4 294 967 295 |
| short | 2个字节 | -32 768 | 32767 |
| unsigned short | 2个字节 | 0 | 65 535 |
| long | 4个字节 | -2 147 483 648 | 4 294 967 295 |
| unsigned long | 4个字节 | 0 | 4 294 967 295 |
| long long (C99) | 8个字节 | -9 223 372 036 854 775 808 | 9 223 372 036 854 775 807 |
| unsigned long long | 8个字节 | 0 | 18 446 744 073 709 551 615 |
如果是unsigned 也就是无符号数,数据的每一位都是代表数据。如果是signed有符号数,那么数据的最高位会被当作符号位处理。0代表正数,1代表负数。
溢出(这些比较有辨识度,看到就知道是溢出就好)
数值有上下限范围,那么就不可避免的会有溢出情况。以32位int为例,有以下四种溢出:
无符号上溢:0xffffffff + 1变成0
无符号下溢:0-1变成0xffffffff
有符号上溢:有符号正数0x7fffffff +1 变成负数0x80000000
无符号下溢:有符号数0x80000000 -1 变成正数0x7fffffff
这就是整数溢出。通常来说原因就是两点:
存储位数不够
溢出到符号位
整数溢出一般配合别的漏洞来使用。
汇编小结
汇编语言贯穿PWN、Reverse(逆向)的,比较重要。
|
|
Linux基础
这一章内容多是一些文字描述,也会有生活案例加以理解,图片较少,较为枯燥。
保护层级:分为四个ring0-ring3。一般来说就两个:0为内核,3为用户。
权限:用户分为多个组
文件和目录等等的权限一般都是三个,即可读可写可执行, 读:R,写:W,执行:X
赋予一个可执行文件执行权限就是chmod +x filename
操作系统
在第一阶段学习中我们接触到了Linux操作系统的相关指令:
| 名称 | 作用 | 示例(以Kali虚拟机为例) |
|---|---|---|
| ls | 列出当前目录文件 | ls |
| cd | 切换目录 | cd/home/ctf |
| pwd | 打印当前目录 | pwd |
| touch | 创建空白文件 | touch flag |
| mkdir | 创建目录 | mkdir /home/ctf |
| rmdir | 删除目录 | rmdir /home/ctf |
| rm | 删除文件 | rm flag |
| cp | 复制文件 | cp /home/ctf/flag /home/flag |
| mv | 移动文件 | mv flag /home/ctf/flag |
| cat | 输出文件内容 | cat flag |
| diff | 比较两个文件信息 | diff flag1 flag2 |
| chmod | 切换执行权限 | chmod 777 elf1 |
| locate | 查找文件 | locate flag |
数据存储
计算机内部有两种数据的存储形式:大端序、小端序。
大端序:数据高位存储在计算机地址的低位,数据低位存储在地址的高位。
小端序:数据高位存储在计算机地址的高位,数据低位存储在地址的低位。
大端序:高低低高
小端序:高高低低
这时我也看不懂,上例子!
我们以一个数据:0x123456789abcdef;那么0为低地址,7为高地址。
大端序存储:低位储存到计算机地址高位...
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 01 | 23 | 45 | 67 | 89 | ab | cd | ef |
将此数据按照字符串输出,得到:\x01\x23\x45\x67\x89\xab\xcd\xef
小端序存储:低位储存到计算机地址的低位...
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| ef | cd | Ab | 89 | 67 | 45 | 23 | 01 |
将此数据按照字符串输出,得到:\xef\xcd\xab\x89\x67\x45\x23\x01
从上面这两种方式比较的话,可以知道,大端序符合人类的阅读习惯;但从存储逻辑、数学运算规律来看,小端序更正常。
Linux数据存储的格式为小端序
Linux是小端序储存,所以我们以字符串的形式输入一个数字时,要注意格式,比如输入0xdeadbeef这个数字。
字符串输入就是“\xef\xbe\xad\xde”传入给程序。不过好在有pwntools,p32(0xdeadbeef)即可完成自动转换。
文件描述符
Linux系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行 I/O 操作的系统调用都会通过文件描述符。
每个文件描述符会与一个打开的文件相对应,不同的文件描述符也可能指向同一个文件。
相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开。
我们会在open、read、write这些常见函数中见到。
0标准输入(stdin)、1标准输出(stdout)、2标准错误(stderr)read(0,buf,size)从stdin中读size个数据到buf中,write(1,buf,size)从buf中取size个数据到stdout中。
栈(stack)
学过数据结构都知道,这是一种储存方式:是一种遵循「后进先出(LIFO, Last In First Out)」原则的线性数据结构,类似于日常生活中堆叠的盘子 —— 最后放上去的盘子,会被最先取走。
栈的核心特性: 操作受限:只能在栈的一端(通常称为「栈顶」)进行数据的插入(称为「入栈」或 push)和删除(称为「出栈」或 pop),另一端(「栈底」)固定不动。
由于函数调用顺序也是LIFO,所以我们能接触到的绝大多数系统,都是通过栈这一数据结构来维护函数调用关系。
顺序访问:只能从栈顶开始依次访问元素,无法直接访问栈中间或栈底的元素。
说得我都懵了,这啥??通俗讲就是栈好比是一个薯片罐,只有一个罐口,把薯片装进去后,最后放的薯片总是被第一个拿出来,倒数第二个被放进去的,在后面被打开时都是第二个先被拿出来,这就是栈的顺序访问特点啦,而栈就是薯片罐这种存储器的名字。
等会?这放到机器语言如C语言的话,不就是数组吗?为什么那么麻烦要发明这个栈呢?就是方便一些,一把普通菜刀能切水果、剁骨头,为什么要发明水果刀和大砍刀?原因就是方便。
栈其实就是一个“阉割版”的数组,只能在一头操作。
Linux种的栈
在linux系统中,系统为每一个进程都安排了一个栈,进程中每一个调用的函数都有自己独立的栈帧。
在linux系统中,栈是由高地址向低地址生长(小端序)。
换句话说,高地址为栈底,低地址为栈顶。那么为什么这么反直觉反人类的安排呢?
