[TOC]
网路空间安全导论
网络安全行业简介
⽹络安全(Cyber Security)是指⽹络系统的硬件、软件及其系统中的数据受到保护,不因偶然
的或者恶意的原因⽽遭受到破坏、更改、泄露,系统连续可靠正常地运⾏,⽹络服务不中断。
起源与发展
互联网发展迅速。互联⽹(Internet)是⼀种全球性的计算机⽹络。 通过电⼦,⽆线和光纤⽹络等等⼀系列⼴泛的技术连接着全球各地的设备和⼈,它基于⼀组通⽤的协议相互连接,形成逻辑上的单⼀巨⼤国际⽹络。
互联⽹始于1969年的美国阿帕⽹(ARPANET),最初是为了军事研究⽬的⽽建⽴的。随后,互联⽹逐渐发展成为⼀个覆盖全球的、由各种⽹络相互连接⽽成的庞⼤⽹络。
网络安全意识与法律法规
法律法规
必须了解下,不然容易迷失自我~~
中华人民共和国网络安全法.pdf
网络安全就业
企业需求(哪些岗位需求大、薪资高)
岗位方向
网络安全管理概述
安全运营、运维、模型
等级保护
操作系统基础
问:为什么没有鸿蒙系统呢??因为鸿蒙系统的基层代码开发,使ta本质上属于Linux,即ta的系统内核时Linux的,所以按分类ta属于Linux系统。以下是我认为作为网安人有必要去了解的一些基本操作系统知识,要详细的话还得去上完整课才。
Windows系统
windows的一些常规命令自己知道就好,在这里不一一介绍,在下文中提到的命令,如果没见过就自己去搜一搜哈。
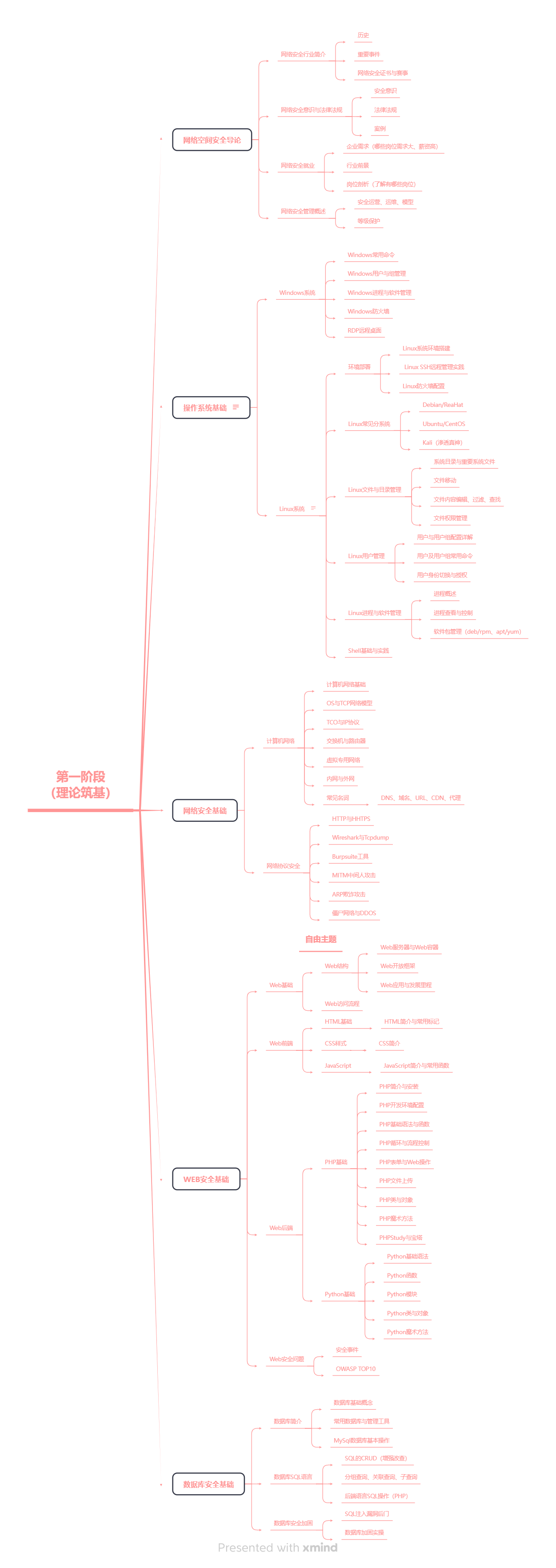
Windows用户与组管理
Windows是多用户操作系统,即同一时间内允许多个用户同时使用计算机。用户组是一系列用户的集合,组内的用户自动具备该组所设置的权限。常用用户:
system:本地机器上拥有最高权限的用户(为系统核心组件访问文件资源提供权限)
Administrator:默认系统管理员用户
常用组:
SYSTEM:最高权限的组
Administrators:管理员组(完全控制权)
Users:普通用户组
诸如上述的效果可以通过这些指令:
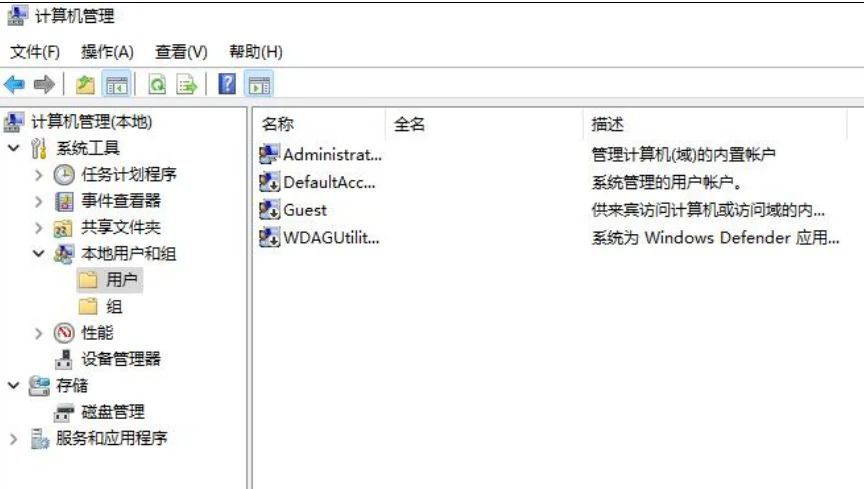
查看用户指令:
查看用户信息:
新增用户:
1
net user < 用户名> <密码> /add
删除用户:
1
net user < 用户名> /del #del就是delete(删除)的缩写
新增用户组:
1
net localgroup < 组名> /add
将指定用户添加到指定组:
1
net localgroup < 组名> <用户名> /add
其实还有很多,比如开电脑的“户”的whoami、查看主机名的hostname、查看网络连接是否正常的ping呀、目录dir、天天用的cd/d,这些都是基础,在此提一下就好。
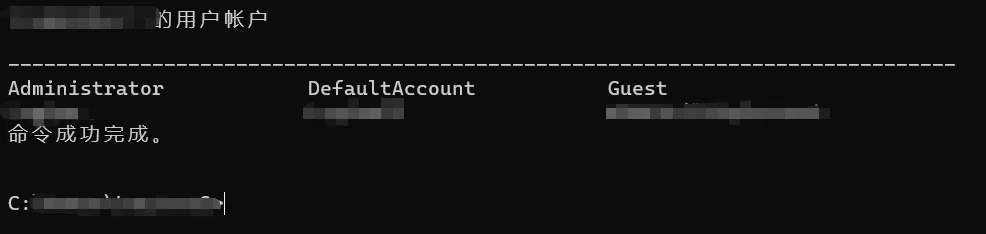
Windows防火墙
防火墙(firewall)是一项协助确保信息安全的设备,会依照特定的规则,允许或限制传输的数据通过。Windows defender防火墙顾名思义就是在Windows操作系统中系统自带的软件防火墙。它有助于提高计算机的安全性。
入站规则:别人电脑访问自己电脑的规则,出站规则:自己电脑访问别人电脑的规则。
RDP远程桌面
RDP远程桌面,即远程桌面协议(Remote Desktop Protocol),是一种由微软公司研发并内置于Windows操作系统中的网络通信协议。
RDP是一个多通道的协议,它允许用户通过网络连接到提供微软终端机服务的计算机,并在本地计算机上查看和操作远程计算机的桌面界面。通过RDP,用户可以远程登录到运行Windows操作系统的远程计算机,并像在本地计算机上一样使用远程计算机的资源和应用程序,这个其实类似我们如今todesk、向日葵远程等。
市面上的远程链接软件如todesk都采用自研的混合传输协议,比较安全,而RDP连接没那么可靠,毕竟连接需要给出用户的密码和用户名,这相对有一定的风险。
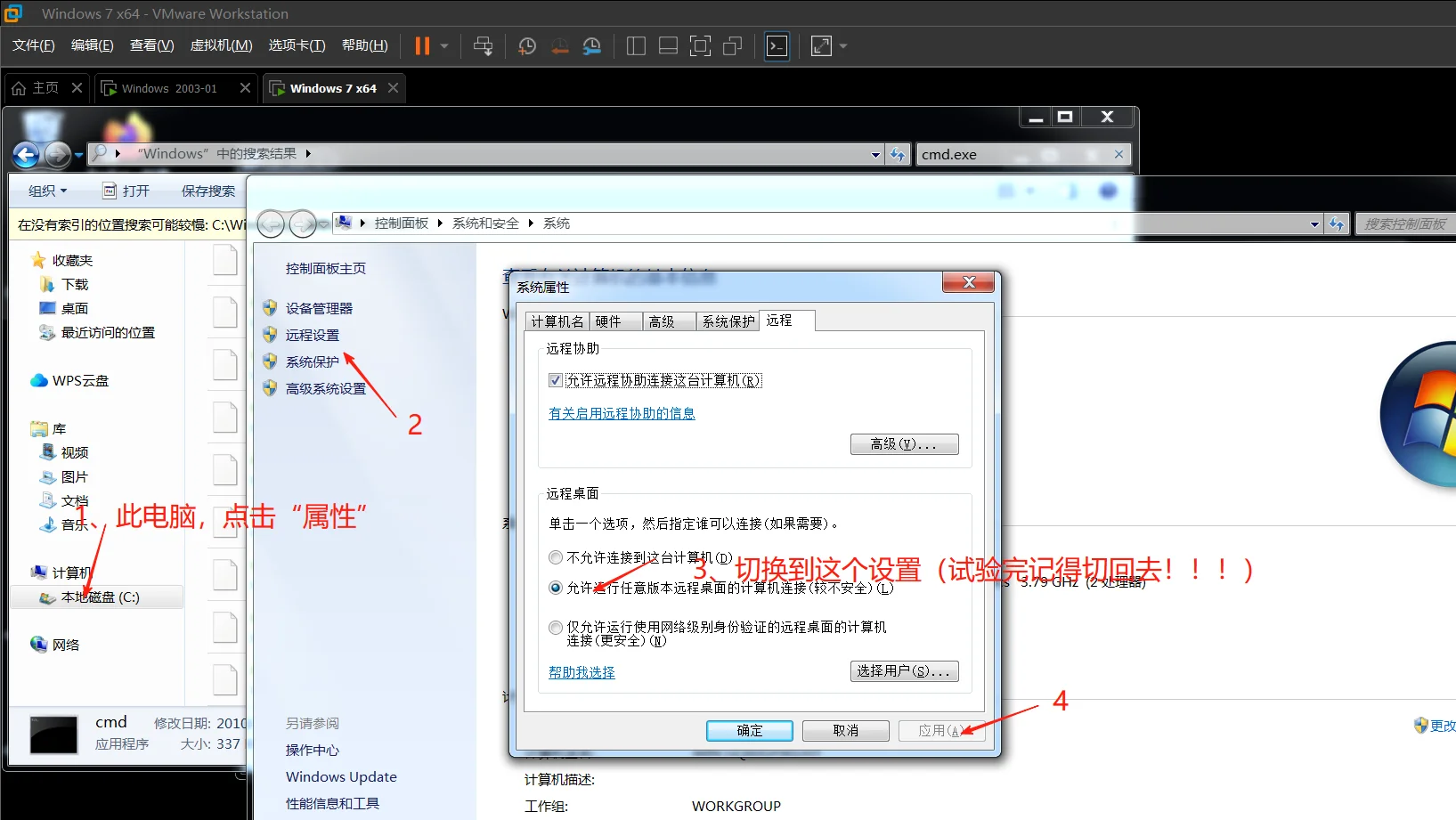
接下来使用一下RDP(有些家用版windows是没有RDP功能的,一般企业版多数有,主机没有RDP功能的就下两台虚拟机来实操一下咯)(指令在上文):
1、准备一或二台虚拟机win用来远程连接,可以下载两台虚拟机,win7和win 2003,我这里用主机和win7好看些。
2、虚拟机/主机需要开启远程服务。
3、防火墙要允许远程服务通过。
4、创建一个用户用来远程登录,当然用本身用户也可以。
5、在本地安全策略里的用户权限分配要将新建的用户加进去;在计算机管理里面的组里面的Administrators或者users里面添加刚刚新建的用户。
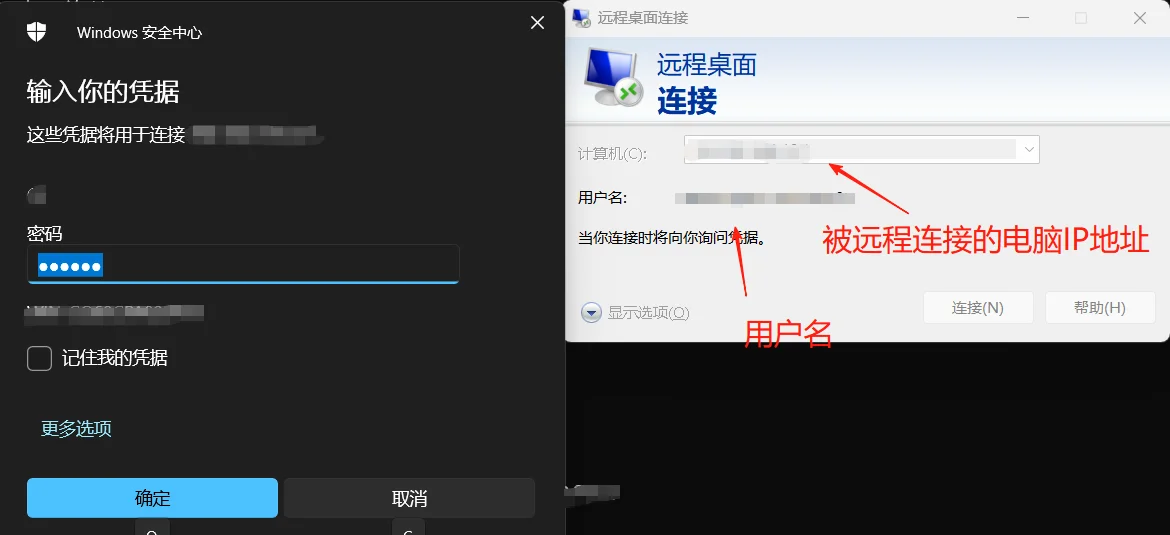
6、另外开启一台虚拟机win二号要在开始菜单搜索远程桌面连接输入win1号的IP地址进行连接(相反连接也行),在输入刚刚新建的用户信息即可。
前提 :两台机子要相互ping通
我这里用win7和win2003、自己的win11来进行实验。
Linux系统
林纳斯·本纳第克特·托瓦兹——linux之父概况著名的电脑程序员、黑客。Linux内核的发明人及该计划的合作者。托瓦兹利用个人时间及器材创造出了这套当今全球最流行的操作系统(作业系统)内核之一。
Kali、Ubuntu、Dibian、CentOS下载,主要用Kali(关于Kali下载的问题汇总) ,Kali也是贯穿网安行业的的一部虚拟机,里面打包了几百种工具,有渗透、运维、蓝红队工具、甚至可以扩展到CTF所用到的基于Linux的python脚本等,而且还有不错的扩展性,可以按照自己的需要去额外加装脚本、软件、工具等。
Debian:由志愿者开发的发行Linux的非商业项目。
Ubuntu:Debian项目构建的一个Linux发行版,专注于提供用户友好的桌面和服务器操作系统。
Kali:基于Debian的Linux发行版,预装了许多安全工具。
RedHat:红帽公司,产品包括RHEL、Fedora Core与CentOS。
CentOS:RHEL依照开放源代码规定释出的源码所编译而成。
开源
Linux是一个开源操作系统,源代码对用户开放,使用户可以自由获取、使用和修改。
稳定
Linux以其出色的稳定性而闻名。在大量的服务器应用中,稳定性是至关重要的因素。
安全
Linux具有良好的安全性。由于其开源性,Linux操作系统可以由全球的开发者社区进行审查和修复漏洞。这使得Linux具备快速响应和更新的能力,以应对不断变化的安全威胁。此外,Linux提供了强大的权限管理和安全工具,帮助管理员保护服务器免受潜在的威胁。
发行版是指基于开源软件的操作系统的特定版本,经过整合、配置和打包后向用户发布的软件发行形式。它是将开源软件进行定制化和优化的结果,以便用户能够更方便地使用和管理操作系统。
环境部署
Linux系统环境搭建
Linux常见分系统
Debian/ReaHat
Ubuntu/CentOS
Kali(渗透真神)
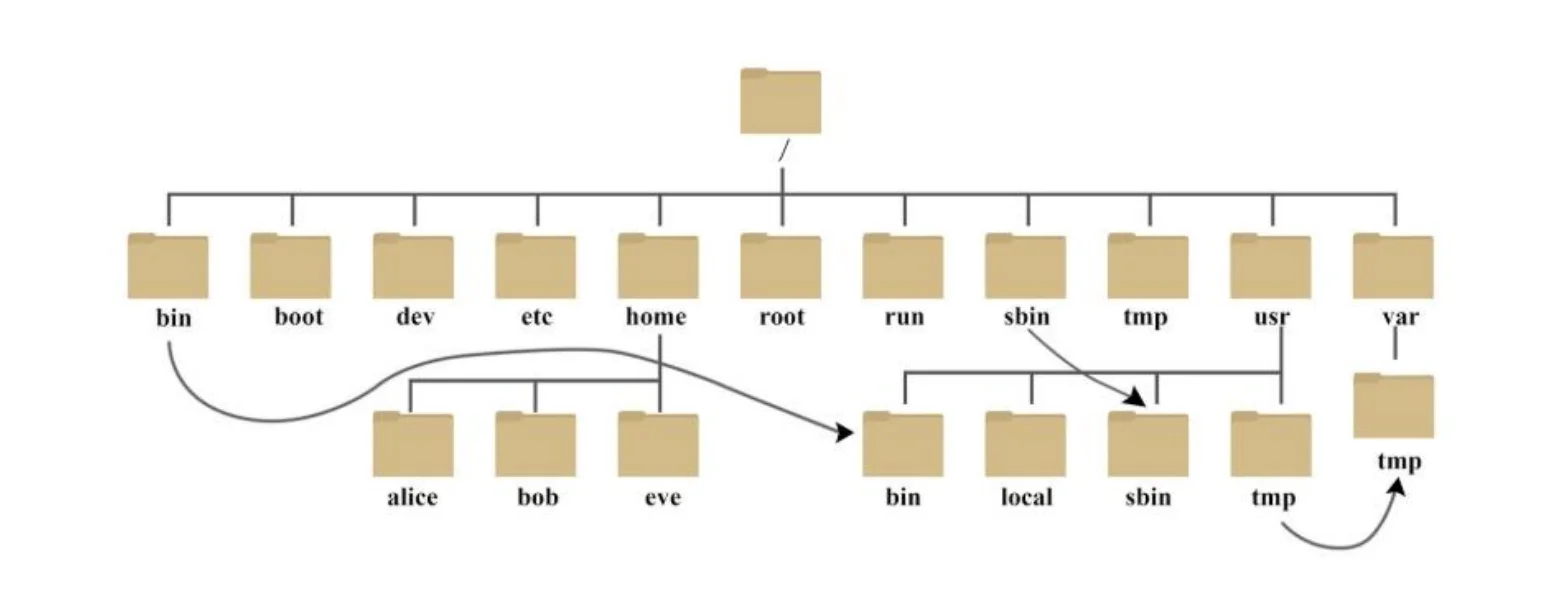
Linux文件与目录管理
系统目录与重要系统文件
文件管理
touch 文件名 :创建文件
mkdir 目录名:创建目录 make dir
mkdir -p a/b : 同时创建父子目录
cp:复制文件或目录copy
mv:移动文件或目录move
rm 文件或目录 :删除文件或目录remove
rm -rf 文件夹 :删除非空目录
cat查看文件内容
head查看文件头部内容
tail查看文件尾部内容
grep根据匹配规则搜索(查找文件内容)
grep -c "root" /etc/passwd
find按照条件查找文件
find /etc -name "network*"
pwd:查看当前所在文件位置
cd :切换目录 (后面接绝对路径或相对路径)
ls :以平铺方式显示当前目录包含内容
ls -a :查看隐藏文件
ls -l :以详细列表形式显示当前目录包含内容
ls:列出当前目录下文件
ll/ls -l:列出当前目录下文件(详细)
命令行通配符
*匹配0-多个字符
? 匹配单个字符
[a-z] 匹配 a - z 之间的一个
[0-9]
touch 文件名 :创建文件
mkdir 目录名:创建目录 make dir
mkdir -p a/b : 同时创建父子目录
cp:复制文件或目录copy
mv:移动文件或目录move
rm 文件或目录 :删除文件或目录remove
rm -rf 文件夹 :删除非空目录
Linux用户管理
用户与用户组配置详解
用户(User)
用户账户:每个使用Linux系统的个体或进程都需要一个用户账户。用户账户包含了用户的信息,如用户名、用户ID(UID)、用户组、家目录、默认Shell等。
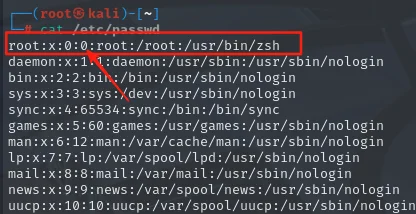
UID(User ID):每个用户都有一个唯一的数字标识符,称为用户ID(UID)。UID为0的用户是超级用户(root),拥有系统上的所有权限。
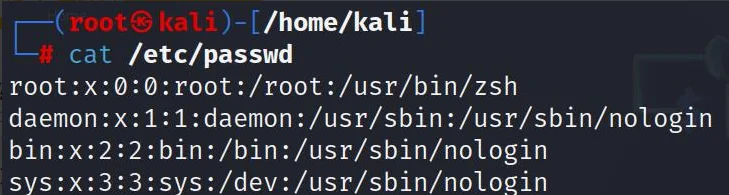
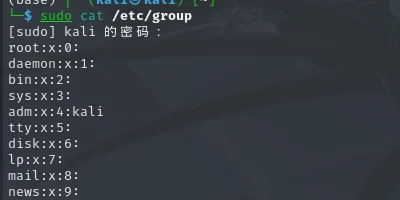
root--系统管理员用户信息文件:/etc/passwd文件包含了系统上所有用户的信息。每一行代表一个用户,包括用户名、UID、组ID(GID)、用户全名或描述、家目录、默认Shell等信息。
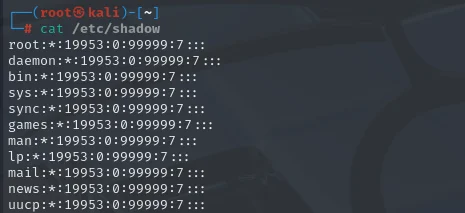
用户密码文件:用户的密码信息不直接存储在/etc/passwd文件中,而是存储在/etc/shadow文件中。该文件包含了加密后的密码、密码最后一次更改的日期、密码的最小和最大有效期等信息。
用户常用命令
查看当前用户:whoami
查看当前用户详细信息:id
查看所有用户:cat /etc/passwd(可以看到root的UID为0,是超级用户的特征)
查看用户数据信息:cat /etc/shadow
那么用:来分隔的每段字符串是什么意思?kali:用户名。
$y$j9T$zY1oKFxJlTgP2WcJhzbNl1$xhkUmB8R9fzETc/1kgL/nOPcWFTvhn17clxXCgyFjpC:加密后的密码。采用的是带有 salt(盐值)的哈希加密方式,$y$ 等符号是标识加密算法等相关信息,这样的加密能增强密码安全性,防止彩虹表攻击。
19953:最后一次修改密码的日期,是从 1970 年 1 月 1 日起算的天数。
0:密码最小修改间隔天数,这里为 0 表示可以随时修改密码。
99999:密码有效期天数,即从最后一次修改密码后,经过这么多天密码就会过期需要修改。
7:密码过期前提前多少天开始警告用户。
后面的空字段:分别对应密码过期后的宽限天数(密码过期后仍可登录的天数)、账户失效时间(密码过期且宽限天数过后,账户失效无法登录的日期,这里为空)、保留字段(暂无特定用途)。
这里了解下就好。
添加用户:useradd -m 用户名
删除用户:userdel 用户名
修改用户信息:usermod
配置密码:passwd 用户名
切换用户:su 用户名(不加用户名表示切换root)以系统管理者的身份执行指令:sudo 具体命令 root:最高权限组与用户
组(Group)
用户组:用户组用于将多个用户组织在一起,以便于对文件或目录的权限管理。用户可以是多个组的成员。