我们接触到的一些算法,很多都是用栈来实现的,比如DFS。DFS会将发现的节点存储在栈中,然后访问的顺序就是LIFO。但是很多这种LIFO的算法都会以递归的形式实现。其实,递归的形式实现这些算法本质上来说也是利用栈结构,只不过他没有在程序中另外申请一个栈,而是用的函数调用栈。
为什么栈从高地址向低地址生长?
有的说法是这么设计和小端序更配合(比如说访问一个数据的低字节)。
这里我的认知有限,我也不能解答,过于理论化研究也是很牢的。这只能留到未来的自己去解答了,这里先标记一下以后再单独出一篇Blog文章来讲解。只能先死记一下咯/************。
调用约定
看标题就是关于函数调用的内容,在上一章汇编指令就有预示了,像call调用函数地址、jmp无条件跳转。
再来回顾下栈的指令:
pop出栈/弹栈,Pop指令的作用是弹栈,将栈顶的数据弹出到寄存器,然后栈顶指针向下移动一个单位。具体来说:如pop rax,作用就是mov rax [rsp];add rsp 8(平衡栈指针:当手动修改栈指针后(如临时分配栈空间),用 add rsp, 8 恢复栈的对齐状态,确保后续操作符合 8 字节对齐要求);
push压栈,Push指令的作用就是压栈,将栈顶指针向上移动一个单位的距离,然后将一个寄存器的值存放在栈顶,具体来说:如push rax,其实际效果就是:sub rsp 8; mov [rsp] rax;
add rsp 8的8怎么来的?在 x86-64 架构(64 位系统)中: 寄存器(如 rsp、rax 等)是 64 位(8 字节)的。内存地址也是 64 位的,最小的可寻址单位是字节,但栈操作通常以8 字节为单位进行对齐(这是系统调用和函数调用的标准要求)。
函数调用流程
从一个实例出发,main调用func_b, func_b调用func_a。我们从main函数开始,逐步分析栈帧变化:
|
|
当运行到call func b时main函数的栈帧。Rbp指向栈底,rsp指向栈底 这段栈帧存放了一些main的局部变量。 main函数要调用func b,main只需要call func b, 也就是push rip;mov rip func b;
那么此时跳转到func_b继续执行,func _b直接执行主逻辑吗? 显然不是的,被调用函数还需要维护栈帧。
具体来说,需要以下几步:
push rbp;将调用函数的栈底指针保存。
mov rbp rsp;将栈底指针指向现在的栈顶。
sub rsp xxx;开辟被调用函数的栈帧,此时上一步的rbp就指向栈帧的底。
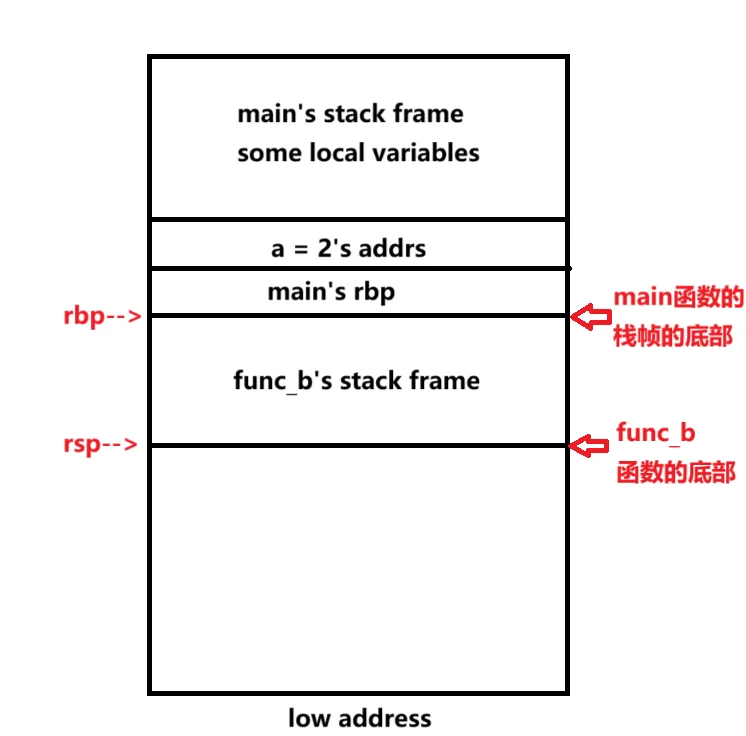
图很明了了吧。但我起初一看,为什么int a =2所在地址要高于fun_b函数?不是funb函数要先比int a=2先执行吗?
自问自答:要理解这个问题,需结合函数调用栈的生长方向和代码执行顺序与栈帧分配的关系来分析,栈是从高地址向低地址生长的
代码执行顺序是:main → func_b → func_a → 返回 func_b → 定义 int c = 1 → 返回 main → 定义 int a = 2。
因为每个函数调用通常会占用一个栈帧,所以说fun_b函数会被分配在main函数之下(main函数先执行,固然main是位于高地址),而int a = 2 属于 main 栈帧的局部变量,因此地址高于 func_b 的栈帧。
来我们继续分析这图,func_b执行完维护栈帧操作后的栈布局。 所谓栈帧的维护就是维护rbp和rsp两个指针。 Rsp永远指向当前栈的顶部(Rsp在哪和栈顶在哪关系不大,但Rsp是指向它所在的栈帧的顶部)。 Rbp用来定位局部变量。
接着,再往下运行程序,调用func_a函数。
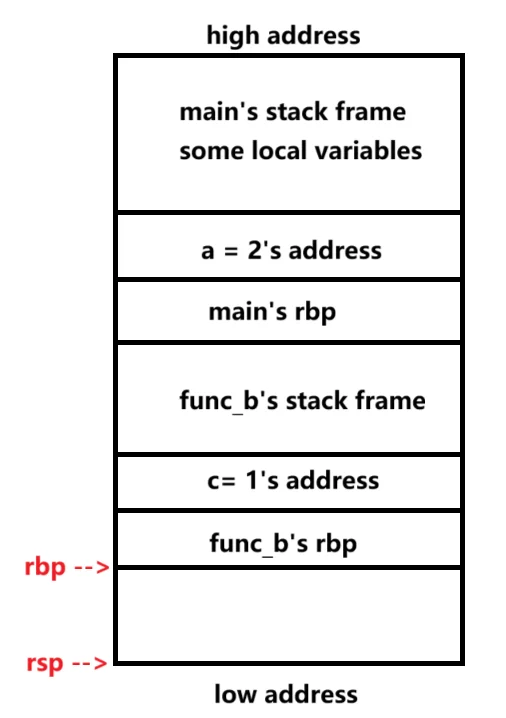
那这里的每一个栈帧就代表我之前所说的薯片啦,一片片被拿出来,一个个运行。
func_b调用完func_a后的栈布局。至此,示例的函数调用已经完毕。 现在,func_a执行完毕,要返回了。如何维护栈帧呢?