GID(Group ID):每个用户组都有一个唯一的数字标识符,称为组ID(GID)。
组信息文件:/etc/group文件包含了系统上所有用户组的信息。每一行代表一个组,包括组名、GID、组成员列表等信息。
用户组常用命令
查看当前用户组:groups
创建新用户组:groupadd
删除用户组:groupdel
修改用户组信息;groupmod
查看所有组:cat /etc/group
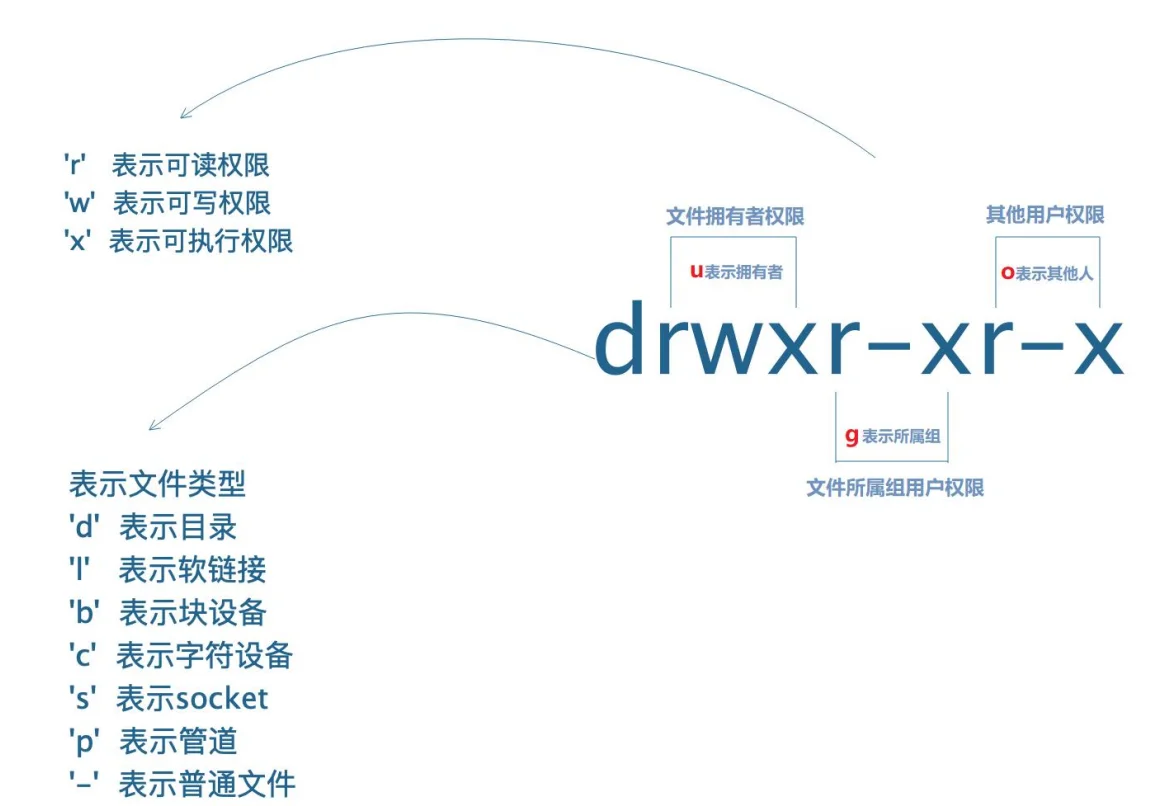
权限管理
更改文件所有者change owner
chown kali:kali test
修改为kali用户,kali组
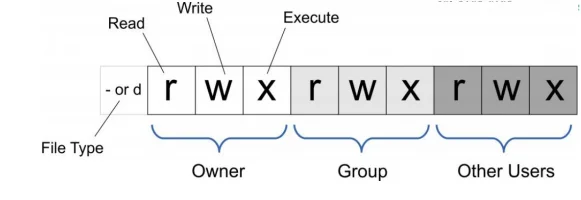
修改文件权限change mode
chmod 777 aa
给文件aa赋予rwx读、写、执行这三种权限,欸?为什么用数字代表?不是用rwx呢?这是因为:777 是权限数值,由三位数字组成,分别对应文件所有者(user)、所属组(group)、其他用户(other)的权限:数字 7 表示拥有读(r,对应数值 4)、写(w,对应数值 2)、执行(x,对应数值 1)的全部权限(4+2+1=7)。
因此 777 意味着所有者、所属组和其他用户对该文件都拥有读、写、执行的最高权限。
那比如还有chmod 635就是代表:为目标文件或目录设置上述特定权限组合(所有者 rw-、所属组 -wx、其他用户 r-x)。
chmod +x aa
chmod u+x aa
chmod g-x aa
chmod u=rwx,g=rx,o=rx 文件名
对于这个指令chmdo u=rw g=r o=rx aa,作为一个例子,意思是修改目录或文件aa,将赋予user用户有read读、write(w)权限,但没有x执行权限的权限。w在group这里省略了,代表“没有权限”;对于group组,分配read读权限,没有w和x的权限。other其他用户来说,分配read读和x执行权限。如下图所示:
在这里可以发现,像change mode、password命令一样,都是些缩写,变成chmod、passwd这样的,很多Kali命令都是会缩写的,很好记。
Linux进程与软件管理
进程概述
Linux系统进程是指在Linux操作系统中运行的每一个独立的任务或程序实例。每个进程都拥有自己的地址空间、系统资源(如文件句柄和内存)以及一个唯一的进程标识符(PID)。Linux通过进程模型实现了多任务处理和并发执行,允许同时运行多个进程。
进程查看与控制
ifconfig:获取网卡状态或网卡配置
ping:检测网络连通
这俩命令自己去试吧,我在这里保护好自己就不泄露IP啦......
当然有时候要用到IP、远程连接这样的话,难免会连接不上,那你可以试着重启,用到ifconfig <网卡比如eth0、eth1这样的> down,这样就把这个网卡关了,然后过一会就再输一次命令,把down换成up,就是开启网卡了。
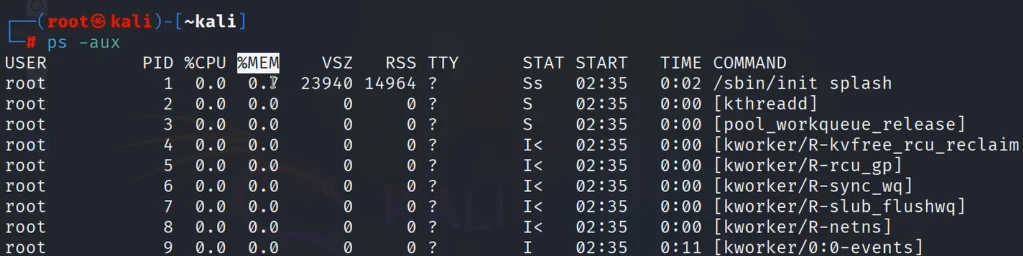
ps:显示当前终端下运行的进程
ps -aux:显示所有用户的所有进程,包括系统进程,提供更详细的进程信息.第二张图可以看到我们刚刚用了ps -aux指令的记录。
kill (PID): 终止指定PID进程
kill -9 (pid):强制终止进程(-9 对应信号编号 9,即 SIGKILL 信号,这是一种强制终止信号,具有最高优先级。
但是我比较建议你用上面的kill(PID),因为通常在进程正常终止(如 kill (PID)发送的 SIGTERM 信号)无效时,才会使用 -9 强制杀死 进程,但这种方式可能导致进程正在处理的数据丢失或资源未正常释放,因此需谨慎使用)
那有个问题来了,服务进程这么多一个个看PID查找忒麻烦啊!那可以用到pidof命令去找到你需要关闭的服务进程的pid。例如要关掉sshd远程连接服务,那我们就用pidof命令去找它的pid:
netstat -ano:显示网络状态、查端口、公私网地址、TCP、UDP等。
软件包管理(deb/rpm、apt/yum)
这里简单知道这个命令就好,基本上配了Kali虚拟机和有下载过CTF的解题工具的经验都见过这些命令:
debian
包格式:.deb
包管理器:apt
安装一个包的命令:apt install xx
这里记得要切换root用户,不然会报错,权限不足
列出所有可更新的软件清单命令:apt update
升级软件包:apt upgrade
在通过Linux进行命令行下载工具时,记得apt update一下噢
安装指定的软件命令:apt install <package_name>
删除软件包命令:apt remove <package_name>
列出所有已安装的包:apt list --installed
列出所有已安装的包版本信息:apt list --all-versions
redhat
包格式:.rpm
包管理器:yum yum install xx
安装镜像源:vim /etc/apt/sources.list(这个命令比较常用,因为Kali的下载速度比较慢的时候我都会用这个命令去换一下镜像源,阿里云、清华源等,这样速度比较快些)
Linux系统防火墙
防火墙就是根据系统管理员设定的规则来控制数据包的进出,主要是保护内网的安全。目前Linux系统的防火墙类型主要有两种:分别是iptables 和firewalld
iptables-静态防火墙
早期的Linux系统中默认使用的是iptables防火墙,配置文件在/etc/sysconfig/iptables,主要工作在网络层
iptables只可以通过命令行进行配置
iptables默认是允许所有,需要通过拒绝去做限制
iptables在修改了规则之后必须得全部刷新才可以生效,还会丢失连接(无法守护进程)
firewalld-动态防火墙
取代了之前的iptables防火墙,配置文件在/usr/lib/firewalld和/etc/fiewalld中,主要工作在网络层
firewalld不仅可以通过命令行进行配置,也可以通过图形化界面配置
firewalld默认是拒绝所有,需要通过允许去放行
firewalld可以动态修改单条规则,动态管理规则集(允许更新规则而不破环现有会话和连接,可以守护进程,会过滤内网、互联网数据,当前电脑系统都有装防火墙的。
查看firewalld防火墙状态:sudo systemctl status firewalld
查看iptables防火墙状态(如果系统使用iptables作为防火墙):sudo systemctl status iptables
基于RPM的系统安装firewalld:sudo yum install firewalld
基于Debian的系统(如Ubuntu),虽然通常不预装firewalld,但也可以使用apt命令进行安装:sudo apt install firewalld
启动firewalld服务:sudo systemctl start firewalld
关闭firewalld服务:sudo systemctl stop firewalld
开机自启动:sudo systemctl enable firewalld
禁止务开机自启动:sudo systemctl disable firewalld
shell基础与实践
shell脚本
Linux 的 Shell 种类众多,常见的有:
Bourne Shell(/usr/bin/sh或/bin/sh)
Bourne Again Shell(/bin/bash)
C Shell(/usr/bin/csh)
K Shell(/usr/bin/ksh)
Shell for Root(/sbin/sh)
由于bash 易用与免费,其被广泛使用也是大多数Linux系统的默认Shell。(Kali目前为zsh,兼容bash) /bin/bash
/bin/bash这个shell适用在轻量级程序,易写好操作。
接下来拿/bin/bash这个shell举个应用例子:
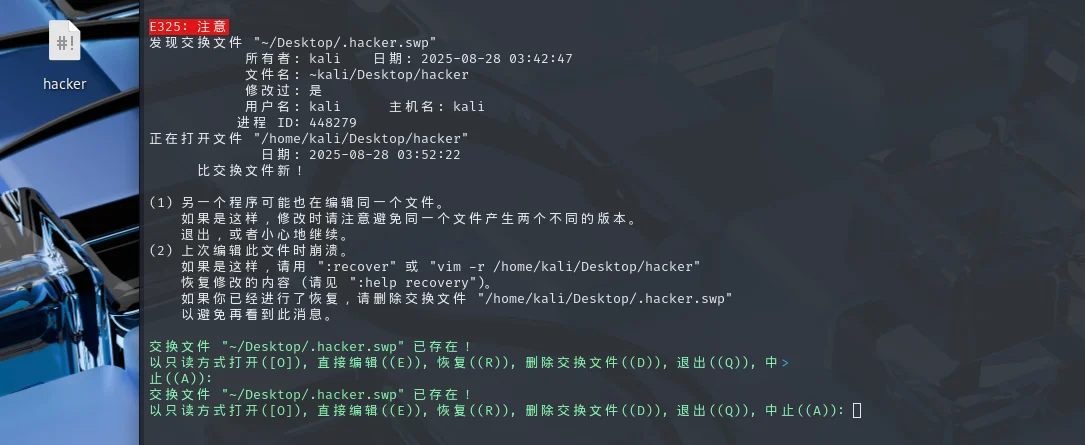
打开Kali终端,然后输入vim指令:
在 Kali Linux 中,vim 是一个命令行文本编辑器 的启动指令,用于创建、打开和编辑文本文件(如配置文件、脚本、代码等)。当然也是用它来编shell脚本的。
一开始先点击i 键,进入编辑模式,然后再顶行输入# 和! ,接着输入/bin/bash
按回车下一行这里我们以简单的echo指令去运行shell,echo类似输出函数print的效果。
输入好shell后就按Esc 键,退出编辑模式,此时输出双引号: ,再输入wq+回车保存就好了,然后就自动退出vim模式了,回到命令行界面了,这是这个shell脚本就会保存到相应的路径了,我们可以运行的,
接下来我们运行一下:
用ll命令去看看权限:
这里我之前有提到过:该文件权限为 -rw-rw-r--(所有者和所属组有读写权限,其他用户有读权限)
可以直接用chmod 777 hacker去给这文件提权。
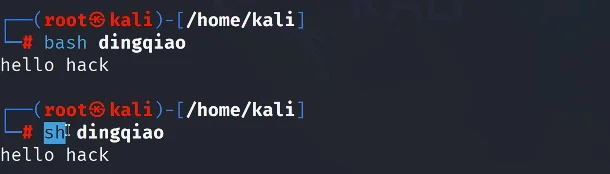
这里提一下:每个用户其实都有默认的shell的,向上面所讲的那几种的其中之一,如果我们在vim编辑时不声明是用/bin/bash的话就会用用户本身自带的shell,现在可以用echo $SHELL查看一下:
可以看到不是/bin/bash而是/usr/bin/zsh,也就是说如果你当时在vim编辑中不写明是#!/bin/bash的话,就会默认用zsh去运行那段代码“echo "hello hacke!!!!!!r"”
那我觉得好麻烦啊!!!!!!先vim敲代码然后还要chmod给文件执行提权....
这里有个简单方法:
这样子的话就是强制执行了,bash、sh这种是默认带x执行权限的,bash就是用/bin/bash去执行里头的代码,那sh就是用另外一种不同的去执行里头的代码.....
Shell的展示就到这里,感兴趣的可以细学,不过我学完C、Python感觉学不下shell了哈哈😄.....
Xshell
Xshell 是一款功能强大的终端模拟器,它支持SSH、SERIAL等多种协议,可以用于远程连接和管理服务器或虚拟机。在我们以后工作可以用Xshell去连接公司的服务器。( Xftp 快速传输工具)
当然习惯用winscp、todesk、电脑自带的RDP这些的话也行。
连接时记得打开SSH,网络要能ping通....
Xshell、Xftp怎么用我不介绍了,搜一搜有教程。
九头蛇-ssh弱口令爆破实战
介绍:Hydra是一款强大的网络登录破解工具,可以用于测试SSH等服务的弱口令。Hydra是一个开源的密码破解工具,主要用于网络安全的渗透测试 。kali白带无需安装。
使用语法---- hydra 参数IP地址 服务名
常见命令:
hydra [-l 用户名或者-L 用户名文件路径]
[-p密码 或者-Р密码文件路径]
[-t线程数]默认16
[-vV 显示详细信息]
[-o 输出文件路径
[-f找到密码就停止]
[-e ns 空密码和指定密码试探]
[ip |-M ip列表文件路径]
这里给大家这些命令,关于详细用法在后续,下一阶段将和burpsuite细讲......
法律问题:未经授权对系统进行密码破解是违法行为,仅可在自己拥有或获得明确许可的系统上使用。
网络安全基础
计算机网络保姆级资料
计算机网络
计算机网络基础
计算机网络是一组自治计算机互连的集合;
一个完整的计算机网络系统主要由硬件、软件和协议三大部分组成,缺一不可。
计算机网络网络的基本功能
• 资源共享;
• 分布式处理与负载均衡;
• 综合信息服务;
协议:实现通信所需要的一些约定,为使网内各计算机之间的通信可靠有效,通信双方必须共同遵守的规则和约定称为通信协议。
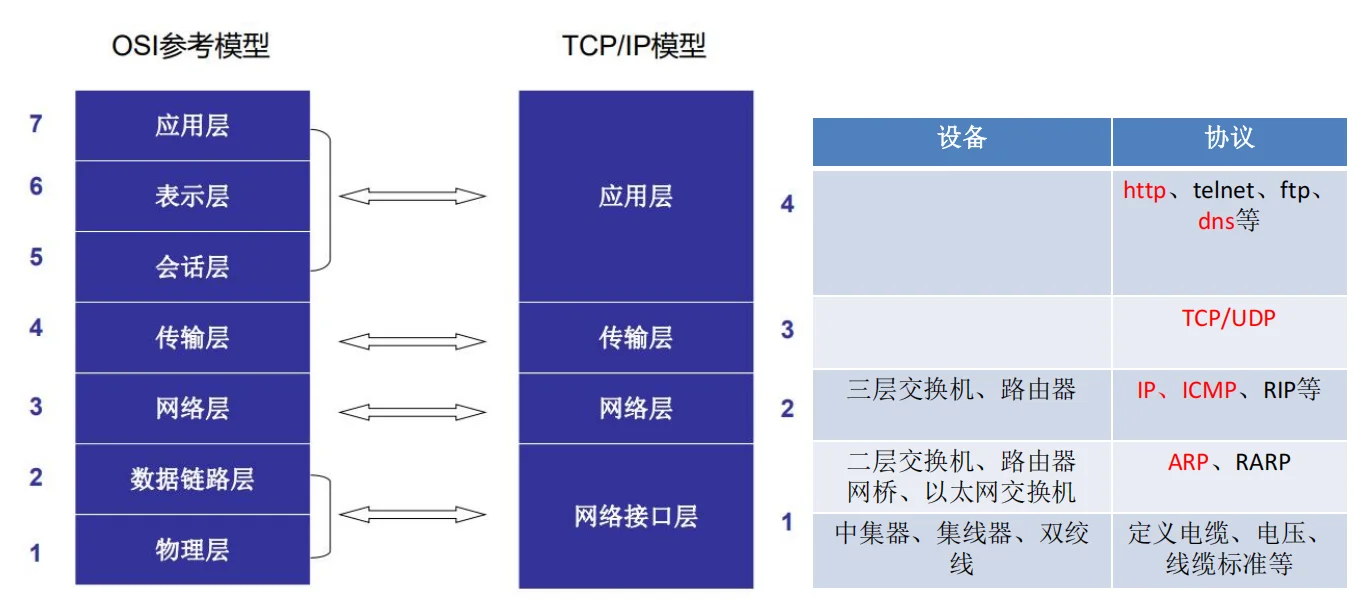
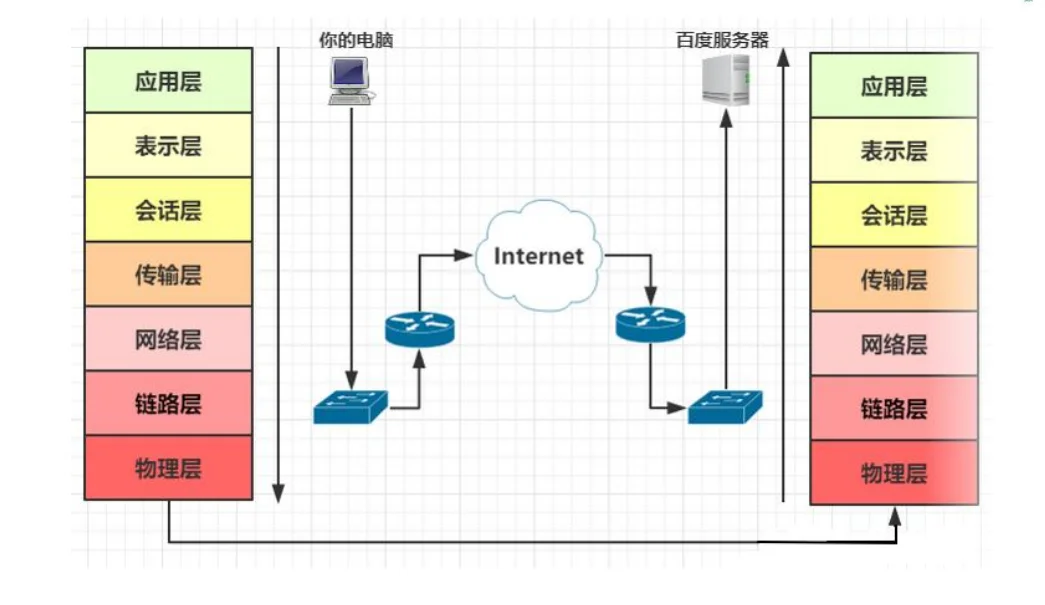
伴随着计算机网络的飞跃发展,各大厂商根据自己的协议生产出了不同的硬件和软件。为了实现网络设备间的互相通讯,ISO和IEEE相继提出了OSI参考模型及其TCP/IP模型。
层次模型:计算机网络是一个非常复杂的系统,分层可以将庞大而复杂的问题,转化为若干较小的局部问题,而这些较小的局部问题就比较易于研究和处理。
OSI与TCP、IP网络模型
OSI参考模型定义了网络中设备所遵守的层次结构
分层结构的优点:开放的标准化接口;多厂商兼容;易于理解、学习和更新协议标准;实现模块化工程,降低了开发实现的复杂度;便于故障排除。
TCP/UDP--传输层
TCP工作机制:三次握手建立连接,四次挥手断开连接。
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的。
UDP协议:
用户数据报协议,无连接的、不可靠的、基于数据报的传输层通信协议。
用于数据传输控制的协议,对数据的可靠性、安全没有保证,不需要连接就可以发送。
总结:
tcp是面向连接的,udp是面向无连接
tcp的报文的结构相对要比udp更复杂
tcp是基于字节流(0、1),udp是基于数据报
tcp会保证数据的正确性、udp不能,会存在丢包的现象
交换机与路由器
交换机 :
交换机按照通信两端传输信息的需要,用人工或设备自动完成的方法,把要传输的信息送到符合要求的相应路由上的技术统称。它能够为接入交换机的任意两个网络节点提供独享的电信号通路。
交换机的工作方式 :
数据包转发
交换机接收到数据包后,会依据数据包中的目的 MAC 地址来决定将数据包转发到哪个端口。具体过程是,交换机查询自身的 MAC 地址表 ,如果目的 MAC 地址在表中有对应的端口记录,就将数据包转发到该端口;若 MAC 地址表中没有匹配的记录,交换机则会采用泛洪的方式,将数据包转发到除接收端口外的其他所有端口 。例如,在一个办公室网络中,当某台计算机 A 向计算机 B 发送数据时,交换机先查找 MAC 地址表,若找到计算机 B 对应的端口,就把数据包精准发到该端口;若没找到,就会把数据包发到其他所有连接设备的端口,直到计算机 B 接收到并做出回应,交换机也就学习到了计算机 B 的 MAC 地址和对应端口。
MAC 地址学习
交换机刚启动时,MAC 地址表是空的。在工作过程中,它会学习连接到各个端口设备的 MAC 地址。当交换机从某个端口接收到一个数据包时,它会记录下数据包源 MAC 地址与该接收端口的对应关系,并将其添加到 MAC 地址表中 。随着时间推移,交换机通过不断接收来自不同设备的数据包,逐渐建立起完整的 MAC 地址表。比如,新接入网络的打印机发送了一个数据包,交换机就会记录下打印机的 MAC 地址和它所连接的端口,下次再有发往该打印机的数据,就能直接转发。
高速数据传输
交换机内部采用了并行处理技术,能够同时处理多个端口之间的数据传输,具备很高的数据传输速率。交换机为每个端口提供独立的带宽,端口之间的数据传输可以并行进行,不会产生冲突,这大大提高了网络的整体性能 。比如在一个有 24 个端口的百兆以太网交换机中,每个端口都可以提供 100Mbps 的带宽,不同端口之间的数据传输可以同时进行,极大地提升了数据传输效率,满足了网络中大量设备同时高速传输数据的需求。
路由器 :
路由器是一种用于连接多个逻辑上分开的网络的
设备,它能够在多网络互联环境中建立灵活的连接,
实现不同网络之间的数据传输
路由决策
路由决策是路由器 “判断走哪条路转发数据” 的过程,核心是依据路由表选择最优路径 ,避免数据绕远路或走拥堵的路。
数据包转发
路由器的核心作用是将数据包从一个网络转发到另一个网络 (比如把家里的局域网数据转发到互联网,或把 A 公司的网络数据转发到 B 公司的网络),关键依赖 “IP 地址” 而非交换机的 “MAC 地址”。
网络安全
路由器自带基础的安全功能,能阻挡非法访问、保护内部网络,常见手段包括:
防火墙功能 :
可配置 “访问控制规则”,比如禁止外部网络直接访问内部的服务器(只允许内部主动访问外部),或限制特定 IP / 端口的访问(比如禁止家里的设备访问危险端口 22、3389)。
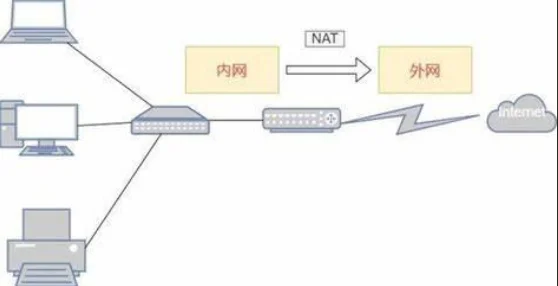
NAT 地址转换 :
把内部的 “私有 IP”(如 192.168.1.x、10.0.0.x)转换成 “公网 IP”,外部网络只能看到公网 IP,无法直接访问内部的私有 IP 设备,相当于给内部网络加了一层 “隐藏保护”。
DHCP 地址过滤 :
只给指定 MAC 地址的设备分配 IP(比如只允许家里的手机、电脑连网,陌生设备即使连了 WiFi 也拿不到 IP,无法访问网络)。
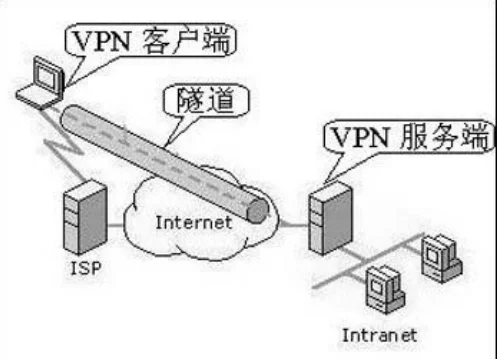
VPN 功能 :
企业中常用,员工在外网(比如咖啡厅 WiFi)可通过 “VPN 连接” 加密访问公司内部网络,防止数据被窃取。
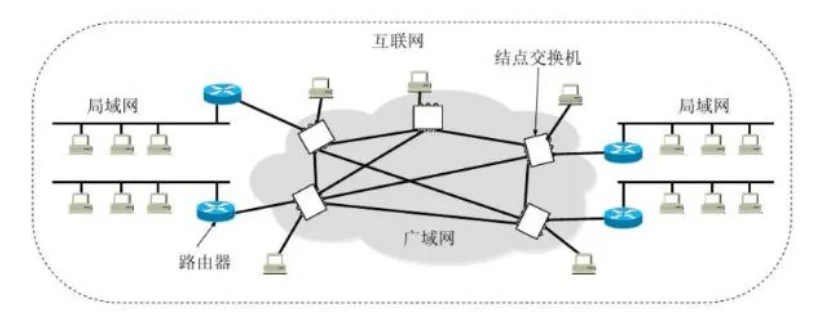
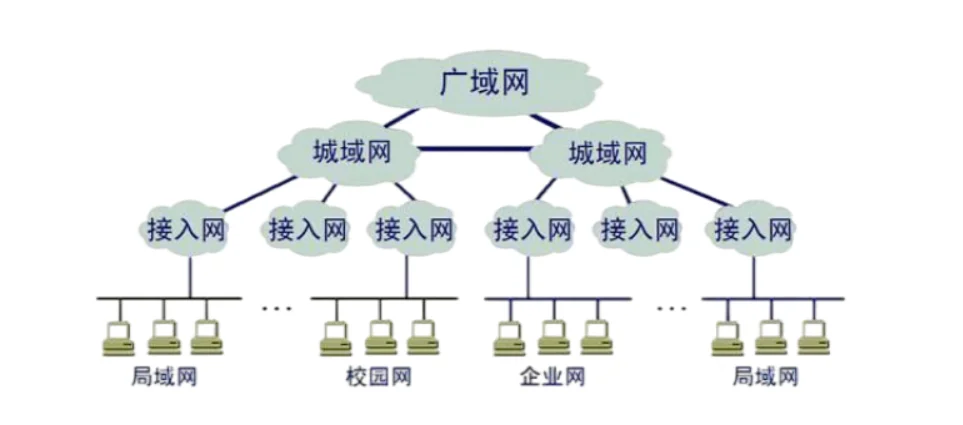
网络分类
按照覆盖范围分类
○局域网(LAN):局限于较小的地理范围内,如家庭、学校或公司内部的网络。
○城域网(MAN):覆盖范围比局域网大,通常覆盖一个城市或地区。
○广域网(WAN):覆盖范围广泛,可以跨越多个城市、国家或地区,甚至全球。
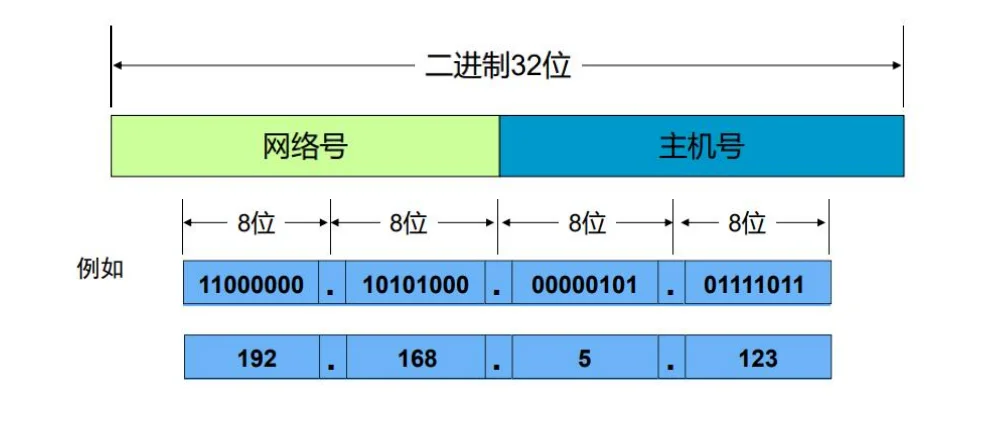
IP地址--网络层
IP地址是电子设备(计算机)在互联网上的唯一标识。IP地址分为IPv4和IPv6。IPv4地址由32位二进制组成,采用点分十进制。
IP主要作用
标识节点和链路:用唯一的IP地址标识每一个节点;用唯一的IP网络号标识每一个链路。
寻址和转发:确定节点所在网络的位置,进而确定节点所在的位置;IP路由器选择适当的路径将IP包转发到目的节点。
IP地址格式表示方法
IP地址由网络号(包括子网号)和主机号两部分组成。网络位相同的IP地址为同一网段。
网络号 用于区分不同的IP网络。
主机号 用于标识该网络内的一个IP节点。
IP地址分类
IPv4地址分为A、B、C、D、E 五类,每一类有不同的划分规则:
一、A 类地址:面向大型网络的 “骨干级” 地址
核心特征 :
最高位固定为 “0”,地址结构是「1 字节网络位 + 3 字节主机位」(比如10.0.0.0,前 8 位是网络位,后 24 位是主机位)。关键补充:
地址范围中,1.0.0.0 ~ 126.255.255.255 是合法可用地址,127.0.0.0/8 网段(不止127.0.0.1)均为 “回环地址”,用于本地测试(比如ping 127.0.0.2也能检测本机网络协议栈是否正常)。
每个网络可容纳 2²⁴ - 2 = 16777214 个主机(减 2 是因为 “网络地址” 如10.0.0.0和 “广播地址” 如10.255.255.255不能分配给主机)。
典型场景 :早期用于大型企业、运营商骨干网络(比如某省的电信核心网络可能用一个 A 类地址段)。
二、B 类地址:适配中型网络的 “区域级” 地址
核心特征 :
最高两位固定为 “10”,地址结构是「2 字节网络位 + 2 字节主机位」(比如172.16.0.0,前 16 位是网络位,后 16 位是主机位)。关键补充:
可容纳 2¹⁶ - 2 = 65534 个主机,适合中型园区、高校或集团公司(比如一所大学的校园网可能用一个 B 类地址段,覆盖所有教学楼、宿舍的设备)。
私有 B 类地址段:172.16.0.0 ~ 172.31.255.255(共 16 个网段),常用于企业内部局域网,不对外网路由。
典型场景 :中型企业、高校校园网、城市级政务内网。
三、C 类地址:服务小型网络的 “终端级” 地址
核心特征 :
最高三位固定为 “110”,地址结构是「3 字节网络位 + 1 字节主机位」(比如192.168.1.0,前 24 位是网络位,后 8 位是主机位)。关键补充:
每个网络仅能容纳 2⁸ - 2 = 254 个主机,适合小型办公室、家庭局域网(比如家里的路由器默认用192.168.1.0/24,最多连 254 台设备)。
私有 C 类地址段:192.168.0.0 ~ 192.168.255.255(共 256 个网段),是最常用的内网地址(路由器、摄像头、智能家居设备基本都用这类地址)。
典型场景 :家庭 WiFi、小型公司、商铺的局域网。
四、D 类地址:专注 “一对多” 的组播地址
核心特征 :
最高四位固定为 “1110”,地址范围是224.0.0.0 ~ 239.255.255.255,没有网络位和主机位之分 ,直接代表一个 “组播组”。关键补充:
不是给单个设备分配,而是给一组设备 “共同订阅”(比如设备加入224.0.0.1组播组,就能接收发给这个组的所有数据)。
常见用途:视频会议(多人同时接收同一视频流,避免重复发送浪费带宽)、安防监控(多个监控屏幕接收同一摄像头的画面)、IPTV(机顶盒接收电视台的组播信号)。
特殊地址 :224.0.0.1是 “所有主机组播地址”(同一网段内所有设备都能接收),224.0.0.5是 OSPF 路由协议专用组播地址。
五、E 类地址:预留的 “科研级” 地址
核心特征 :
最高四位固定为 “1111”,地址范围是240.0.0.0 ~ 255.255.255.255,目前没有公开商用 ,仅用于科研实验、协议测试(比如未来可能的 IPv4 扩展技术研发)。注意 :255.255.255.255是 “全局广播地址”,不属于 E 类的常规用途,发送到这个地址的数据会被同一网段所有设备接收(比如路由器的 DHCP 广播)。
内网与外网
公网地址是由互联网注册机构进行分配的,这些地址在Internet上是唯一的,并且具有全球可达性。公网地址用于Internet上的设备,允许设备在Internet上进行通信。
私网地址则是由局域网管理员自行分配的,它们只在局域网内部具有唯一性。私网地址则仅限于局域网内部使用,不能直接在Internet上访问。这种设计有助于保护内部网络的安全性,防止内部网络与公共网络之间的冲突。
子网掩码:用来确定IP地址的网络位,网络号的位都置1,主机号都置0。
内网(局域网,LAN)
定义:内网是指在某一特定区域内由多台计算机以及网络设备构成的网络,如校园网、政府网、企业内网等。
范围:内网的覆盖范围相对较小,通常仅限于某一建筑物、园区或公司内部,方圆几公里以内。
外网(广域网,WAN)