在这里,我们学习一个新的汇编指令leave:
<<<<<<< HEAD 作用是维护栈帧,通常出现在函数的结尾,与ret(return)连用。其实际作用为:mov rsp rbp;pop rbp;即:将栈顶指针指向栈帧的底部、然后在栈中弹出新的栈底指针。
在一个函数执行结束返回时,会执行leave;ret;
实际效果就是:mov rsp rbp; poprbp; pop eip; 此时我们观察程序执行完func_a时的栈帧,如下图:
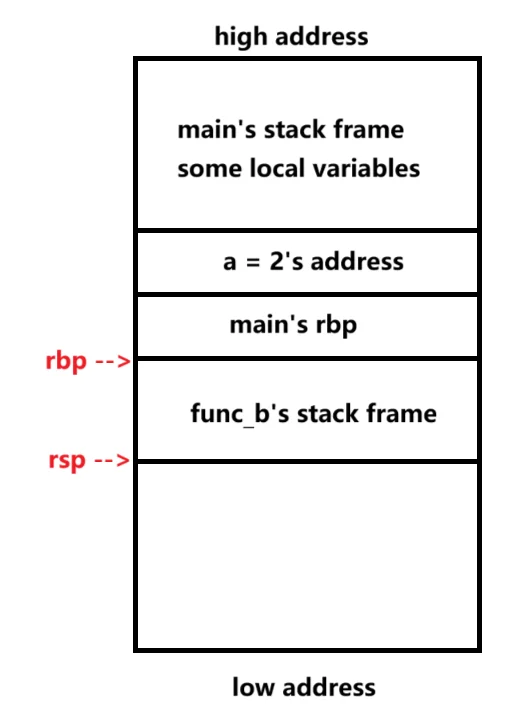
可以说,与之前的func_b未调用func_a前的栈帧对比,是一模一样,说明已经恢复了栈帧。唯一不同之处在于此时程序的rip已经指向了c=1后面一条指令,说明func_a已经执行完毕。
以此类推,func_b执行完毕返回后,栈布局如下图:
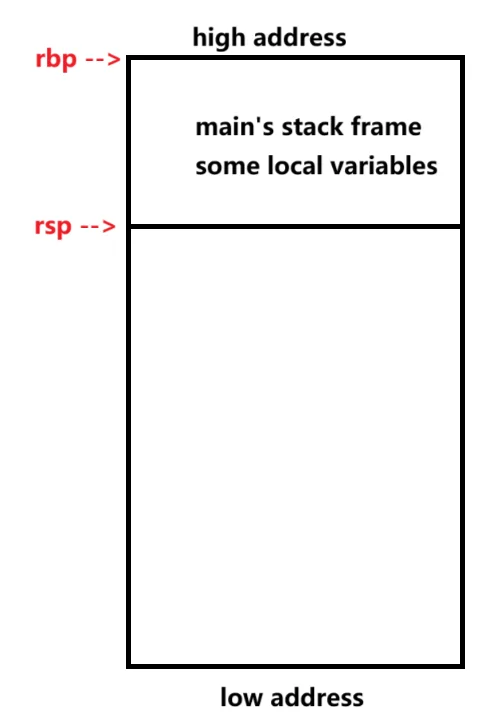
在这之后,main函数继续执行此时布局变回开始执行程序时的栈布局,直到结束。至此,函数的调用返回执行流程结束。
总结:
调用函数:只需要将rip压栈(保存到当前栈帧),即push rip,然后讲rip赋值为被调用函数的起始地址,这一操作被隐性的内置在call指令中。
被调用函数:push rbp;mov rbp rsp; sub rsp 0xxxx。即保存调用函数的rbp指针,将自己的rbp指针指向栈顶,然后开辟栈空间给自己用,此时rbp就变成了被调用函数的栈底。
函数返回:leave;ret;翻译过来就是:mov rsp rbp;pop rbp;pop rip;即恢复栈帧,返回调用函数的返回地址。
这里有个疑问,为什么在调用过程种,寄存器rsp这类会出现很多的赋值操作,比如上述的“mov rsp rbp;pop rbp;pop rip”,rsp更像是一个中间变量,一直变化。其实这是有原因的。
rsp 看似动态变化,但它的变化是完全遵循栈操作的逻辑和函数调用约定的。栈是一种后进先出的数据结构,在函数调用过程中,参数入栈、局部变量分配内存(通过调整 rsp 来实现)、保存寄存器值等操作,都需要通过修改 rsp 的值来改变栈顶位置,以完成对栈内存的合理使用和管理 。而在函数返回阶段,又要通过调整 rsp 来恢复之前的栈状态,释放当前函数占用的栈空间。
而rbp 明确划分了当前函数栈帧的范围:从 rbp(底部)到 rsp(顶部)之间的内存区域,它更像是一个固定的描点,数值不变依靠rsp变化来完成操作。
所以,这些寄存器的赋值操作都是为了严格按照计算机体系结构和编程语言的函数调用规范,实现函数调用、执行和返回过程中的内存管理、数据保护以及程序执行流的正确控制。
简单说,
rsp是 “动态变化的栈顶指针”,而rbp是 “固定不动的栈帧基准”—— 前者负责管理栈的实时状态,后者负责锚定当前栈帧的位置和范围、栈帧的局部变量,二者配合实现了函数调用过程中内存的有序管理。