定义:外网又称广域网、公网,是连接不同地区局域网或城域网计算机通信的远程网。
范围:外网的覆盖范围广泛,可以跨越城市、国家甚至全球,提供远距离通信服务。
虚拟专用网络((Virtual Private Network,VPN))
定义:是指依靠ISP或其他NSP在公用网络基础设施之上构建的专用的安全数据通信网络,只不过这个专线网络是逻辑上的而不是物理的,所以称为虚拟专用网。
虚拟:用户不再需要拥有实际的长途数据线路,而是使用公共网络资源建立自己的私有网络。
专用:虚拟出来的网络并非任何连接在公共网络上的用户都能使用,只有经过授权的用户才可以使用。
常见名词
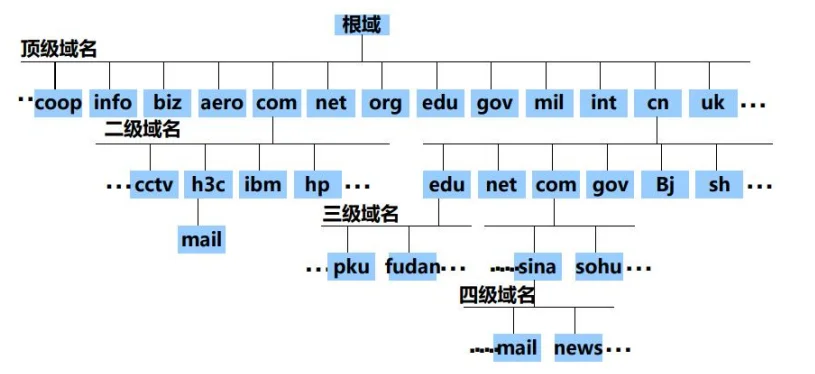
DNS-域名 :由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称
常见的域名有www.baidu.com , www.taobao.com , www.jd.com 这些都是域名。
域名可以在Godaddy、Gandi、Hover、Namesilo、Namecheap等网站注册。
域名由两个或两个以上的词构成,中间由点号分隔开。最右边的那个词称为顶级域名。
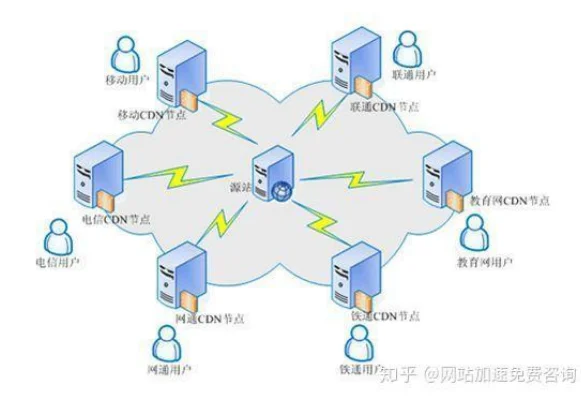
CDN(Content DeliveryNetwork)
即内容分发网络,CDN的基本思路:是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
代理
代理也称网络代理,是一种特殊的网络服务。它允许客户端通过这个服务与服务器进行连接。简单的来说,可以把代理理解为一种网络中间商。
网络协议安全
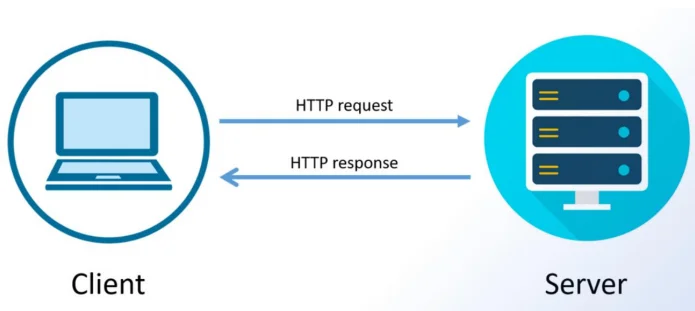
HTTP协议(Hyper Text Transfer Protocol)
它是从WEB服务器传输超文本标记语言(HTML)到本地浏览器的超文本传输协议。
建立连接 :客户端与服务器之间建立连接。
发送请求 :客户端向服务器发送请求,请求中包含要访问的资源。
处理请求 :服务器接收到请求后,根据请求中的信息找到相应的资源,执行相应的处理操作。
发送响应 :服务器将处理后的结果封装在响应中,并将其发送回客户端。
关闭连接 :在完成请求-响应周期后,客户端和服务器之间 的连接可以被关闭。
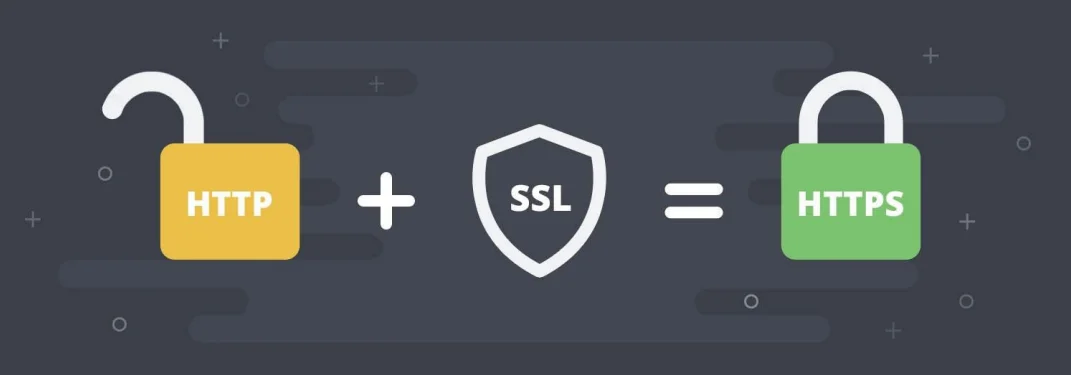
HTTPS 协议HyperText Transfer Protocol Secure
是(超文本传输安全协议)的缩写,是一种通过计算机网络进行安全通信的传输协议。
HTTPS 的主要作用是在不安全的网络上创建一个安全信道,并可在使用适当的加密包和服务器证书可被验证且可被信任时,对窃听和中间人攻击提供合理的防护。
关于SSL证书,这个地方可以用我的博客去进做例子:
Expl0rer.Ct1号
Expl0rer.Ct2号
你可以看看1号和2号的区别😄(温馨提醒:打开网站后看左上角)
http、https
GET:请求从服务器获取指定资源。这是最常用的方法,用于访问页面。
POST:请求服务器接受并处理请求体中的数据,通常用于表单提交。
PUT:请求服务器存储一个资源,并用请求体中的内容替换目标资源的所有内容。
DELETE:请求服务器删除指定的资源。
HEAD:与 GET 类似,但不获取资源的内容,只获取响应头信息
HTTP **响应头信息:**https://expl0rer.top/
wireshark与Tcpdump
Wireshark 是一款开源抓包工具,也被称为网络嗅探器,用于分析网络流量和数据包。适用于Windows环境,也支持其他操作系统。当然它也是CTF流量分析中的常用工具。
Tcpdump 是一个命令行格式的网络抓包工具,用于捕获和分析网络数据包。适用于Linux环境,是类UNIX系统下用于网络分析和问题排查的首选工具。
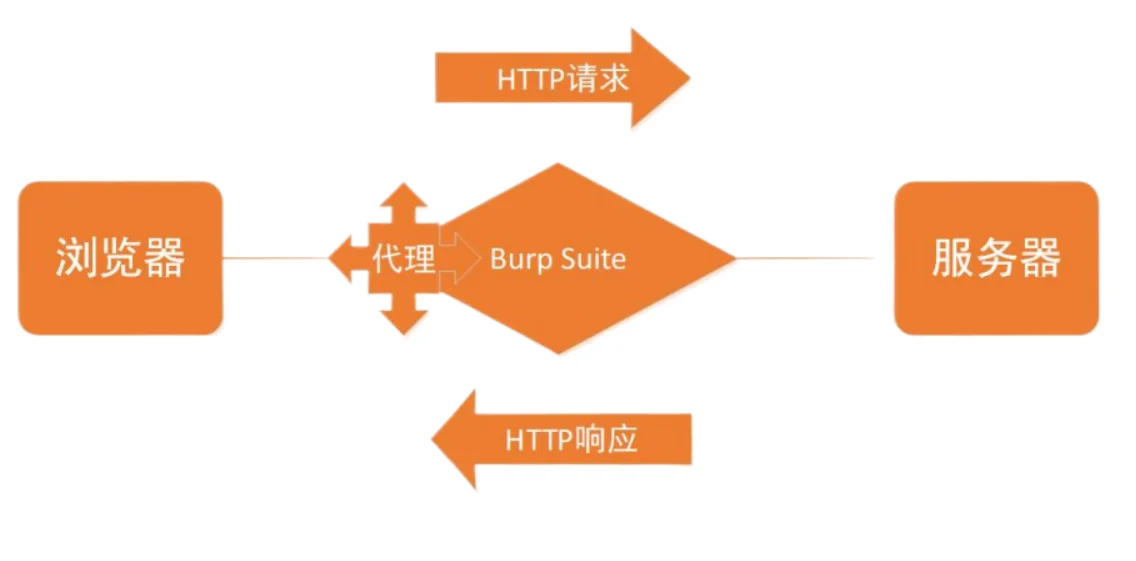
Burpsuite工具
BurpSuite是一款集成化的渗透测试 工具,它包含了许多功能,可以帮助安全人员快速完成对web应用程序的渗透测试和攻击。
网上有众多的破解版,可以自己去“0元购”......
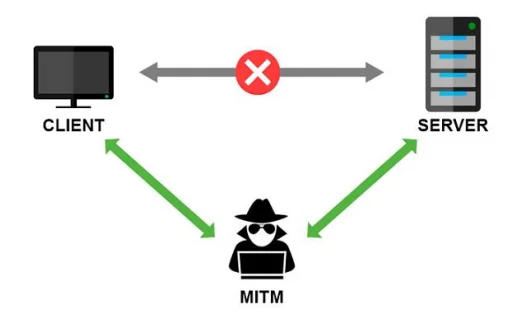
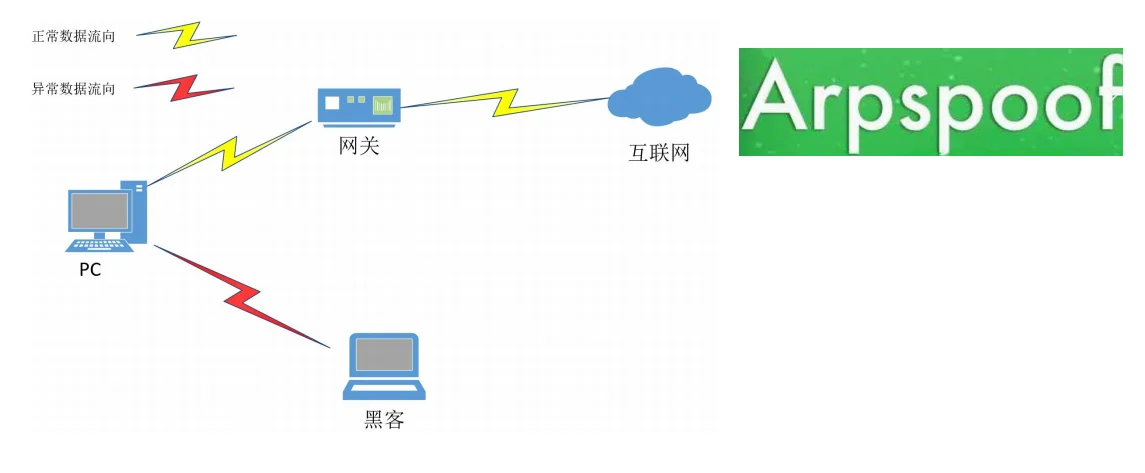
MITM中间人攻击
MITM(Man-in-the-Middle)中间人攻击是一种网络攻击方式,攻击者通过某种手段将自己插入到通信双方之间,窃取、篡改或者干扰双方的通信内容
MITM攻击的基本原理是攻击者通过各种技术手段(如ARP欺骗、DNS劫持、Wi-Fi劫持、IP欺骗、SSL/TLS欺骗等),将一台计算机虚拟放置在网络连接中的两台通信计算机之间,这台计算机就称为“中间人”。在这个过程中,攻击者可以截取、查看、篡改、伪造或修改受害者之间的通信数据,以达到窃取敏感信息、篡改数据或实施其他恶意行为的目的。
ARP欺诈攻击
ARP攻击就是通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量,攻击者只要持续不断的发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。
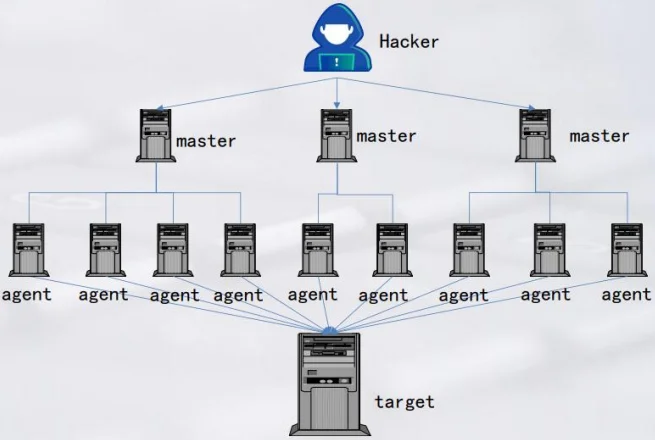
僵尸网络与DDos攻击
僵尸网络
僵尸网络是由黑客集中控制的一群互联网上的计算机。黑客通过各种手段将大量的主机感染僵尸程序,从而在控制者和被感染主机之间形成一对多的控制僵尸网络。
僵尸网络是一个可控制的网络,由黑客进行控制。这个网络是采用了一定的恶意传播手段形成的;可以一对多的执行相同的恶意命令,因为数量庞大,一个人无法单独。
DDos攻击
DDoS攻击(分布式拒绝服务攻击)是一种常见的网络攻击方式,旨在使目标服务器无法正常提供服务,在DDoS攻击中,攻击者会控制大量的计算机或设备,向目标服务器发送大量的请求,使其超出承受范围,导致服务器无法正常响应请求,从而使服务不可用。
一种常见的DDoS攻击方式是DNS Request Flood攻击。这种攻击既可以针对DNS缓存服务器,又可以针对DNS授权服务器。攻击者通过直接或间接向DNS服务器发送大量不存在的域名解析请求,导致服务器严重超载,无法继续响应正常用户的DNS请求。这种攻击会导致DNS服务器瘫痪,影响正常业务的进行。
Web安全基础
Web基础
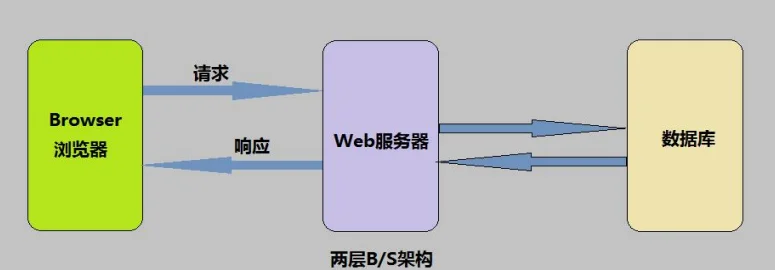
Web(万维网)的组成构建主要包括以下几个核心部分:客户端(前端)、服务器(后端)、数据库
Web服务器 :
也称为网站服务器,是指驻留于因特网上某种类型计算机的程序。它可以处理浏览器等Web客户端的请求并返回相应响应,也可以放置网站文件,让全世界浏览;还可以放置数据文件,供全世界下载。
Web开发框架是一种开发框架,用于支持动态网站、网络应用和网络服务的开发。它提供了一套标准化的方法,使得开发人员可以更加高效地进行Web应用程序的开发。
作用:Web开发框架是一种提供开发者工具和功能的软件框架,用于简化和加速Web应用程序的开发过程、提高开发效率、简化开发流程、增强安全性、提高丰富的功能和工具、促进团队协作及代码复用。
前端框架:Angular、react、vue.js
简介:由Google开发并维护的一个全面的前端开发平台,主要用于构建动态Web应用程序
后端框架:
Yii、python、php、java
简介:基于PHP的高性能Web开发框架。
Web结构
Web访问流程
Web前端
本章前端对于网安人来说学习要求不高,能基本读懂代码知道代码大概意思以及前端语言的结构样式就好。
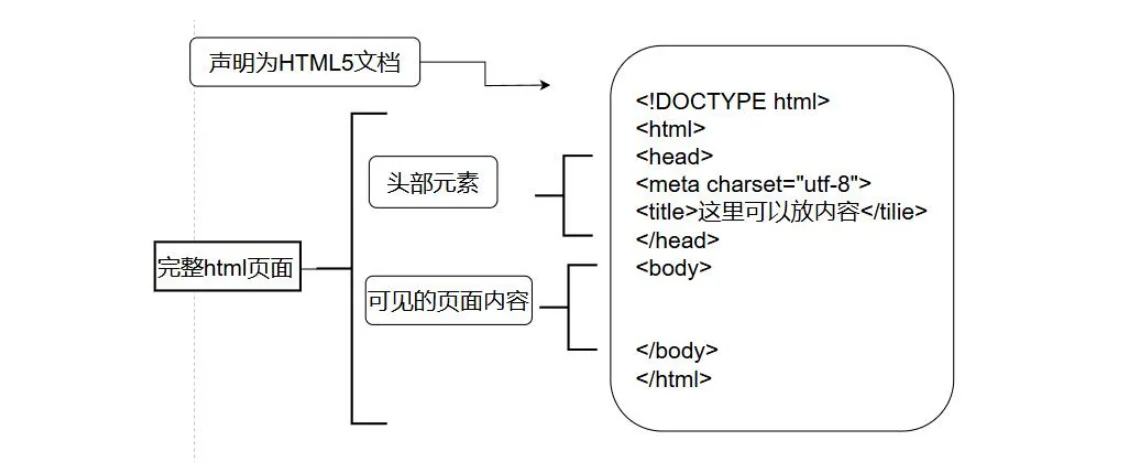
HTML:网页的“结构骨架”
HTML全称(hyper text markup language)译为超文本标记语言。
在Visual Studio Code中,HTML结构式有快捷方式输出:
HTML基本语法
HTML语言结构相对其它变成语言比较简单些,只要理解大体结构就好。
标签语法
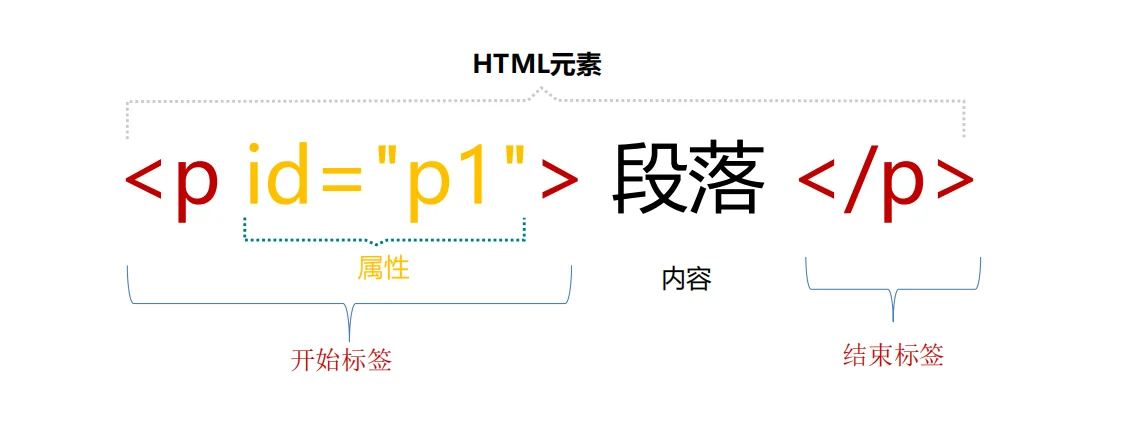
<标签名 属性名= “属性值” 属性名= “属性值” > </标签名>
<标签名 属性名= “属性值” />
属性语法
属性名= “属性值”
HTML 很简单 合起来
<标签名 属性名= “属性值”></标签名>
<标签名 属性名= “属性值” />
HTML基本标签
标题标签
<h1>标题</h1> 到<h6>标题</h6>
段落标签
p:paragraphs
<p>第一个段落</p>
超链接
<a href="" target="" ></a>
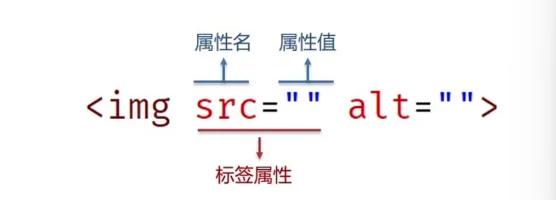
图片
<img src=""/>
换行
<br />
表单标签
<form action="" method=""></form>
表单元素标签
<input type="" name="" />
单行文本框
<input type="text" name="" />
密码框
<input type="password" name="" />
提交按钮
<input type="submit" name="" />
CSS:网页的 “样式装修”
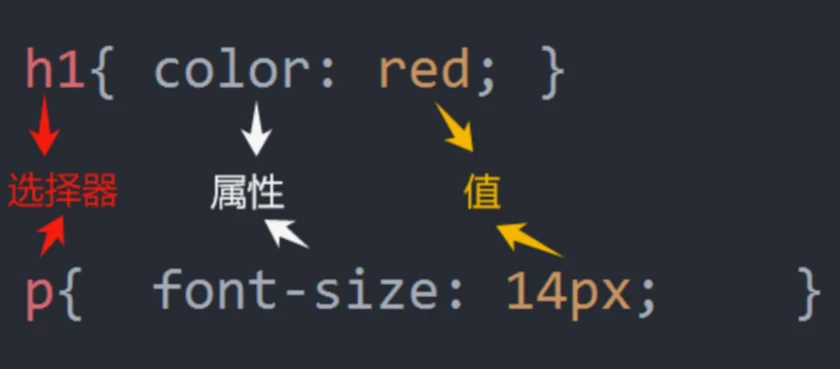
CSS 指的是层叠样式表(Cascading Style Sheets),使用CSS样式可以对页面字体、颜色、背景和其他效果实现精确描述。
CSS基础选择器:
元素选择器
标签名{}
id 选择器
#id属性值{}
class 选择器
.class属性值{}
常用样式:
尺寸样式:宽 width: 100px; 高 height: 100px;
背景样式:background: red;
文本样式:color: red;
字体样式:font-size: 100px;
https://expl0rer.top/
Javascript/JS:网页的 “交互功能”
JavaScript是一种轻量级、解释型的高级编程语言,它是网页开发中不可或缺的一部分,主要用于客户端脚本处理。
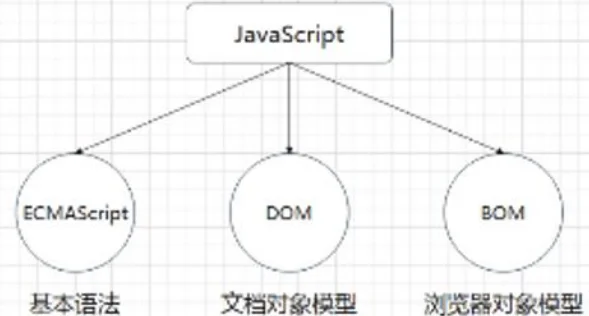
JavaScript可以给网页添加动态效果JavaScript由核心(ECMAScript)、文档对象模型(DOM)、浏览器对象模型(BOM)这三部分组成。
JS注释 (其实和大类编程语言的注释所用的符号差不多的):
单行//
多行/* ......*/
输出语句:
1、alert()警告框
2、document.write()文档写
变量
1、声明 var
2、赋值=
3、使用
这里举个函数例子:function
将某一个常用的功能进行封装。当你想使用这个功能的时候,可以选择调用、执行这个功能即可。关键字function定义函数函数使用分为两部分:声明、调用
定义函数
function 函数名(){
//函数体......
}
调用函数
函数名();
事件
JavaScript 中的事件(Event)是指发生在文档或浏览器窗口中,能够被 JavaScript 侦测到的交互行为或其他动作。事件可以是用户的操作(如点击按钮、按键、移动鼠标等),也可以是系统行为(如页面加载、滚动、错误发生等)。
按钮
1
2
3
4
5
6
7
8
9
<!DOCTYPE html>
< html >
< head >
< meta charset = "utf-8" >
< title ></ title >
</ head >
< body >
< button value = "button" onclick = "alert('hello hacker')" > 按钮</ button >
</ body ></ html >
JS对象概念
JS说一种基于对象的编程语言
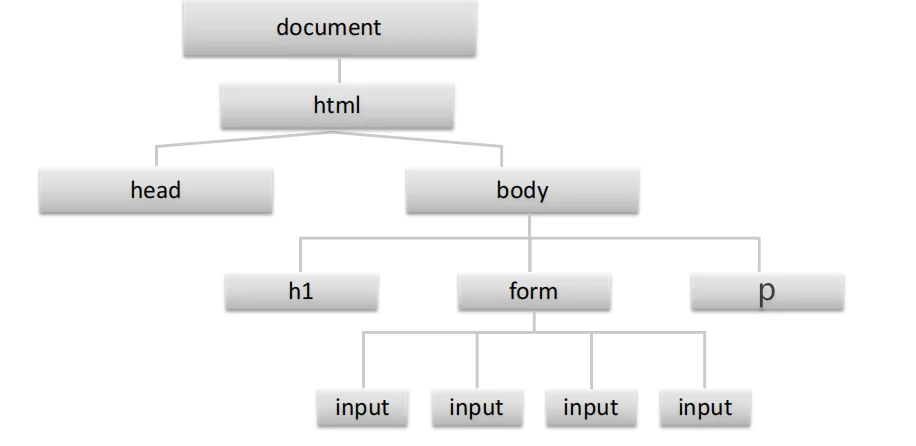
JS对象-DOM
当网页被加载时,浏览器会创建页面的文档对象模型HTML DOM 模型被构造为对象的树:
JS 来操作HTML文档时,一定要先获取元素
简单理解:JS 可以操作所有的HTML标签
JS获取文档对象:
getElementById():通过ID获取元素
例如:document.getElementById(‘p1’);
Web前端三件套
Web 前端三件套指的是 HTML、CSS、JavaScript 这三种核心技术,它们共同构成了浏览器中 “可交互、可视化网页” 的基础,三者分工明确又协同工作,就像 “建筑骨架、装修风格、功能控制系统” 的关系,缺一不可。
可以把网页比作 “一家咖啡店”:
HTML :咖啡店的 “空间结构”(哪里是吧台、哪里是座位、哪里是门口),定义 “有什么区域和功能模块”;CSS :咖啡店的 “装修风格”(墙面颜色、灯光亮度、桌椅样式、招牌设计),决定 “看起来好不好看”;JavaScript :咖啡店的 “服务功能”(店员响应点单、自动门感应开门、电视播放视频),实现 “用户能做什么交互”。
三者共同组成了我的博客......
没有 HTML,CSS 和 JS 就没有 “作用对象”;没有 CSS,HTML 只是无样式的骨架;没有 JS,网页只是 “静态图片”,无法响应用户操作。
Web后端
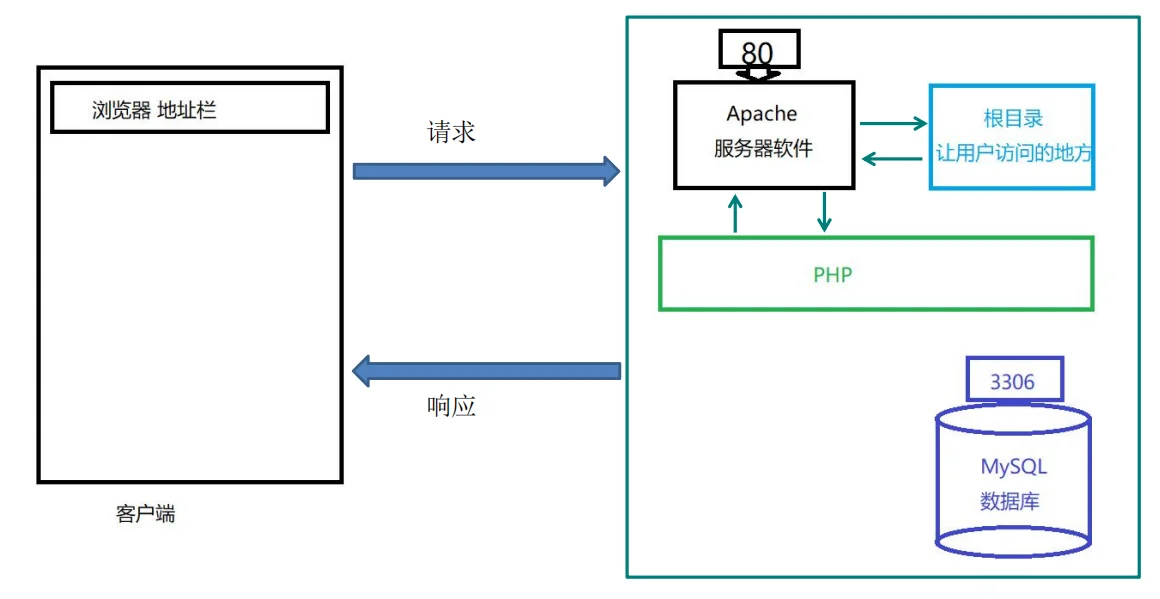
客户端与服务端交互流程:
中间件介绍:
Apache是Web服务器软件,它可以运⾏在⼏乎所有的计算机平台上,是最流⾏的Web服务器端软件之⼀:
Apache的官⽅⽹站
PHP基础
PHP的介绍
PHP(HyperText Preprocessor)全名为超文本预处理器,是一种专用在服务端的语言,为web涉及,可以嵌入到HTML语言,也就是后端的主要语言,php代码将在web服务端中被解释为HTML代码,返回客户端,详细可见PHP官方网站
对于环境搭建的话,想和Python、C、Java集成到一起可以用visual studio code;也可用phpstorm(强烈建议!环境搭建简单)
Phpstudy
自己去下载phpstudy,支持Windows和Linux的,教程不在这展示。
语法
PHP标记 <?php … ?>
指令分隔符 ; 注释 //单行注释 /多行注释 /
PHP 变量规则:
- 变量以 $ 符号开始,后面跟着变量的名称(可以理解为C语言的int、long int的定义作用...)
- 变量名必须以字母或者下划线字符开始
- 变量名只能包含字母、数字以及下划线(A-z、0-9 和 _ )
- 变量名不能包含空格
- 变量名是区分大小写的($y 和 $Y 是两个不同的变量)
注意:当赋一个文本值给变量时,需要在文本值两侧加上引号。
PHP 语句和 PHP 变量都是区分大小写的。
PHP页面输出:
echo——输出单一类型(数值,字符串,布尔),多个用逗号隔开。
print_r()——输出复合类型(数组,对象),一般用于输出数组 。
var_dump()——打印数据详细信息(所有类型)。
字符串类型
字符串定义方式:单引号、双引号
• 单引号字符串中出现的变量不会被变量的值替代。
• 双引号字符串中最重要的一点是其中的变量会被变量值替代。
• 如果遇到美元符号($),解析器会尽可能多地取得后面的字符以组成一个合法的变量名,如果想明确的指定名字的结束,用花括号把变量名括起来。
符号
还有些转义字符:
\n 换行
\r 回车 ( WINDOW \r\n ) (linux \n) (Mac OS \r)
\t 水平制表符 (按键盘 tab 产生的效果)
\ 反斜线
$ 美元符(表示变量的开始)
" 双引号
PHP运算符:
算术运算符:+ - * / % 取余数 9%3=0
赋值运算符:=
字符串运算符:. (点 - 字符串拼接符)
递增 递减:++ --
逻辑运算符:&& || !
比较运算符:> < >= <= == === != !== <>
三元运算符:? :
PHP流程控制
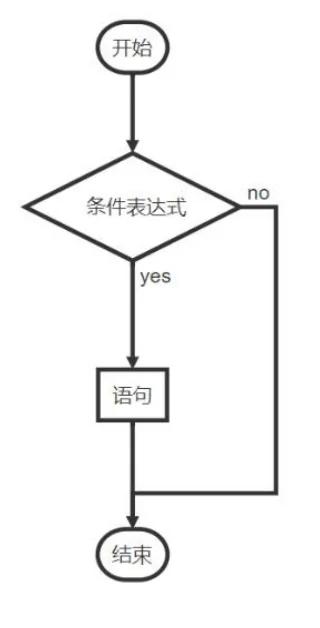
PHP流程控制语句用于决定代码的执行顺序循环则是重复执行某段代码直到满足特定条件为止
if、else 语句 - 在条件成立时执行代码
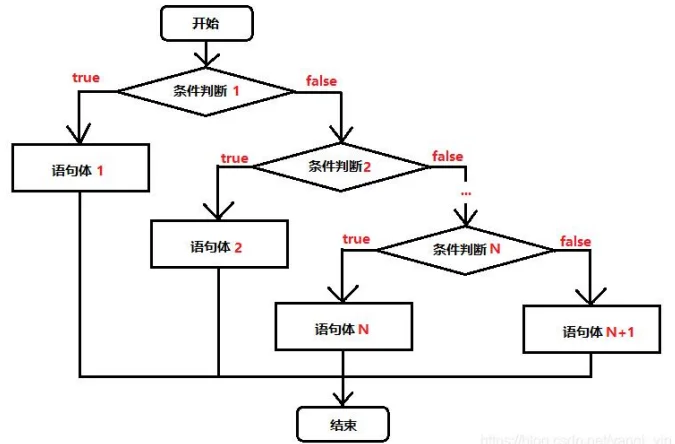
switch有选择地执行若干代码之一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<? php
...
switch ( n )
{
case label1 :
...
break ;
case label2 :
...
break ;
default :
...
}
?>
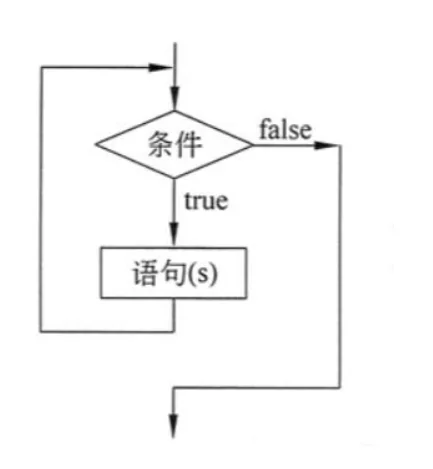
while只要指定的条件成立,则循环执行代码块:
1
2
3
4
5
6
7
8
<? php
....
while ( 条件 )
{
...
}
...
?>
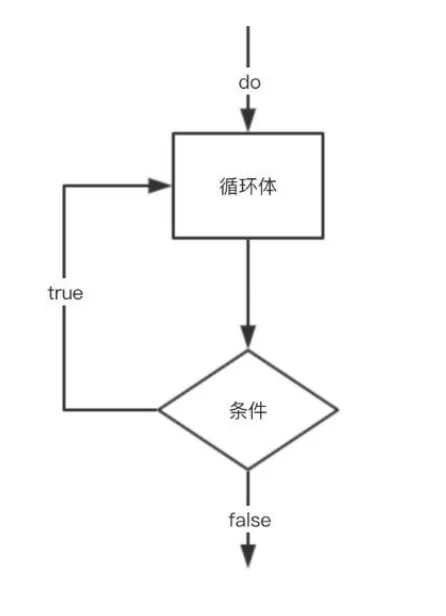
do...while首先执行一次代码块,然后在指定的条件成立时重复这个循环:
开始 do...while 循环。循环将变量 i 的值递增 1,然后输出。先检查条件(i 小于或者等于 5),只要 i 小于或者等于 5,循环将继续运行。
1
2
3
4
5
6
7
8
<? php
$i = 1 ;
do {
echo "The number is " . $i . "<br>" ;
$i ++ ;
} while ( $i <= 5 );
?>
for循环:
1
2
3
4
5
6
<? php
for ( 初始值;条件;增量 )
{
... ;
}
?>
PHP函数
PHP函数将实现某一功能的代码块封装到一个结构中,实现代码复用,只要系统在内存中能够找到对应的函数,就可以执行(函数的调用可以在函数定义之前)
函数的定义:
1
2
3
4
5
6
<? php
function functionName ()
{
// 要执⾏的代码
}
?>
函数的调用:
1
2
3
4
5
6
7
8
<? php
function writeName ()
{
echo "Kai Jim Refsnes" ;
}
echo "My name is " ;
writeName (); //调⽤函数
?>
函数名(参数);
PHP 函数准则:
函数的名称应该提示出它的功能;
函数名称以字母或下划线开头(不能以数字开头)。
示例,下面的函数有两个参数:
1
2
3
4
5
6
7
function name ( $s ) //形参
{
echo $s , "<br>" ;
}
echo "我的名字是" ;
name ( "张三" ); //实际参数
PHP函数——返回值
如需让函数返回⼀个值,请使⽤ return 语句:
1
2
3
4
5
6
7
8
9
<? php
function add ( $x , $y )
{
$total = $x + $y ;
return $total ;
}
echo "1 + 16 = " . add ( 1 , 16 ); //return调⽤要使⽤echo,不然不会返回值
?>
PHP内置函数
PHP 有很多标准的函数和结构。PHP系统提供了大量功能强大的函数,帮助我们解决各种问题;
isset(); 判断变量是否被设置
empty(); 判断变量是否为空
md5(); 32位加密字符串
include(); php包含文件
include_once(); php包含文件
require(); php包含文件
require_once(); php包含文件
serialize() 序列话函数
unserialize() 反序列话函数
这些函数是 PHP 安全的 “高频考点”,几乎所有涉及 PHP 的 CTF Web 题目(如文件包含、反序列化、逻辑漏洞、哈希绕过等)都会用到它们的特性。理解这些函数的工作原理、参数处理方式及潜在漏洞点,是解决 PHP 相关 Web 题目的基础:
哈希比较漏洞 :利用 md5() 对数组处理返回 null 的特性(如 md5([]) == md5([]) 为 true)绕过验证。include()/include_once()/require()/require_once()是 PHP 中文件包含漏洞 的直接成因,在 CTF 中极为常见
序列化与反序列化函数(serialize()/unserialize()):反序列化漏洞关键
Web基础
PHP数组
PHP数组是一种数据结构,用于存储键值对集合,其中每个键可以是整数索引或字符串索引,而值可以是任何类型的数据。
创建数组:array() 函数用于创建数组 [ ]----php版本5.4+
1
arry (); //$声明变量,在括号里面赋予值
PHP索引数组
这⾥有两种创建索引数组的⽅法:⾃动分配 ID 键(ID 键总是从 0 开始)
1
2
$a = array ( "蓝⾊" , "红⾊" , "⿊⾊" ); //⾃动分配ID键,从0开始
echo $a [ 0 ], "<br>" , $a [ 1 ], "<br>" , $a [ 2 ]; //输出
人工分配ID键:
1
2
3
4
$cars [ 0 ] = "蓝⾊" ; //⼿动分配下标,也是从0开始
$cars [ 1 ] = "红⾊" ;
$cars [ 2 ] = "⿊⾊" ;
echo $a [ 0 ], "<br>" , $a [ 1 ], "<br>" , $a [ 2 ]; //输出
PHP关联数组
下标是字符串,关联数组的键值对之间存在明确的对应关系。
1
2
3
4
$ren = array (
'name' => 'xiaolin' ,
'age' => 18
);
添加或修改元素:
1
2
$ren [ 'phone' ] = '13800138000' ; // 添加新元素
$ren [ 'age' ] = 26 ; // 修改已有元素
获取数组的长度 ——count()函数
count() 函数用于返回数组的长度(元素的数量)
1
2
3
4
<? php
$a = array ( "蓝⾊" , "红⾊" , "⿊⾊" ); //⾃动分配下标,从0开始
echo count ( $a ); //输出数组⻓度 ;;;输出结果为3
?>
遍历数值数组foreach :可以使用for循环以及foreach循环。
语法:遍历$array数组中的每个元素
1
2
3
foreach ( $array as $value ){
要执⾏代码 ;
}
示例:
1
2
3
4
5
6
<? php
$a = array ( "蓝⾊" , "红⾊" , "⿊⾊" ); //定义数组
foreach ( $a as $value ){ //使⽤foreach遍历数组,将a数组的值赋值给$value
echo $value , "<br>" ; //再输出$value值
?>
PHP表单操作
用户提交数据通常是使用表单进行提交,也可以使用网址中的参数传递数据,这些数据通过HTTP请求的方式发送,使web服务器获取。
PHP提供了预定义的超全局变量,用来获取HTTP请求信息。
$_GET(通过url接收)
$_POST(字符表单接收)
$_FILES(文件接收)
(超全局变量)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
<? php
if ( $_POST ) {
// print_r($_POST);
// 数据处理
$username = trim ( $_POST [ "username" ]);
$password = md5 ( $_POST [ "password" ]);
// echo $password;
// 保存到txt中 账号和密码之间用空格隔开 换行符
file_put_contents ( "user.txt" , $username . " " . $password . " \n " );
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>post</title>
</head>
<body>
<h1>post页面</h1>
<form action="" method="post">
<input type="text" name="username" id="">
<input type="password" name="password" id="">
<input type="submit" value="登录">
</form>
</body>
</html>
字符串处理函数
ltrim() 删除字符串左边的空白字符,或指定字符
rtrim() 删除字符串右边的空白字符,或指定字符
trim() 删除字符串两边的空白字符,或指定字符
strlen() 获取字符串长度
substr() 字符串截取
str_replace() 字符串替换
strtolower() 将字符串转换为小写字母
strtoupper() 将字符串转换为大写字母
strip_tags() 删除字符串中HTML XML PHP JS 标签
htmlspecialchars() 函数把一些预定义的字符转换为 HTML 实体字符
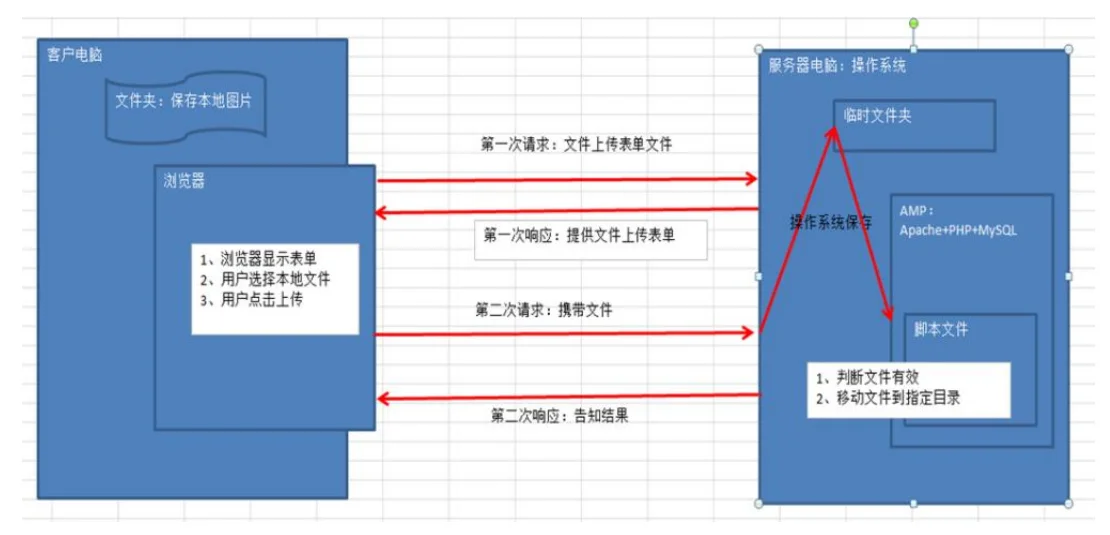
PHP文件上传流程:
PHP文件上传功能 :
文件上传必要条件
(1)method属性:表单提交方式必须为POST
(2)enctype属性:form表单属性,主要是规范表单数据的编码方式enctype= "multipart/form-data"
$_FILES超级全局变量作用是存储各种与上传文件有关的信息;
$_FILES是一个二维数组,数组中共有5项:
1、$_FILES["userfile"]["name"] 上传文件的名称,客户端机器文件的原名称。
2、$_FILES["userfile"]["type"]
上传文件的类型,文件的 MIME 类型,需要浏览器提供该信息的支持,例如“image/gif”。
3、$_FILES["userfile"]["size"]
上传文件的大小, 以字节为单位,已上传文件的大小,单位为字节。
4、$_FILES["userfile"]["tmp_name"]
文件上传后在服务器端储存的临时文件名,文件被上传后在服务端储存的临时文件名。
5、$_FILES["userfile"]["error"] 文件上传相关的错误代码0 1 2 3 4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
<? php
header ( 'Content-Type: text/html; charset=utf-8' );
if ( $_POST ) {
// 更改原⽂件名字
$name = $_FILES [ 'file' ][ 'name' ];
$tmp_name = $_FILES [ 'file' ][ 'tmp_name' ];
$ext = substr ( strrchr ( $name , "." ), 1 ); // 取后缀名
// ⽣成随机的⽂件名
$file_name = time () . rand () . "." . $ext ;
// 永久保存下来
$dir = "upload" ;
if ( ! is_dir ( $dir )) {
mkdir ( $dir , 0777 , true ); // 递归创建
}
$path = $dir . "/" . $file_name ; // upload/1234567890.1234567890.txt
if ( ! move_uploaded_file ( $tmp_name , $path )) { // 把临时⽂件 永久保存下来
echo "上传失败" ;
exit ;
}
echo "上传成功" ;
}
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>⽂件上传</title>
</head>
<body>
<h1>⽂件上传</h1>
<form action="" method="post" enctype="multipart/form-data">
<input type="text" name="username" id="">
<input type="file" name="file" id="">
<input type="submit" value="上传">
</form>
</body>
</html>
注:userfile只是一个占位符,代表文件上传表单元素的名字; 因此这个值将根据你所给定的名称有所不同。
PHP面向对象
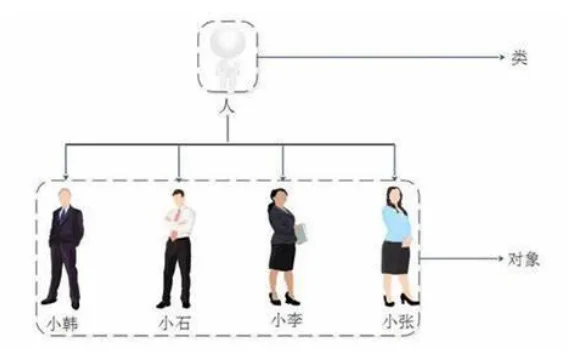
PHP面向对象是一种编程思想,面向对象是一种以对象(Object)为中心的编程思想。面向对象编程更注重对问题的抽象和封装,通过将问题分解为一系列相互协作的对象来实现程序的功能。(很类似Python的编程思想)
php类和对象:
类是抽象的概念,仅仅是模板。用来描述具有相同属性和方法的对象的集合。比如: "人"是一个类。
对象是类的实例,是某一个具体的事物 ,如 “黄结伟老师”则是具体存在的一个对象
例:类:人类(抽象事物)
对象: 黄结伟老师、UP主本人(实实在在存在的东西)
类修饰符
public(公有)
特性:在任何范围可访问(类内部、⼦类、类外部)
protected(保护)
特性:仅限类内部和⼦类访问
private(私有)
特性:仅定义该成员的类内部可访问
创建对象和类
在PHP中,使用class关键字来定义一个类class MyClass
{
// 类的属性和方法
}
以下实例中创建了⼀个名为 Fruit 的类,包含两个属性($name 和 $color),以及两个⽤于设置$name 属性的⽅法 set_name()。在类中,变量称为属性,函数称为⽅法!$this 关键字引⽤当前对象,并且只在⽅法内部可⽤:
1
2
3
4
5
6
7
8
9
10
11
12
<? php
class Fruit {
// 属性
public $name ;
public $color ;
// ⽅法
function set_name ( $name ) {
$this -> name = $name ;
}
}
?>
类可以包含属性(变量)和方法(函数)
属性用于存储数据,而方法用于执行操作
new关键字直接跟类名来创建对象
1
2
3
4
5
6
//创建了两个对象分别是 $apple 和 $banana
$apple = new Fruit ();
$banana = new Fruit ();
//通过创建的对象调⽤ Fruit 类中的 set_name ⽅法来修改属性值
$apple -> set_name ( 'Apple' );
$banana -> set_name ( 'Banana' );
PHP魔术方法 PHP魔术方法(Magic Methods)是一类特殊的方法,它们在PHP中具有特定的命名和功能,能够在特定情况下自动被调用。
命名规则:魔术方法通常以两个下划线(__)开头,后跟方法名称,如__construct()、__destruct()等。
它与常规PHP方法的区别?