调用约定
返回值:一般来说,一个函数的返回值会存储到RAX寄存器。 X86-64函数的调用约定为:
从左至右参数一次传递给rdi、rsi、rdx、rcx、r8、r9。
如果一个函数的参数多于6个,就不在寄存器传参了,而是从右至左压入栈中传递。
作用是维护栈帧,通常出现在函数的结尾,与ret(return)连用。其实际作用为:mov rsp rbp;pop rbp;即:将栈顶指针指向栈帧的底部、然后在栈中弹出新的栈底指针。
系统调用
syscall指令,用于调用系统函数,调用时需要指明系统调用号码。系统调用号存在 rax 寄存器中,然后布置好参数,执行syscall即可。
| 调用号码 | 名称 |
|---|---|
| 0 | read |
| 1 | write |
| 2 | open |
| 3 | close |
| 9 | mmap |
| 37 | alarm |
| 60 | exit |
| 62 | kill |
| 59 | execv |
还有一些调用号码没列出来,其实上网查一查就行,这东西用多了就记住了,前期不用刻意死记硬背的。
看到这里,是不是有点熟悉,看过《第一阶段》的操作系统章节就知道,有chmod 777 <文件>:设定文件使用权限的指令。正好就是1+2+4,4代表是x执行权限,这里表格没写出来。所以入门pwn我就建议大家去学那个Linux操作系统,基础过一下,不用精通,不然你强行入门PWN很懵的。
示例:调用read(0,buf,size):
从左至右参数一次传递给rdi、rsi、rdx、rcx、r8、r9(寄存器)
|
|
ELF文件
elf
linux环境中,二进制可持性文件的类型是ELF(Executable and Linkable Format)文件。
elf文件的格式比较简单,我们需要了解的就是elf文件中的各个节、段等概念。elf的基本信息存在于elf的头部信息中,这些信息包括指令的运行架构、程序入口等内容,可以通过readelf -h <elf_name>来查看头部信息,当然打过CTF-MISC的知道的话估计会去用010editor,都可。
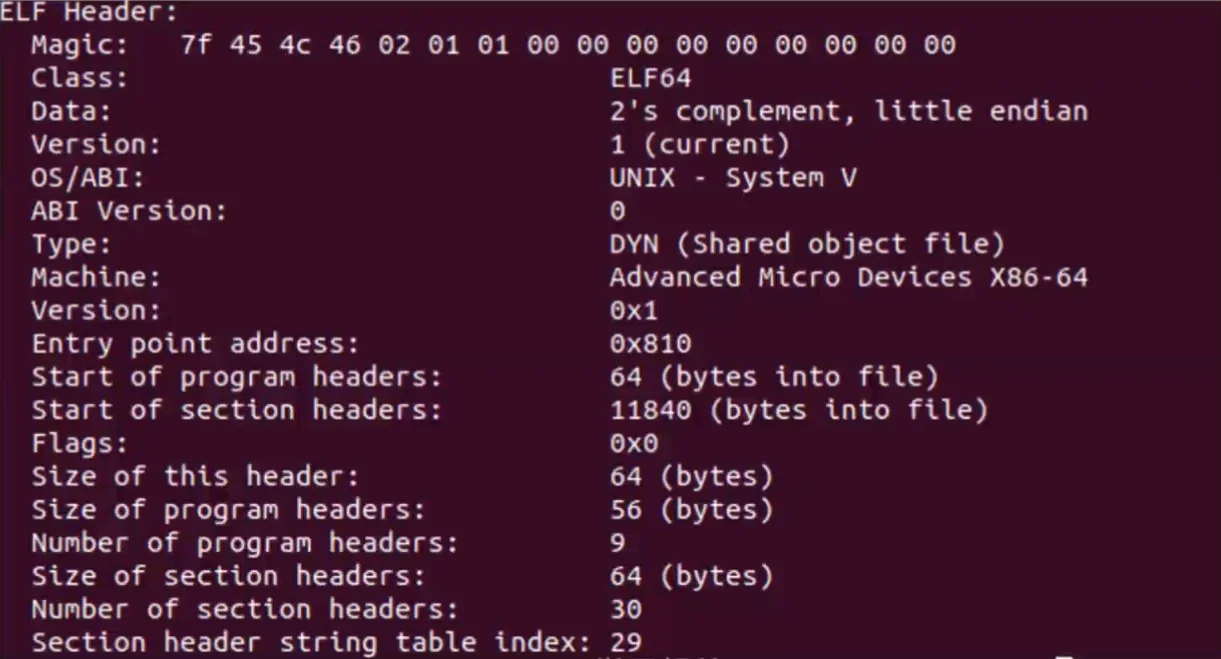
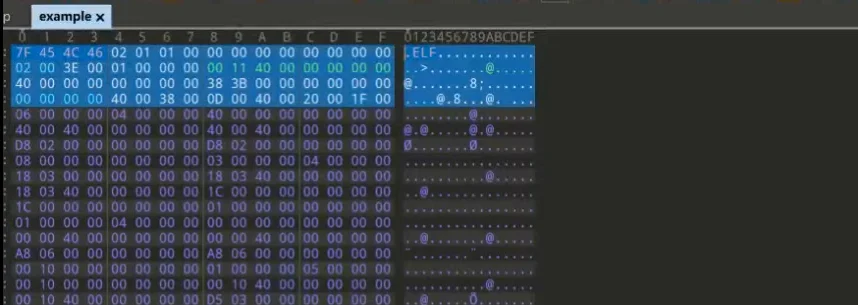
第二第三张图就是ELF文件了,这种文件并不是常规的ZIP这些噢。
elf文件中包含许多个节(section),各个节中存放不同的数据,这些节的信息存放在节头表中,readelf -S <file>查看,这些节主要包括:
| 名称 | 作用 |
|---|---|
| .text | 存放程序运行的代码 |
| .rdata | 存放一些如字符串等不可修改的数据 |
| .data | 存放已经初始化的可修改的数据 |
| .bss | 存放未被初始化的程序可修改的数据 |
| .plt 与 .got | 程序动态链接函数地址 |
elf文件不是我们所说的常规文件,不在我们的电脑桌面上,而是存在磁盘文件里,它本质上是存储在磁盘(硬盘、SSD 等)上的 “常规文件”,运行程序时,这个程序的elf文件才会加载到内存里,这就是我们所说的运行内存。
elf文件在加载进入内存时: elf文件的节(section)会被映射进内存中的段(segment),而这一映射过程遵循的机制是根据各个节的权限来进行映射的。
换句话说,可读可写的节被映射入一个段,只读的节被映射入一个段。
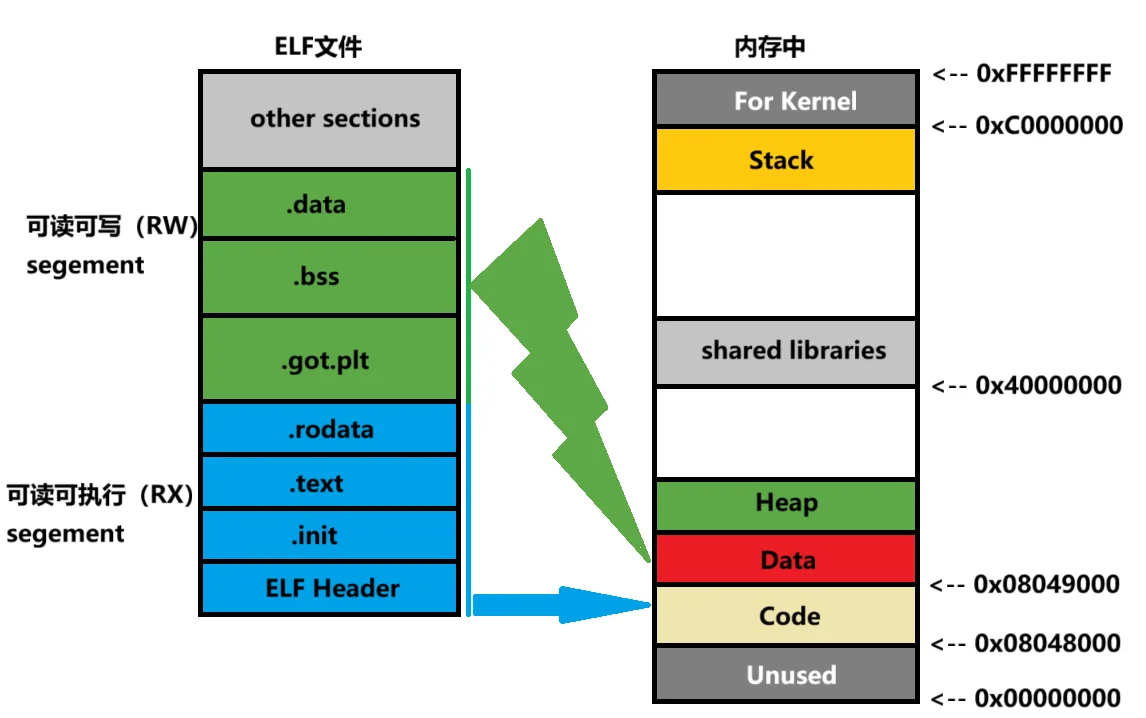
单个elf文件内部多个节被合并映射入一个段,此时就标志着elf文件被启动运行了。
根据上述讲解,可以知道ELF文件以两种状态存在:
| 状态 | 存储位置 | 用途 | 能否被CPU直接执行 |
|---|---|---|---|
| 未运行时 | 磁盘 | 保存程序的指令和数据(静态文件) | 不能(CPU只认识内存数据) |
| 运行时 | 运行内存 | CPU从内存读取指令并执行 | 能 |
In other words,ELF 文件是 “程序的静态载体”(存磁盘),确保程序能从源代码正确转换为可执行文件,并在内存中被正确加载和运行。
libc
什么是libc?
glibc是linux下面C标准库的实现,全称GNU C Library。
glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准C库,而Linux下原来的标准C库Linux libc逐渐不再被维护。
Linux下面的标准C库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
等等......so后缀??.so时啥文件,本质上也是个elf文件

通常.so用./的指令运行后会给出版本信息,当然,用file命令也是可以的:

Linux基本上所有的程序都依赖libc,所以libc中的函数至关重要。当然CTFpwn也离不开libc:IDA分析libc、源码。
延迟绑定机制
在上章的elf文件,看到了.got和.plt文件,用于动态链接函数地址。
动态链接库
我们程序开发过程中都会用到系统函数,比如read,write, open等等。这些系统函数不需要我们实现,因为系统已经帮你完成这些工作,只需要调用即可,存放这些函数的库文件就是动态链接库。通常情况下,我们对于PWN接触到的动态链接库就是libc.so文件。
静态编译和动态编译
这里我们举一个例子来类比静态编译与动态编译的概念:
小明要开一个餐馆(program),餐馆的菜单上有几百种菜肴(函数),小明的餐馆每天都会来很多顾客,每个顾客点的菜都可能不一样。我们知道,每道菜所需要的食材(系统函数)都不一样,这些食材都存放于仓库(动态链接库)中。
那么现在问题来了,小明如何保证每个顾客点的菜都能被满足呢?