与普通方法不同,魔术方法不需要显式调用,而是由PHP解释器在特定时机自动触发。
构造方法__construct() new
定义与用途
通常构造⽅法被⽤来执⾏⼀些有⽤的初始化任务,如对成员属性在创建对象时赋予初始值。声明格式:
1
2
3
function __constrct ([ 参数列表 ]){
⽅法体 //通常⽤来对成员属性进⾏初始化赋值
}
construct()是一个特殊的方法,当创建新对象时,该方法会自动被调用,用于初始化对象的状态或执行其他必要的操作。参数列表 construct()方法可以接受任意数量的参数,这些参数用于在创建对象时传递初始化数据。
使用示例
在类中定义construct()方法,并在创建对象时传递参数来初始****化对象的状态。 注意事项 如果类中定义了 construct()方法,则必须在创建对象时提供所需的参数,否则会导致错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<? php
class Person {
public $name ;
public $age ;
public $sex ;
/**
* 显示声明⼀个构造⽅法且带参数
*/
public function __construct ( $name = "" , $sex = "男" , $age = 22 ){
$this -> name = $name ;
$this -> sex = $sex ;
$this -> age = $age ;
}
public function say (){
echo "我叫:" . $this -> name . ",性别:" . $this -> sex . ",年龄:" . $thi
s -> age ;
}
}
//创建对象$Person1 且不带任参数
$Person1 = new Person ();
echo $Person1 -> say (); //输出:我叫:,性别:男,年龄:27
//创建对象$Person2 且带参数“⼩明”
$Person2 = new Person ( "⼩明" );
echo $Person2 -> say (); //输出:我叫:张三,性别:男,年龄:27
拆构方法__destruct()
定义与用途
destruct()是另一个特殊的方法,当对象不再被引用或脚本执行结束时,该方法会自动被调用,用于执行清理操作,如释放资源、关闭数据库连接等 。 参数列表 destruct()方法不接受任何参数。
1
2
3
function __destruct (){
//⽅法体
}
使用示例
在类中定义__destruct()方法,并在其中执行必要的清理操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<? php
class Person {
public $name ;
public $age ;
public $sex ;
public function __construct ( $name = "" , $sex = "男" , $age = 22 ){
$this -> name = $name ;
$this -> sex = $sex ;
$this -> age = $age ;
}
public function say (){
echo "我叫:" . $this -> name . ",性别:" . $this -> sex . ",年龄:" . $this -> age ;
}
public function __destruct (){
echo "我觉得我还可以再抢救⼀下,我的名字叫" . $this -> name ;
}
}
$Person = new Person ( "⼩明" );
unset ( $Person ); //销毁上⾯创建的对象$Person
不过说实话:⼀般来说,析构⽅法在 PHP 中并不是很常⽤,它属类中可选择的⼀部分,通常⽤来完成⼀些在对象销毁前的清理任务。
__sleep()方法 序列化 serialize ()
php序列化:将PHP数据结构转换为可存储/传输的字符串格式;序列化函数serialize()。
触发时机:当对象被序列化自动调用。
功能:该方法可以清理对象,并返回一个包含所有应被序列化的属性名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_WARNING级别的错误。
这种方法不接受任何参数!!
返回值:返回一个包含所有需要被序列化的属性名称的数组。
在对象被序列化之前,此⽅法会被调⽤。可以在这⾥做⼀些清理⼯作,⽐如关闭数据库连接,或者决定哪些对象属性应该被序列化。
__wakeuo()方法 unserialize ()
php反序列化:将序列化字符串还原为原始PHP数据结构;反序列化函数unserialize()。
触发时机:当反 序列化一个对象时自动调用。
功能:该方法可以重新建立数据库连接,或执行其它初始化操作。它不需要任何参数 ,也没有任何返回值。
但要注意:如果在反序列化 过程中,__wakeup() 方法 的执行抛出了一个异常,那么反序列化操作会失败,并抛出该异常。
**在对象被反序列化之后,此⽅法会被调⽤。这⾥可以⽤来重新建⽴那些在__sleep()中被断开的链接,⽐如重新打开数据库连接。
Python基础
Python的学习可以移步到我的文章:Python 学习
Python介绍
Python 是⼀种解释型、⾯向对象、动态数据类型的⾼级编程语⾔。
它被设计为可读性强、 简洁且易于学习,具有⾼效的高级数据结构,并且⽀持简单有效的⾯向对象编程。
Python官⽹:https://www.python.org
Web安全问题
MySQL数据库安全基础
数据库概述
1、数据库是什么?
存储数据的地方、DB:数据库(Database)
它是统一管理的、长期储存在计算机内的、有组织的相关数据的集合。数据库的基本特征包括:数据按一定的数据模型组织、描述和储存;数据间联系密切、冗余度较小;数据独立性较高;易扩展;可为各种用户共享。
2、为什么要用数据库?
因为应用程序产生的数据是在内存中的,如果程序退出或者是断电了,则数据就会消失。使用数据库是为了能够永久保存数据。当然这里指的是非内存数据库。
3、用普通文件存储行不行?
把数据写入到硬盘上的文件中,当然可以实现持久化的目标,但是不利于后期的检索和管理等。
4、MySQL、Oracle、SqlServer是什么?
MySQL、Oracle、SqlServer都是数据库管理系统(DBMS,Database ManagementSystem)是一种操纵和管理数据库的大型软件,例如建立、使用和维护数据库。
5、SQL是什么?
SQL是结构化查询语言(Structure Query Language),专门用来操作/访问数据库的通用语言。
MySQL数据库管理系统
在互联网行业,MySQL数据库毫无疑问已经是最常用的数据库。MySQL数据库由瑞典MySQL AB公司开发。公司名中的“AB”是瑞典语“aktiebolag”股份公司的首字母缩写。该公司于2008年1月16号被Sun(Stanford University Network)公司收购。然而2009年,SUN公司又被Oracle收购。因此,MySQL数据库现在隶属于Oracle(甲骨文)公司。MySQL中的“My”是其发明者(Michael Widenius,通常称为Monty)根据其女儿的名字来命名的。对这位发明者来说,MySQL数据库就仿佛是他可爱的女儿。
关系型数据库和非关系数据库
MySQL、Oracle、Microsoft SQL Server 和IBM DB2都是关系型数据库系统(database system)。除了管理数据,一个这样的系统还包括用来管理各种关系数据库的程序。通过SQL结构化查询语言来存取、管理关系型数据库的数据。
MongoDB、Redis、Elasticsearch等是非关系型数据库管理系统。
关系型数据库,采用关系模型来组织数据,简单来说,关系模型指的就是二维表格模型 。类似于Excel工作表。
非关系型数据库 ,可看成传统关系型数据库的功能阉割版本 ,基于键值对存储数据,通过减少很少用的功能,来提高性能。
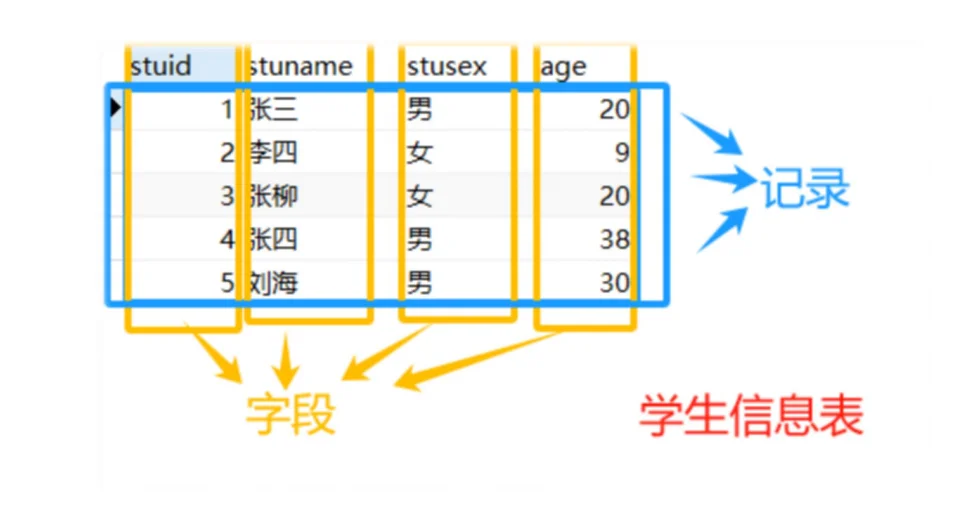
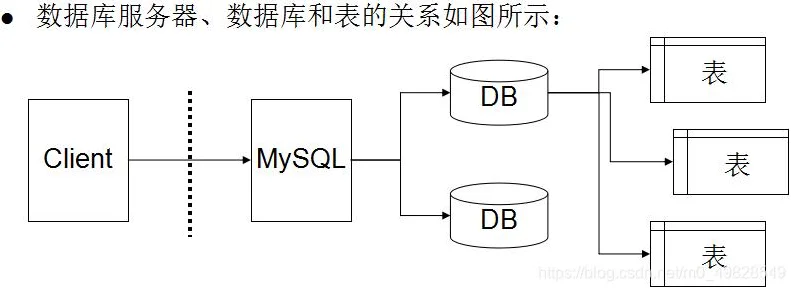
Mysql服务端架构:
1、数据库管理系统(最外层):DBMS,专门管理服务器端的所有内容。
2、数据库(第二层):Database,专门用于存储数据的仓库(可以有很多个)。
3、二维数据表(第三层):Table,专门用于存储具体实体的数据。
4、字段(第四层):Field,具体存储某种类型的数据(实际存储单元)。
MySQL的优点
主要的优势有如下几点:
可移植性:MySQL数据库几乎支持所有的操作系统,如Linux、Solaris、FreeBSD、Mac和Windows。
免费:MySQL的社区版完全免费,一般中小型网站的开发都选择 MySQL 作为网站数据库。
开源:2000 年,MySQL公布了自己的源代码,并采用GPL(GNU General Public License)许可
协议,正式进入开源的世界。开源意味着可以让更多人审阅和贡献源代码,可以吸纳更多优秀人才的代码成果。
关系型数据库:MySQL可以利用标准SQL语法进行查询和操作。
智榜样速度快、体积小、容易使用:与其他大型数据库的设置和管理相比,其复杂程度较低,易于学习。
MySQL的早期版本(主要使用的是MyISAM引擎)在高并发下显得有些力不从心,随着版本的升级
优化(主要使用的是InnoDB引擎),在实践中也证明了高压力下的可用性。从2009年开始,阿里的“去IOE”备受关注,淘宝DBA团队再次从Oracle转向MySQL,其他使用MySQL数据库的公司还有Facebook、Twitter、YouTube、百度、腾讯、去哪儿、魅族等等,自此,MySQL在市场上占据了很大的份额。
安全性和连接性:十分灵活和安全的权限和密码系统,允许基于主机的验证。连接到服务器时,所有的密码传输均采用加密形式,从而保证了密码安全。由于MySQL是网络化的,因此可以在因特网上的任何地方访问,提高数据共享的效率。
丰富的接口:提供了用于C、C++、Java、PHP、Python、Ruby和Eiffel、Perl等语言的API。
灵活:MySQL并不完美,但是却足够灵活,能够适应高要求的环境。同时,MySQL既可以嵌入到应用程序中,也可以支持数据仓库、内容索引和部署软件、高可用的冗余系统、在线事务处理系统等各种应用类型。
MySQL最重要、最与众不同的特性是它的存储引擎架构,这种架构的设计将查询处理(QueryProcessing)及其他系统任务(Server Task)和数据的存储/提取相分离。这种处理和存储分离的设计可以在使用时根据性能、特性,以及其他需求来选择数据存储的方式。MySQL中同一个数据库,不同的表格可以选择不同的存储引擎。其中使用最多的是InnoDB 和MyISAM,MySQL5.5之后InnoDB是默认的存储引擎。
针对不同用户,MySQL提供三个不同的版本:
(1)MySQL Enterprise Server(企业版):能够以更高的性价比为企业提供数据仓库应用,该版本需要付费使用,官方提供电话技术支持。
(2)MySQL Cluster(集群版):MySQL 集群是 MySQL 适合于分布式计算环境的高可用、高冗余版本。它采用了 NDB Cluster 存储引擎,允许在 1 个集群中运行多个 MySQL 服务器。它不能单独使用,需要在社区版或企业版基础上使用。
(3)MySQL Community Server(社区版):在开源GPL许可证之下可以自由的使用。该版本完全免费,但是官方不提供技术支持。本书是基于社区版讲解和演示的。在MySQL 社区版开发过程中,同时存在多个发布系列,每个发布处在不同的成熟阶段。
MySQL5.7(RC)是当前稳定的发布系列RC(Release Candidate候选版本)版只针对严重漏洞修复和安全修复重新发布,没有增加会影响该系列的重要功能。从MySQL 5.0、5.1、5.5、5.6直到5.7都基于5这个大版本,升级的小版本。5.0版本中加入了存储过程、服务器端游标、触发器、视图、分布式事务、查询优化器的显著改进以及其他的一些特性。这也为MySQL 5.0之后的版本迈向高性能数据库的发展奠定了基础。
MySQL8.0.26(GA)是最新开发的稳定发布系列。GA(General Availability正式发布的版本)是包含新功能的正式发布版本。这个版本是MySQL数据库又一个开拓时代的开始。
数据库管理工具
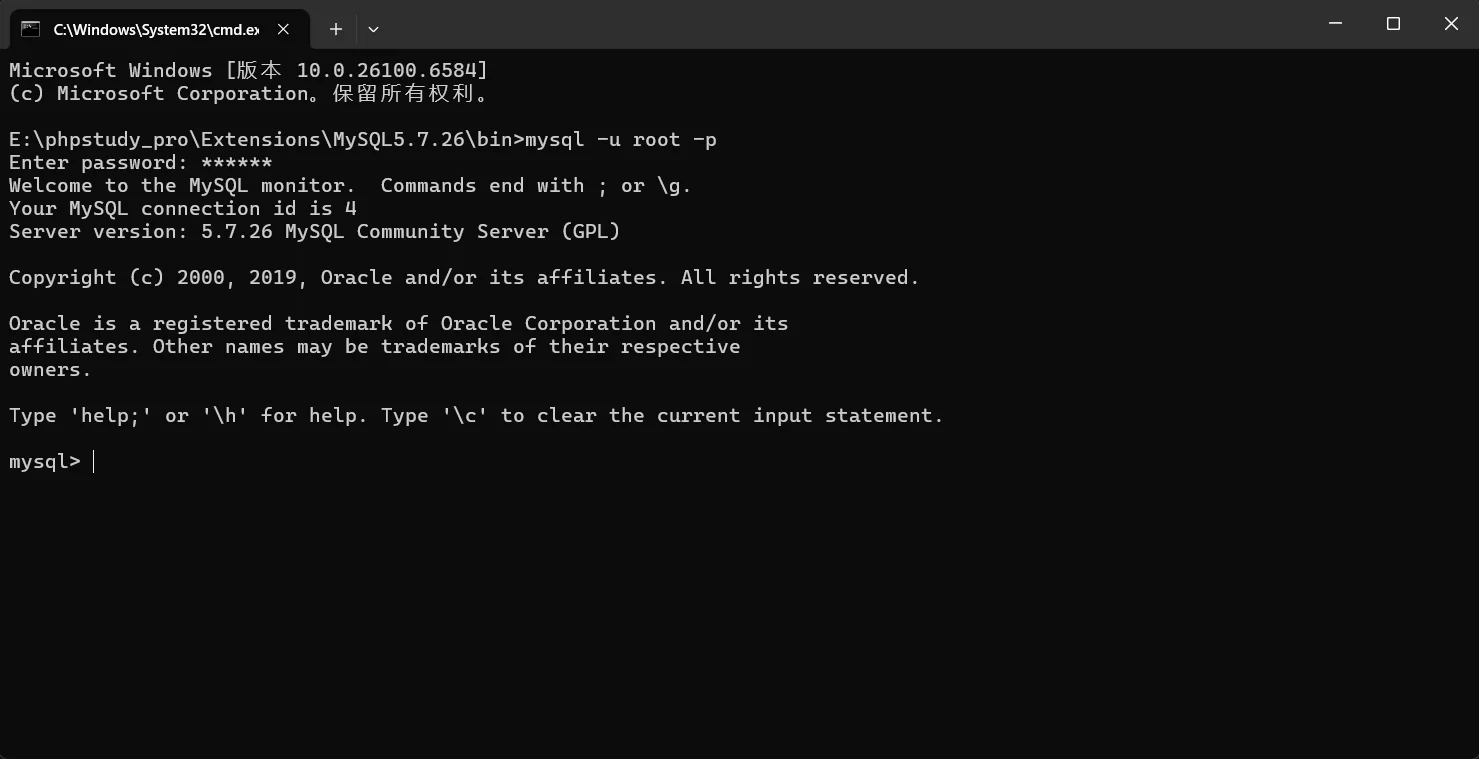
Mysql服务可以本地连接(记得开启mysql服务!!),用终端或者其它图像化工具(如PHPstudy、Navicat)
Navicat可以连接到MySQL服务器,进行数据库的创建、修改、删除等操作。
它支持数据表的创建、修改、删除以及数据的增删改查等操作。Navicat还提供了可视化的查询构建工具,使得查询操作更加直观和方便。
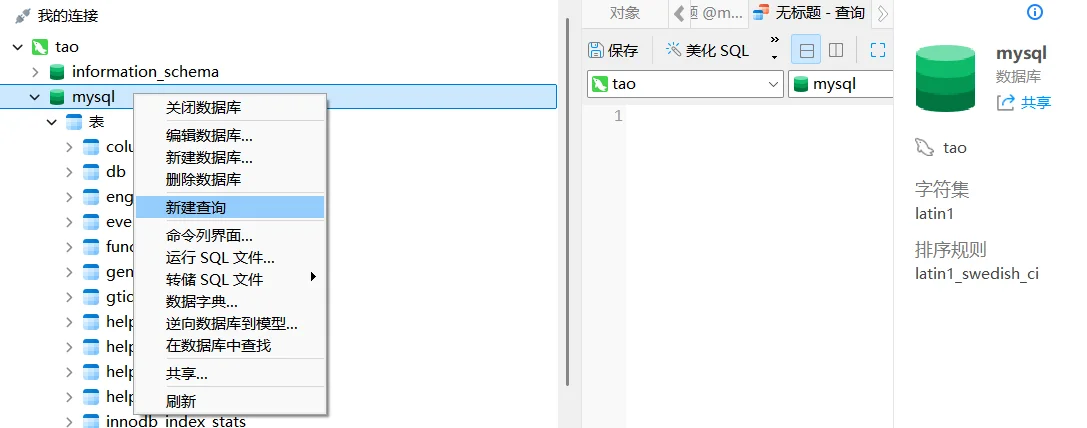
现在我来做一个粗略的介绍,这个数据库里面的东西的含义,以图形化界面Navicat为例:
连接好mysql后,我们看到一个
大致是这样,有些人数据库比较多,看自己之前是否有涉及到这方面应用可能会下载过一些定西,比如pikachu ,我这里都是默认的数据库。
查看数据表:
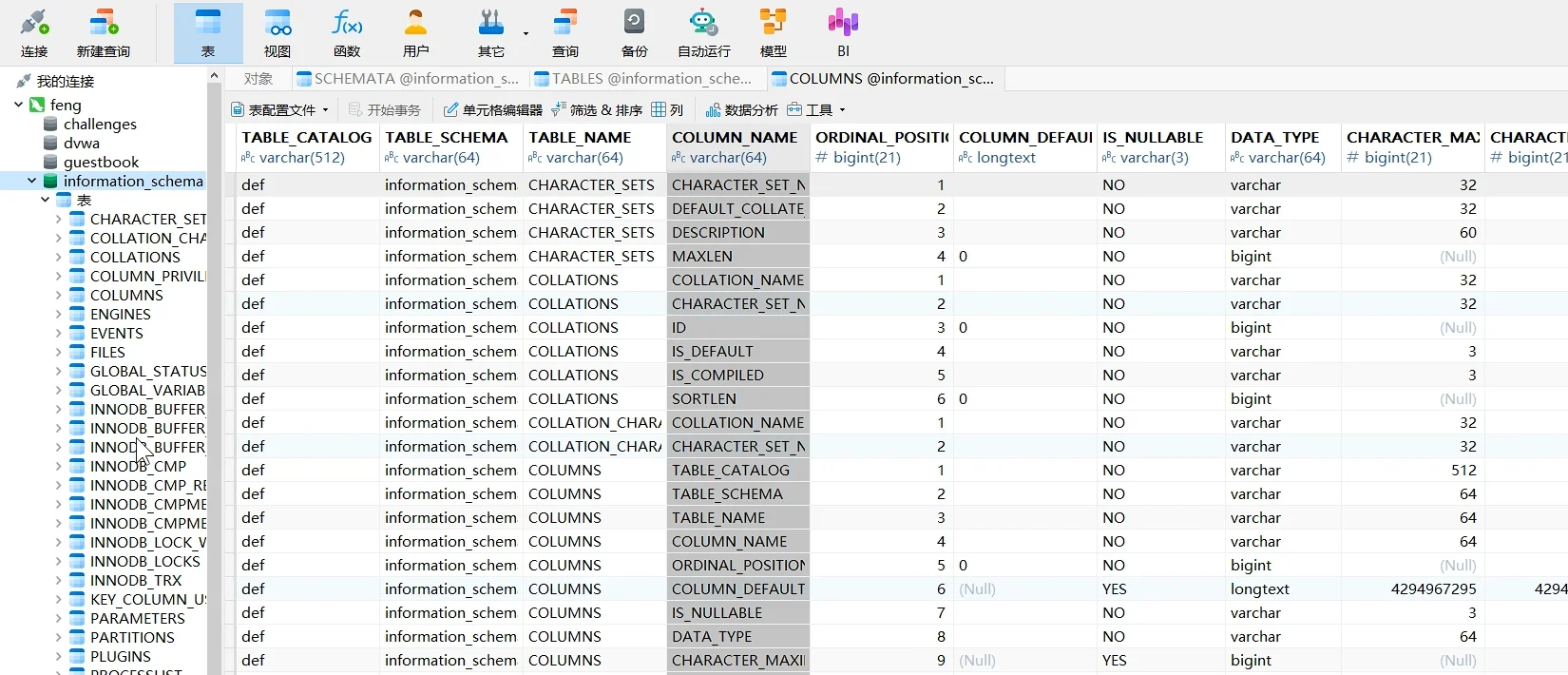
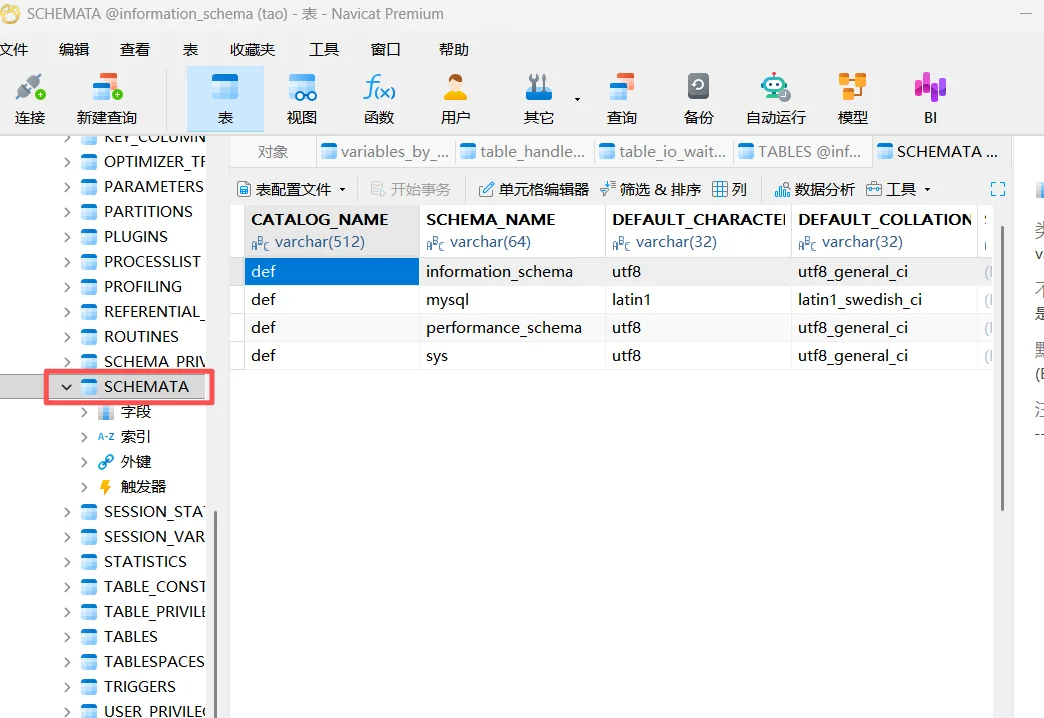
以SCHEMATA为例:
可以发现这很像excel表格,有表单有字段数据等,前文介绍了数据库,大概就是这样储存的;再细心发现这好像是上上一张图的一些数据库的名字,这个板块其实储存的是数据库的表名。
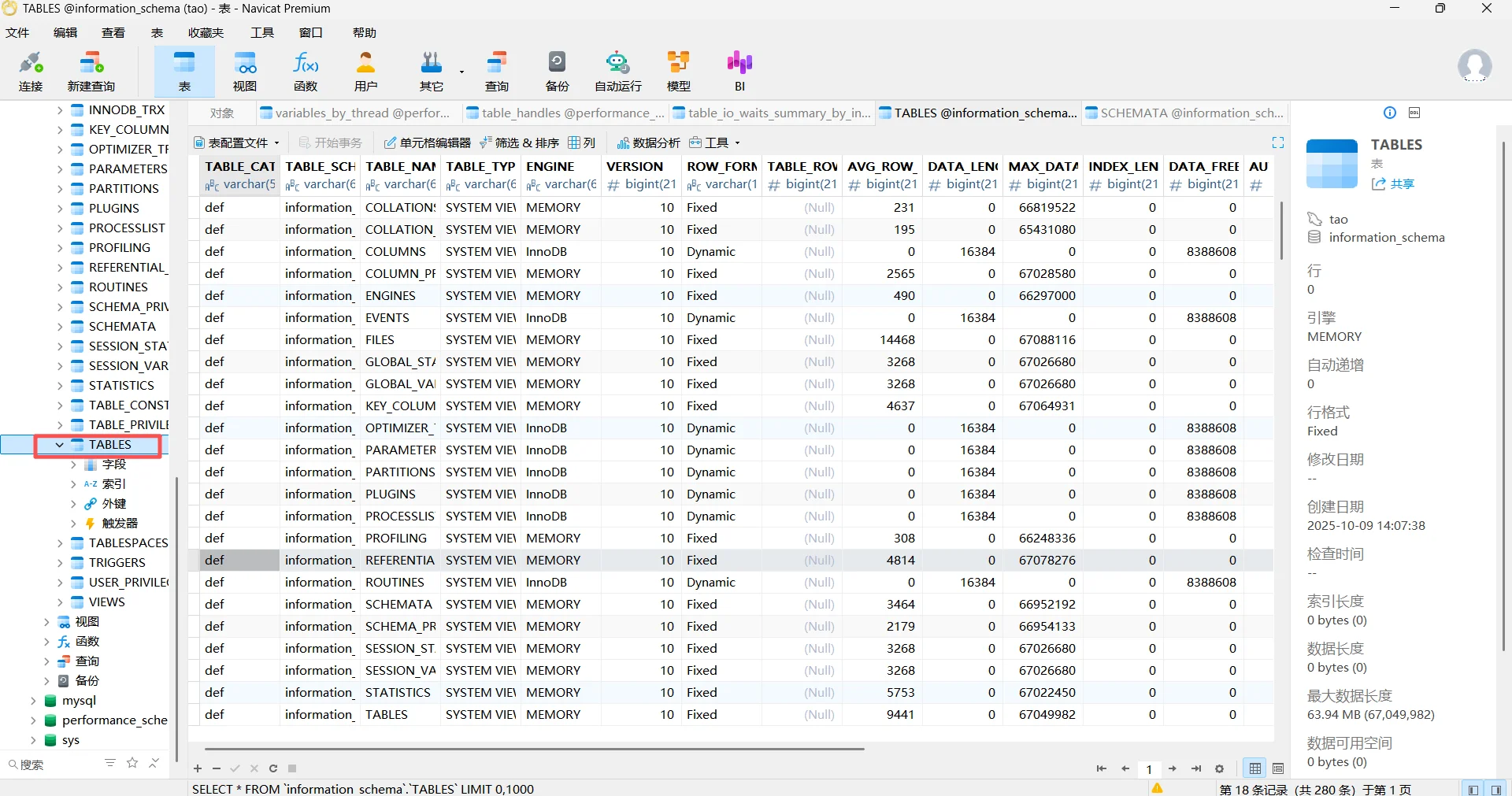
来,我们看到TABLES这一张表:
晕了晕了......这么多。
看到第三列,这其实是数据库表名相关对应的TABLES表;第二列就是名子,在SCHEMATA的表看到。
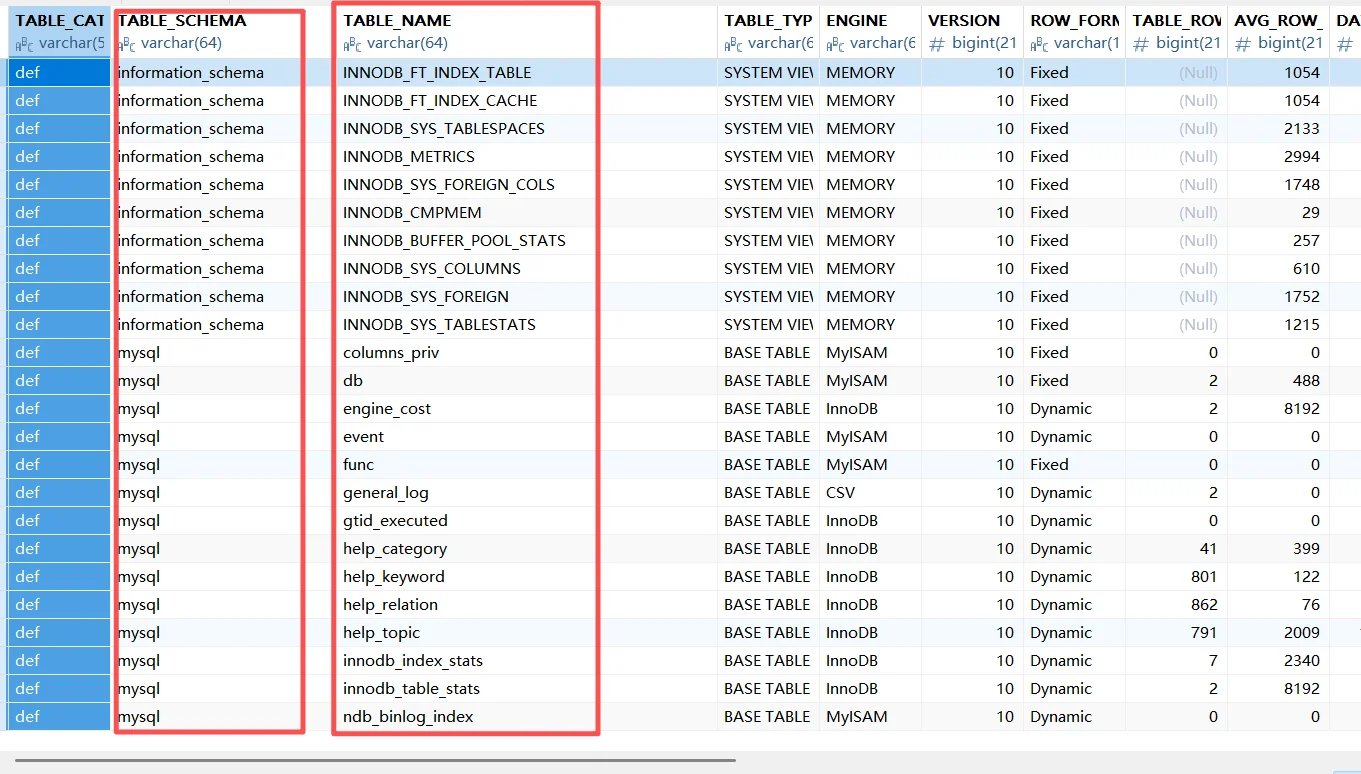
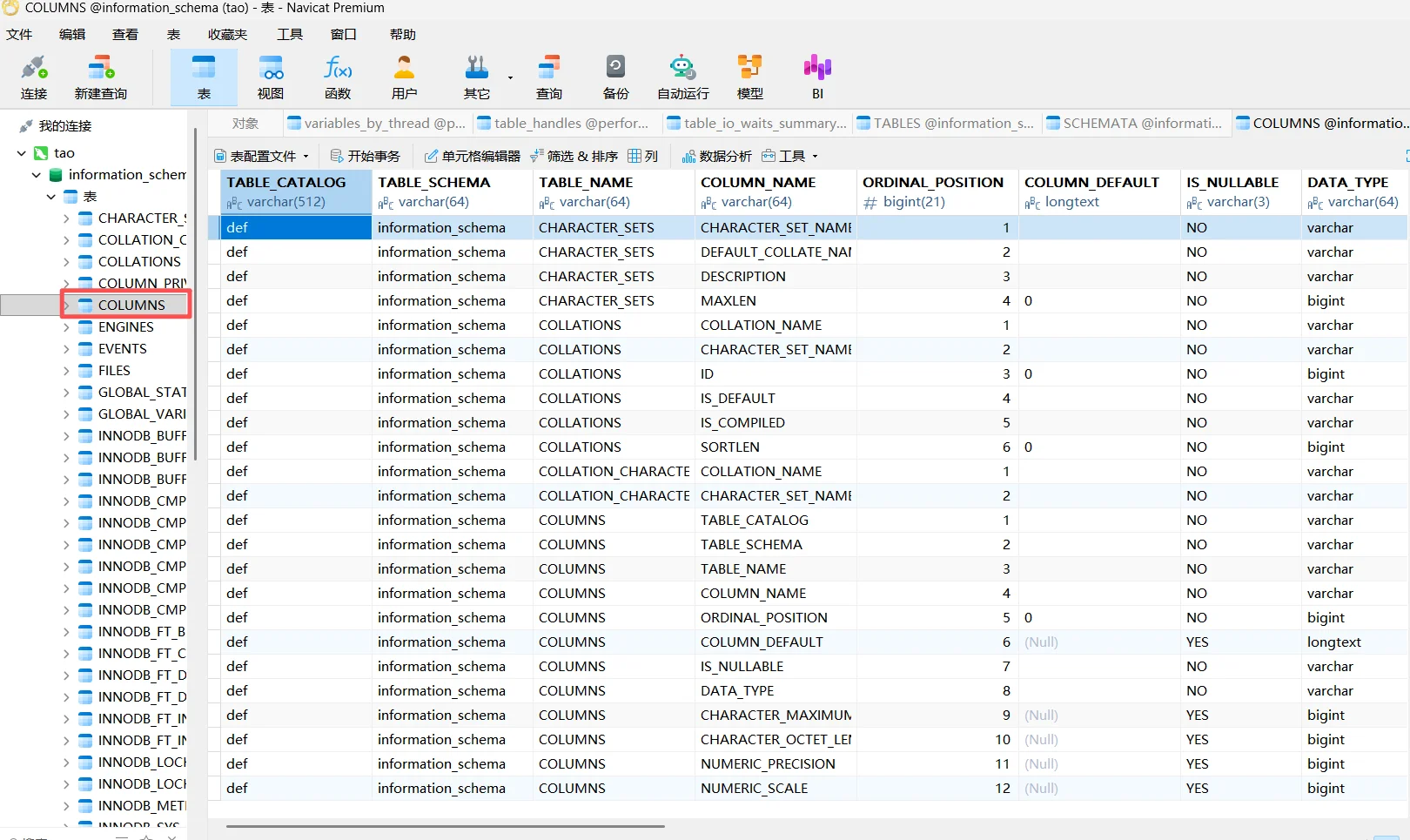
看到COLUMNS:
第二列存放的是数据库名;第三列是存放的是表名;第四列存放的就是跟字段名字相关的名字。
幸运的是,如果你能坚持看到这里,不免会像我一样有疑惑:(我为什么要写这Mysql)我为什么要看这段文章,感觉跟CTF、攻防、渗透好像关系不大啊...当我看回自己这篇文章也会觉得,其实对Mysql等数据库来说,这方面安全也需要多加在意的,这就是数据库安全,你耐心学,去了解这些Mysql等数据库知识,这也是以便你后面进行SQL注入学习、查询打下的一个基础,切忌速通、一把梭!慢工出细活,了解本质才能赢下去。
大家只需要多关注一下这三个表:COLUMNS、TABLES、SCHEMATA。其它的表点进去看一下浅浅了解下就好。
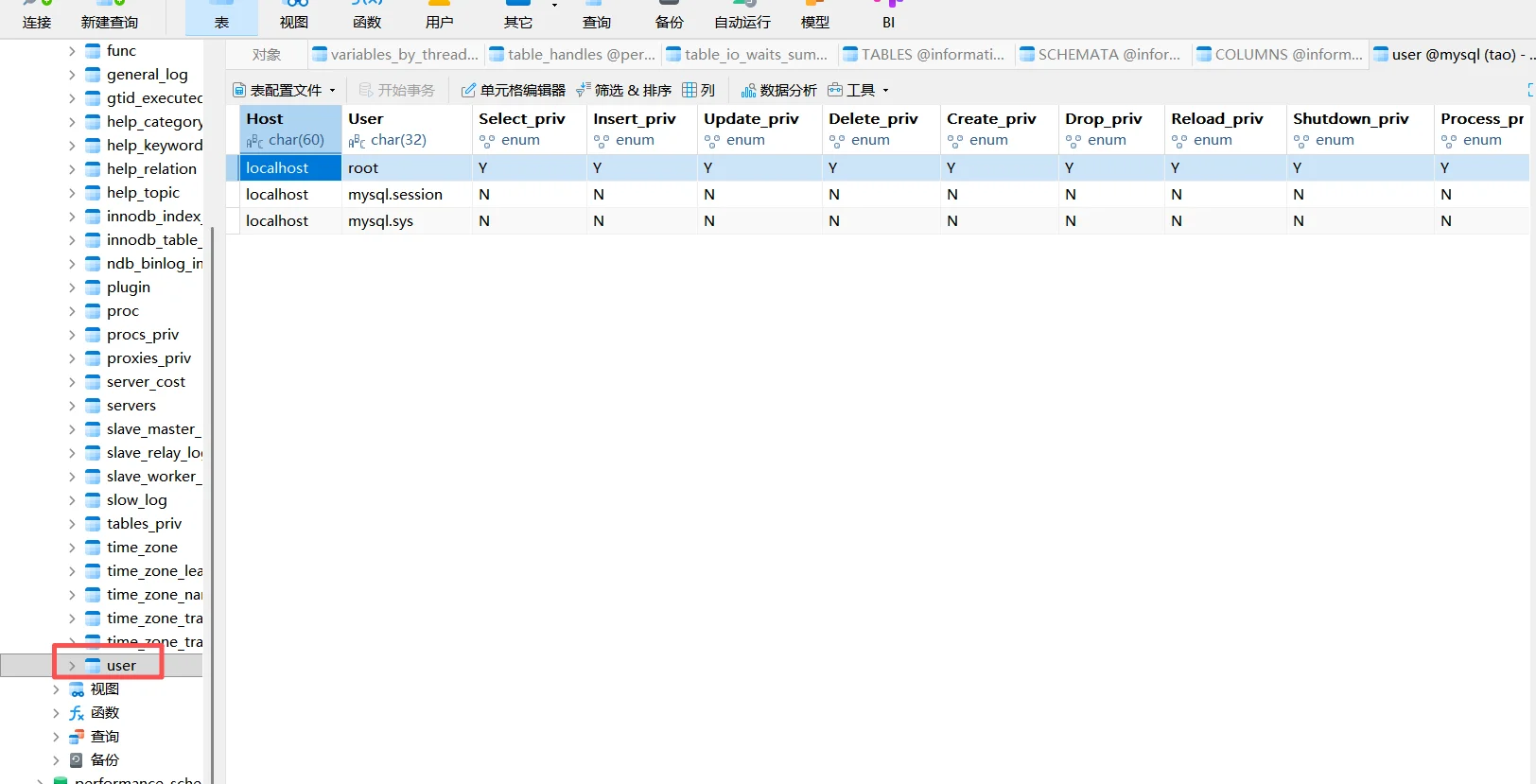
接下来我们倒回去查看mysql数据库中的user表:
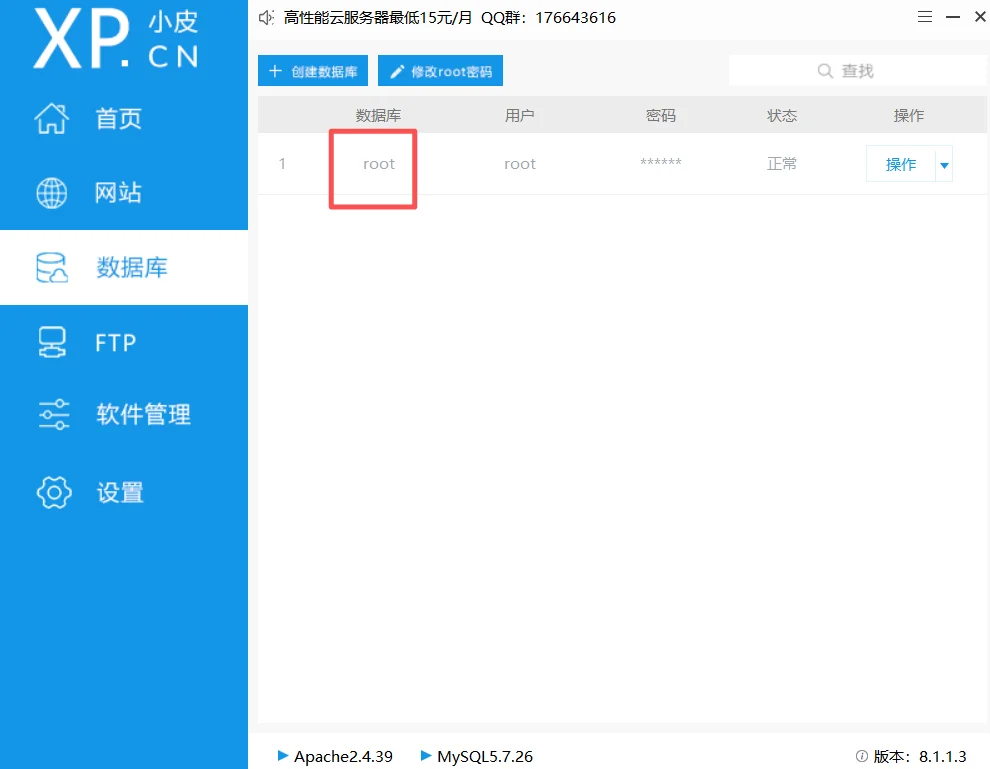
顺便打开phpstudy,对照一下:
可以看到数据库表上有个root,和我的小皮界面上的root对应上了,我这里没有打开,你自己尝试的话可以发现是有个IP地址在上面,还有主机名,这都是mysql所记录名单下的数据。可以知道user表下存储的就是用户的权限数据、密码、主机名还有IP。
这很可怕,意味着在实际情况中,数据库安全做得不到位得话被入侵就意味着数据被泄露。
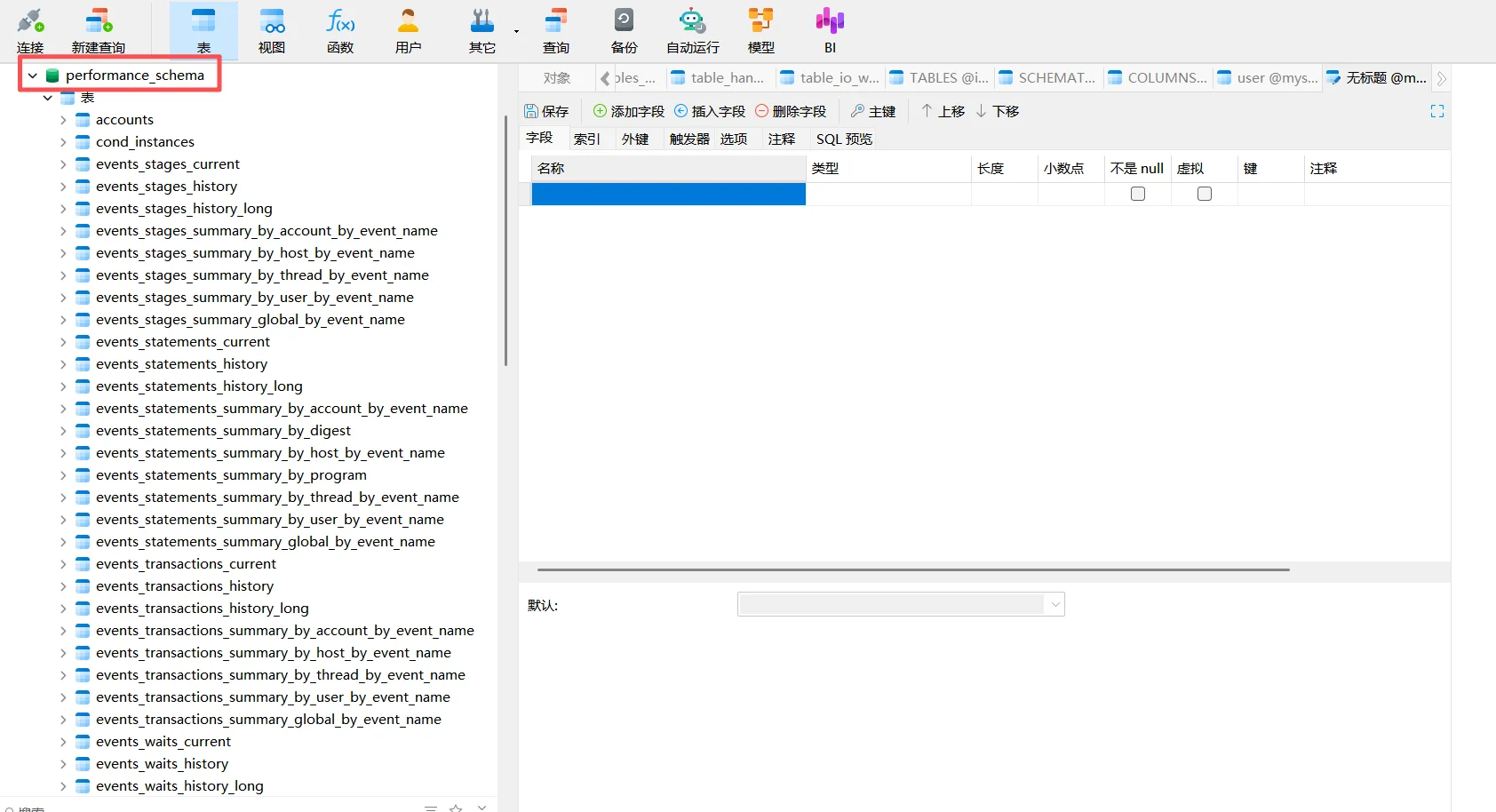
翻到performance_schema数据库:
这个数据库内容包含得是诊断数据库的问题、报错,语句执行得时间,类似于日志那样的。
如果你是打算走电子取证方向 的话,这个地方你后面会接触的比较多。
总结:主要还是关注performance_schema、mysql、information_schema这三个系统数据库。
数据库数据类型
是指MySQL数据库中用于定义表的列时可以指定的数据类型,它们决定了列中可以存储什么类型的数据。MySQL支持多种数据类型,每种数据类型都有其特定的用途和限制。
数值类型
类型
存储(字节)
有符号数值取值范围
无符号数值取值范围
TINYINT
1
-128 ~ 127
0 ~ 255
SMALLINT
2
-32768 ~ 32767
0 ~ 65535
MEDIUMINT
3
-8388608 ~ 8388607
0 ~ 16777215
INT
4
-2147483648 ~ 2147483647