第一种方式:小明把仓库中所有的食材都搬进厨房(静态编译)这时,小明不需要挪地方(静态),只需要在厨房中就可以工作,但是 这会带来冗余,可能厨房中的食材很多都用不上。高效
第二种方式:小明每次遇到新的所需要的食材,才去仓库取(动态编译)。这时,小明可能挪动的比较频繁(动态),但是可以保证厨房面没那么多可能用不到的东西。全面
一个程序运行过程中可能会调用许许多多的库函数,这些库函数在一次运行过程中不能保证全部被调用。
静态编译的思路就是将所有可能运行到的库函数一同编译到可执行文件中。这一方式的优点就在于在程序运行中不需要依赖动态链接库。适用的场合就是比如你本地编译的程序需要的动态链接库版本比较特殊,如果在别的机器上运行可能对方动态链接库版本和你不一样会出bug,这时候用静态编译。
缺点就是变异过后程序体积很大,编译速度也很慢。
对于动态编译,优点是缩小了执行文件本身的体积,另一方面是加快了编译速度,节省本地的系统资源。
缺点是使用链接库的命令,需要附带相对庞大的链接库,如果其他计算机没有安装对于的运行库,则动态编译的可执行文件就不能运行。
欸欸看回小明,他要选第二种方式(动态编译),但每次去仓库找食材太麻烦了,而且仓库这么大,,于是他用小本本记下了在仓库的每样食材的位置(got表),下一次找这件食材就高效多了。这就是got。
延迟绑定
这就是linux的延迟绑定机制,而存放这个地址的小本子就是got表。got表全程是Global Offset Table,也就是全局偏移量表。
在程序运行时,got表初始并不保存库函数的地址,只有在第一次调用过后,程序才将这一地址保存在got表中。
PLT与GOT
GOT(Global Offset Table,全局偏移表):数据段用于地址无关代码的 Linux ELF 文件中确定全局变量和外部函数地址的表。
PLT(Procedure Linkage Table,程序链接表): Linux ELF 文件中用于延迟绑定的表。
ELF 中有.got和.plt.got 两个 GOT 表,got 表用于全局变量的引用地址,.got.plt 用于保存函数引用的地址。
不论是第几次调用外部函数,程序真正调用的其实是plt表。plt表其实是一段段汇编指令构成。
PLT 工作流程
在第一次调用外部函数时,plt表首先会跳到对应的got表项中。由于并没有被调用过,此时的got表存储的不是目标函数地址,此时的got表中存储的地址是pt表中的一段指令,其作用就是准备一些参数,进行动态解析。跳转回plt表后,plt表又会跳转回plt的表头,表头内容就是调用动态解析函数,将目标函数地址存放入got表中。
第一次调用外部函数,以调用C语言的printf为例子去详细讲解:
1、调用时,汇编语言执行到call printf时,先跳向PLT表中printf对应的条目(plt[printf]),这么说好像起到jmp跳转地址的作用啊。只是类似,并未跳转地址,而此时编译还不知道,而是先跳转PLT表中位该函数预留的一个”小跳板“(plt[printf])。
2、**plt[printf]**第一次被调用时,此时GOT表中还没被填充真实地址(因为此前没有被解析过),所以里头并不是printf的真实地址,而是plt[printf]中下一条指令的地址(也就是jmp*GOT[printf])。
call printf → 跳向plt[printf] → 执行jmp *GOT[printf] → 此时GOT[printf]里已是真实地址,直接跳过去执行。此时就知道printf的真实地址了。
3、**跳回PLT后,执行”准备解析参数“的指令。**plt[printf]的下一条指令是准备动态解析需要的参数:比如把printf对应的符号索引(用于告诉动态链接器 “要解析哪个函数”)压入栈中。这些参数是提前在编译时就写好的,目的是告诉动态链接器 “我要找的是printf,帮我查它的真实地址”。这些参数是提前在编译时就写好的,目的是告诉动态链接器 “我要找的是printf,帮我查它的真实地址”。
4、**跳向PLT表头(plt[0]),触发动态链接器的解析函数。**准备好参数后,plt[printf]会跳向 PLT 表的 “表头”(plt[0])。plt[0]里的指令是固定的:先把GOT[0]的地址压栈(GOT[0]存储着动态链接器需要的辅助信息),然后调用动态链接器的核心解析函数(_dl_runtime_resolve)。
???这有个疑问,怎么会有函数来帮助外部函数如printf去确定地址呢?其实这个
_dl_runtime_resolve函数比较特殊,它是动态链接器的组成部分,是已经预先存在于动态链接器的代码之中的,动态链接器一加载,它的地址就被先解析出来了。
5、动态链接器解析出真实地址,写入 GOT 表,完成绑定
以下是用汇编语言代码来概括这五步流程:
|
|
这五步也就系统概括了小明在厨房做菜麻烦需要用小本本记下仓库的所需食材的存放地方(地址)的过程。
总结:PLT 和 GOT 的协作核心
PLT 是 “跳板”:负责第一次调用时触发解析流程,后续调用时直接转发到 GOT 中的真实地址。
GOT 是 “缓存表”:第一次调用时存储 PLT 内的跳转地址(用于触发解析),解析后存储函数真实地址(供后续直接调用)。 整个机制的目的是 “延迟解析”:避免程序启动时解析所有外部函数(耗时),只在第一次调用时解析,平衡启动速度和运行效率。
理解了这个流程,就掌握了动态链接中最核心的 “懒绑定” 机制,这也是 CTFpwn 中 “PLT 劫持” 等漏洞利用的基础。
Linux安全防护机制
栈溢出、指针悬挂、内存地址泄露等Bug会导致程序崩溃,一些攻击者会刻意制造这些漏洞来扰乱程序正常执行,这就是早期PWN的威力。这一章比较重要,几乎贯穿后续栈溢出、堆的题目。
保护机制
CANARY、NX、ASRL、PIE、RELRO
栈的作用为存储函数调用相关信息以及函数的局部变量。
这些局部变量通常为数组或者输入的缓冲区(buf)。而函数调用相关的信息,主要是返回地址和栈底指针(rbp)。
CANARY
Canary中文翻译就是金丝雀,来源是之前科技不发达时,矿工会在下井作业时带一个金丝雀,用来判断地下环境有没有煤气之类的毒气泄漏,金丝雀没事,大家继续干活;金丝雀如果死了,大家赶紧跑。
在Linux中,Canary的作用就如同他引用的一样,用来判断程序的执行环境,主要是针对检测栈溢出。
canary是一个开头字节为\x00的一段长度为八个字节(x64)的随机数,这个随机数本体存放于 fs 段偏移为 0x28 的区域。
在每次函数调用中,程序都会将这段随机数存放于栈底,每次运行结束返回时,都会将这一随机数与他的本体进行比对。如果这个值被改变,则意味着发生了栈溢出,程序直接退出,没有改变的话,程序继续执行。
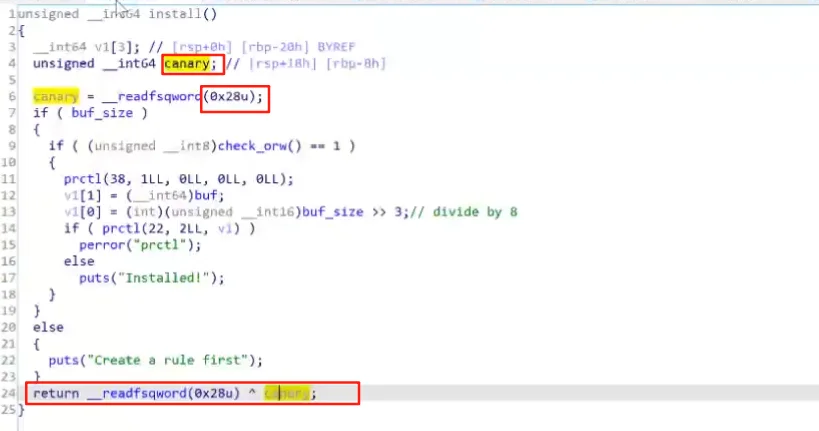
由于canary开头字节为x00,所以通常情况下不能被打印出来。
通常情况下,程序如果开启了canary保护,大概率说明这道题目不是栈溢出题目了。当然也要具体情况具体分析。
绕过方法主要就是修改canary或者泄漏canary。
泄漏 canary:利用格式化字符串、栈溢出 + 输出功能等漏洞,读取栈上的 canary 值(注意首字节 \x00 的影响)。
修改 canary:用泄漏的 canary 值,在栈溢出时覆盖栈上的 canary,使其与原始值(fs:0x28 处)一致,绕过检查。
NX
NX意思就是Not Executable,开启这个保护后,程序中的堆、栈、bss段等等可写的段就不可以执行。这就意味着如果开启了NX保护,通常情况下我们就不能执行我们自己编写的shellcode。
绕过的方式通常是用mprotect函数来改写段的权限,nx保护对于rop或者劫持got表利用方式不影响。
PIE和ASLR
在我们编写ROP或者shellcode时,有一个问题是绕不开的,那就是找到函数地址:
PIE指的就是程序内存加载基地址随机化,意味着我们不能一下子确定程序的基地址。
ASLR与PIE大同小异,ASLR是程序运行动态链接库、栈等地址随机化。
通常来说,CTF中的PWN题与这两个保护打交道的次数最多。
绕过方式就是泄露函数地址,然后通过函数的偏移来确定基地址。
-
PIE:是针对可执行文件本身的编译选项。开启后,可执行文件(ELF)会被加载到内存中的随机地址,其内部的代码段、数据段等位置不再是固定值(编译时不指定绝对地址,而是用相对偏移)。 作用:让攻击者无法预先知道程序代码、全局变量等在内存中的绝对地址。
-
ASLR:是操作系统级别的保护机制。开启后,操作系统会随机化进程的内存布局,包括共享库(.so)的加载地址、栈、堆、内核映射区域等的起始地址。 作用:让攻击者无法预测共享库函数(如 libc 中的 system)、栈 / 堆数据的内存地址。
该文件只有 3 种合法取值,分别对应不同的 ASLR 策略,具体如下:
取值 名称 作用(随机化范围) 安全强度 0 关闭ASLR 完全不随机化:栈、堆、共享库、内核空间的地址每次运行都固定不变。 最低 1 部分随机化(默认) 部分区域随机:栈地址、VDSO(虚拟动态共享对象)地址随机化;堆、共享库地址不随机。 中等 2 完全随机化 全区域随机:栈、堆、共享库、VDSO 地址全部随机化;64 位系统还会随机化内核空间。 最高 1)查看当前 ASLR 状态
1 2# 读取文件内容,输出 0/1/2 中的一个 cat /proc/sys/kernel/randomize_va_space(2)临时修改 ASLR 强度
1 2 3 4 5 6# 1. 关闭 ASLR sudo echo 0 > /proc/sys/kernel/randomize_va_space # 2. 恢复默认部分随机化 sudo echo 1 > /proc/sys/kernel/randomize_va_space # 3. 开启完全随机化(高安全需求) sudo echo 2 > /proc/sys/kernel/randomize_va_space
关联:两者通常配合使用 ——PIE 让可执行文件本身地址随机化,ASLR 让系统其他内存区域随机化,共同增加内存地址预测难度。
区别核心:PIE 是编译时决定的程序属性,ASLR 是系统运行时的布局策略。
通俗点理解:
ASLR 是操作系统搞的 “整体大洗牌”:每次程序运行时,系统会把整个内存空间的布局(比如共享库放哪、栈和堆从哪开始)随机换个位置,让攻击者猜不到常用函数(比如 system)或数据的具体地址。 ASLR 像每次开演唱会时,场馆里的座位区(共享库)、后台(堆)、观众入口(栈)的位置都随机换。
PIE 是针对单个程序的 “自身随机化”:如果程序编译时开了 PIE,它自己加载到内存时,代码和数据会随机放在一个不确定的位置(而不是固定地址),让攻击者连程序自己的函数、变量在哪都猜不准。 PIE 像演出团队(程序本身)每次上场时,自己的站位(代码和数据)也随机变。
RELRO
RELRO(Relocation Read-Only,重定位只读)是一种针对 ELF 文件重定位表的保护机制,核心作用是限制对 GOT(全局偏移表)等重定位相关区域的修改权限,防止攻击者通过篡改 GOT 表实现函数劫持(如修改printf的 GOT 条目为system地址)。
这个保护主要针对的是延迟绑定机制,意思就是说got表这种和函数动态链接相关的内存地址,对于用户是只读的。
开启了这个保护,意味着我们不能劫持got表中的函数指针。
RELRO 的两种模式及作用:
Partial RELRO(部分 RELRO)
仅将 GOT 表的前半部分(.got.plt)设置为只读,后半部分仍可写。 作用:基本防止对已解析的函数地址(GOT 表中已填充的条目)进行修改,但仍有一定安全隐患。
Full RELRO(完全 RELRO)
将整个 GOT 表(包括.dynamic 等重定位相关段)设置为只读,并在程序启动时提前解析所有动态链接符号(关闭延迟绑定)。 作用:彻底阻止对 GOT 表的修改,同时消除延迟绑定可能带来的漏洞(如 PLT 表劫持),但会略微增加程序启动时间。
总结
以上就是六大章节,因为感觉学着每一章关系好像不是很大,前面elf后面又接个Linux保护机制,感觉很脱节,也可能是我的笔录存在不足,如果你们看到这里又问题的话,欢迎在评论区交流,Blogger会看到的!!!
在这里总结下:
汇编语言
讲了些量词:
| 名称 | 翻译 | 大小 |
|---|---|---|
| bit | 比特 | 1位(1b) |
| byte | 字节 | 8位(1B) |
| word | 字 | 16位 |
| dword | 双字 | 32位 |
| qword | 四字 | 64位 |
汇编语言就是机器码的一个助记符,为了让人能看懂
然后有一些常见寄存器种类需要去了解的,篇幅太长,可以回到上面去看:RBP栈底指针、RAX-R15通用寄存器、RSP栈顶指针、EFLAGS标志寄存器、RIP指令计数器......;各种各样的寻址方式......
更重要的是认识了一门语言:汇编语言;初步了解一些汇编指令,如操作码、指令类型、实例和C语言运行得到效果比较...
溢出
Linux基础
初步了解Linux的基本内容,保护层级ring、文件描述符、及Linux计算机内部的大端小端序存储形式
大端序:数据高位存储在计算机地址的低位,数据低位存储在地址的高位。
小端序:数据高位存储在计算机地址的高位,数据低位存储在地址的低位。
初步认识栈的定义、作用、在PWN所发挥的威力。
调用约定
这里重要的是函数调用流程,重点讲解push、pop、call、ret、jmp等汇编指令的使用效果。
学习调用约定:返回值:一般来说,一个函数的返回值会存储到RAX寄存器。
X86-64函数的调用约定为:从左至右参数一次传递给rdi,rsi,rdx,rcx,r8,r9。如果一个函数的参数多于6个,则从右至左压入栈中传递。
系统调用:
| 调用号码 | 名称 |
|---|---|
| 0 | read |
| 1 | write |
| 2 | open |
| 3 | close |
| 9 | mmap |
| 37 | alarm |
| 60 | exit |
| 62 | kill |
| 59 | execv |
ELF文件
elf是 Linux 环境下二进制可执行文件的标准格式,存储在磁盘上,运行时加载到内存包含多个节(如.text 代码节、.data 数据节、.plt/.got 动态链接相关节等),节在加载时按权限合并映射到内存中的段有两种状态:未运行时作为静态载体存于磁盘,运行时加载到内存供CPU 执行。
libc是 Linux 下的 C 标准库(最常用的是 glibc),以.so 文件(本质也是 ELF)形式存在(如 /lib/libc.so.6) 包含大量基础函数,是绝大多数程序的依赖,在 CTF Pwn 中具有重要地位。
两者关系:程序(ELF)运行时会动态链接 libc 中的函数,通过PLT/GOT 等机制实现调用。
延迟绑定机制
动态链接库与编译方式:
动态链接库(如 libc.so)存系统函数(read、printf 等),程序无需自己实现,动态调用即可;
静态编译:把所有可能用到的库函数打包进可执行文件,不依赖外部库但体积大;
动态编译:仅在调用时从库中取函数,体积小但依赖外部库。
PLT 与 GOT 的作用和延迟绑定: 为解决动态编译中 “找函数地址” 的效率问题,用 GOT(全局偏移表,像 “小本本”)存函数地址,PLT(程序链接表,像 “跳板”)负责调用逻辑; 延迟绑定:程序启动时不解析所有函数地址,第一次调用时才通过 PLT 触发动态链接器(用_dl_runtime_resolve 函数)解析真实地址,并存入 GOT,后续调用直接读 GOT 即可。
第一次调用外部函数的流程: 调用函数→跳 PLT 对应条目→GOT 未存真实地址,跳回 PLT 准备参数→跳 PLT 表头触发解析→动态链接器解析地址写入 GOT→后续调用直接用 GOT 地址。
Linux安全防护机制
| 保护机制 | 核心作用 | 关键特点 | 绕过方式 |
|---|---|---|---|
| CANARY | 检测栈溢出 | 栈底存 8 字节(x64)随机数(首字节 \x00),返回前比对 | 先泄漏栈上 canary,再用泄漏值覆盖栈上 canary |
| NX | 防 shellcode 执行 | 栈、堆等可写区域标记为 “不可执行” | 用 mprotect 改权限,或用 ROP、GOT 劫持 |
| PIE | 程序自身加载地址随机 | 编译选项决定,每次运行加载地址不同 | 泄漏程序内函数地址,算基地址 |
| ASLR | 系统内存布局随机 | 系统机制,随机库、栈、堆地址 | 泄漏库函数地址,算目标函数地址 |
| RELRO | 防 GOT/PLT 劫持 | 分 Partial(.got.plt 只读)、Full(全 GOT 只读) | Partial 可攻未保护 GOT 段;Full 弃 GOT 攻其他 |
结尾
基本的PWN理论知识就到这里了,现在你看别人PWN神的writeup应该不会这么“牢”了吧,基本能看懂别人说的专用词了。