0 ~ 4294967295
BIGINT(整数值超过int时使用)
8
-2^63 ~~ (2^63 -1)
0 ~ 2^64-1
浮点数类型
FLOAT:占用4个字节,用于表示单精度浮点数值。
DOUBLE:占用8个字节,用于表示双精度浮点数值。(小数点后的数字更多,内存空间也会更多)
DECIMAL:用于表示高精度的小数,其精度和计数方法可以指定,以适应特定的需求。(小数点后位更多,一般银行使用的较多)
日期和时间类型
类型
大小(bytes)
范围
格式
用途
DATE
3
1000-01-01/9999-12-31
YYYY-MM-DD
日期值
TIME
3
-838:59:59/838:59:59
HH:MM:SS
时间值或持续时间
YEAR
1
1901/2155
YYYY
年份值
DATETIME
8
1000-01-01 00:00:00' 到 '9999-12-31 23:59:59
YYYY-MM-DD
混合日期和时间值
TIMESTAMP
4
1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07
YYYY-MM-DD
混合日期和时间值,时间戳
字符串类型
类型
大小
用途
CHAR
0-255 bytes
定长字符串
VARCHAR
0-65535 bytes
变长字符串
TINYBLOB
0-255 bytes
不超过 255 个字符的二进制字符串
TINYTEXT
0-255 bytes
短文本字符串
BLOB
0-65 535 bytes
二进制形式的长文本数据
TEXT
0-65 535 bytes
长文本数据
MEDIUMBLOB
0-16 777 215 bytes
二进制形式的中等长度文本数据
MEDIUMTEXT
0-16 777 215 bytes
中等长度文本数据
LONGBLOB
0-4 294 967 295 bytes
二进制形式的极大文本数据
LONGTEXT
0-4 294 967 295 bytes
极大文本数据
客户端使用演示(终端命令行)
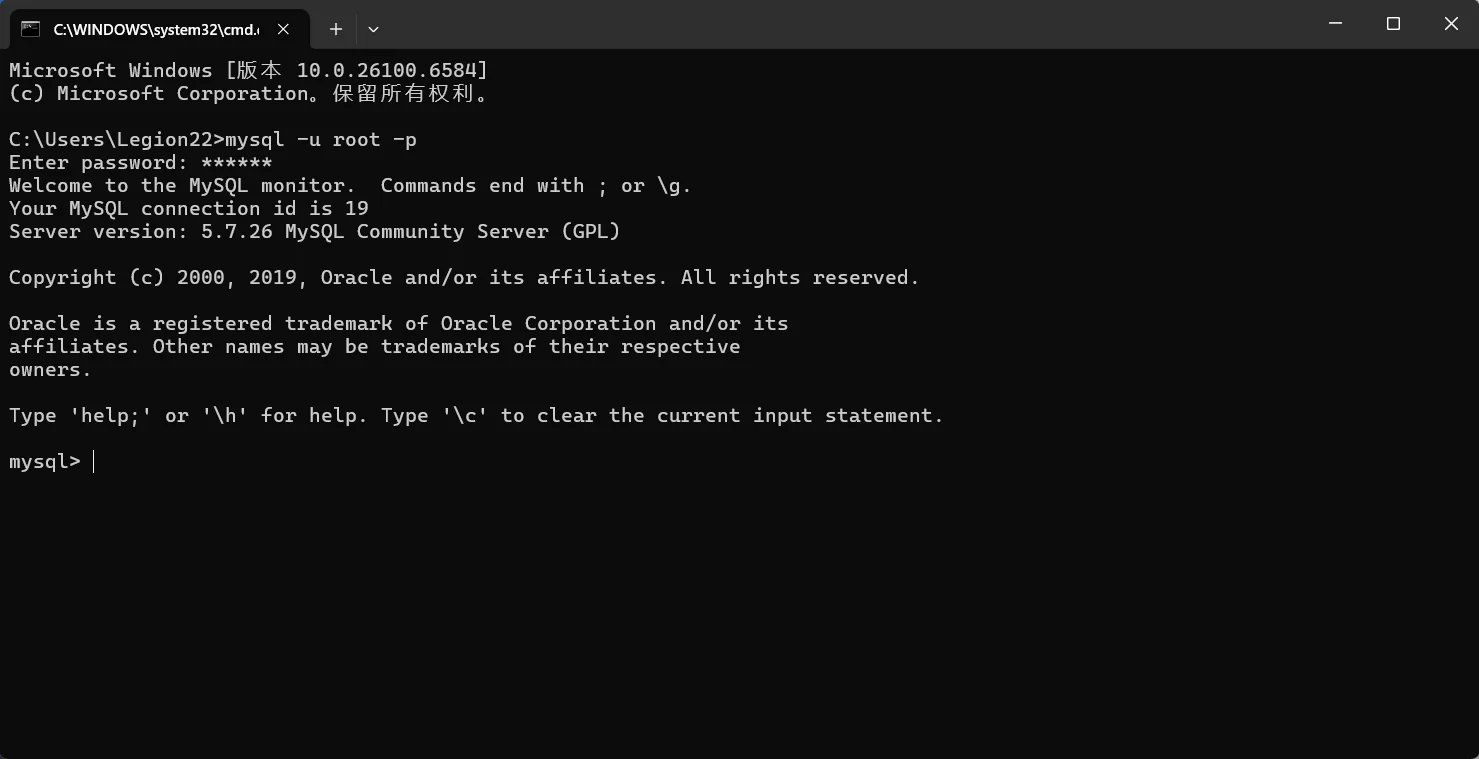
接下来可以用mysql命令去字节实操一下:
数据库
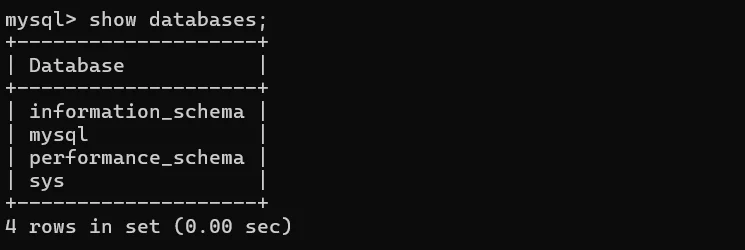
1、查看所有数据库(分号;别漏)
可以发现这个正是我们在navicat上看到的界面,只不过这是终端界面比较枯燥。
2、创建自己的数据库
1
2
3
4
create database 数据库名 ;
#创建zbydb数据库
create database zbydb ;
3、删除数据库
1
2
#删除zbydb数据库
drop database zbydb ;
4、使用自己的数据库
1
2
3
4
use 数据库名 ;
#使用zbydb数据库
use zbydb ;
说明:如果没有使用use语句,后面针对数据库的操作也没有加“数据名”的限定,那么会报“ERROR 1046(3D000): No database selected”(没有选择数据库)
使用完use语句之后,如果接下来的SQL都是针对一个数据库操作的,那就不用重复use了,如果要针对另一个数据库操作,那么要重新use。
数据表
1、查看某个库的所有表格
1
2
show tables ; #要求前面有use语句
show tables from 数据库名 ;
2、创建新的表格
1
2
3
4
create table 表名称 (
字段名 数据类型 ,
字段名 数据类型
);
说明:如果是最后一个字段,后面就用加逗号,因为逗号的作用是分割每个字段。
1
2
3
4
5
#创建学生表
create table student (
id int ,
name varchar ( 20 ) #说名字最长不超过20个字符
);
3、查看定义好的表结构
1
2
desc 表名称 ;
desc student ;
4、添加一条记录
1
2
3
4
5
insert into 表名称 values ( 值列表 );
#添加两条记录到student表中
insert into student values ( 1 , '张三' );
insert into student values ( 2 , '李四' );
5、查看一个表的数据
6、删除表
1
2
#删除学生表
drop table student ;
可视化客户端
前面介绍了通过命令行来创建数据库和数据表,除此之外,还可以借助MySQL图形化工具,而且这种方式更加简单、方便。下面以SQLyog图形化工具为代表展开介绍。
在前面已经介绍过可视化数据库使用,在此只要粗略过一遍就好。
数据库
以查看所有数据库的方式登录连接成功后,进入主界面,接下来正式创建数据库。
步骤1:在主界面左边“数据库对象导航窗口”的空白处右键单击鼠标弹出快捷菜单,选择“新建数据库”菜单项。
步骤2:填写新数据库的基本信息。一般只需填写数据库名称,例如“test”,字符集和排序规则有默认选项。如果有特殊要求,也可以选择自己需要的字符集和校对规则,然后点击“创建”按钮。
步骤3:此时数据库创建成功。
步骤4:数据库创建成功之后,可以查看或修改数据库属性。选择“myschool”数据库,右键单击鼠标弹出快捷菜单,选择“编辑数据库”菜单选项,就可以查看或修改数据库属性。
数据表
数据库创建成功之后,就可以在这个数据库下面创建表了。
步骤1:选择“myschool”数据库下的“表”对象,右键单击鼠标弹出快捷菜单,选择“新建表”菜单项。
步骤2:点击“新建表”后,在新表的创建页面填写表名称和表的字段等属性信息。例如表名称为“tb_student”,并添加两个字段,一个是int类型的sid,一个是varchar(20)类型的sname,分别表示学生编号和学生姓名。
SQL语句
SQL:结构化查询语言,(Structure Query Language),专门用来操作/访问数据库的通用语言。
SQL的分类
DDL语句:数据定义语句(Data Define Language),例如:创建(create),修改(alter),删除(drop)等。
DML语句:数据操作语句,例如:增(insert),删(delete),改(update),查(select)。
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类,DQL(数据查询语言),DR(获取)L。
DCL语句:数据控制语句,例如:grant,commit,rollback等。
其他语句:USE语句,SHOW语句,SET语句等。这类的官方文档中一般称为命令。
SQL语法规范
(1)mysql的sql语法不区分大小写
1、数据库的表中的数据是否区分大小写。这个的话要看表格的字段的数据类型、编码方式以及校对规则。
ci(大小写不敏感),cs(大小写敏感),_bin(二元,即比较是基于字符编码的值而与language无关,区分大小写)。
2、sql中的关键字,比如:create,insert等,不区分大小写。但是大家习惯上把关键字都“大写”。
(2)命名时:尽量使用26个英文字母大小写,数字0-9,下划线,不要使用其他符号。
(3)建议不要使用mysql的关键字等来作为表名、字段名、数据库名等,如果不小心使用,请在SQL语句中使用“`”(飘号)引起来。
(4)数据库和表名、字段名等对象名中间不要包含空格。
(5)同一个mysql软件中,数据库不能同名,同一个库中,表不能重名,同一个表中,字段不能重名。
SQL脚本中如何加注释
单行注释:#注释内容(mysql特有的)
单行注释:--空格注释内容 其中--后面的空格必须有
多行注释:/* 注释内容 */
1
2
3
4
5
6
7
8
9
create table tt (
id int , #编号
` name ` varchar ( 20 ), -- 姓名
gender enum ( '男' , '女' )
/*
性别只能从男或女中选择一个,
不能两个都选,或者选择男和女之外的
*/
);
mysql脚本中的标点符号
mysql脚本中标点符号的要求如下:
本身成对的标点符号必须成对,例如:(),'',""。
所有标点符号必须英文状态下半角输入方式下输入。
DDL
在你创建好数据库后,你肯定是要想有搜索功能的,这时查询功能就体现出来了,以下是终端Mysql的命令:
创建表:
修改表:
删除表:
接下来我用navicat来演示:
选择数据库(我以我的Mysql为例)后创建好查询表。
这就是一个面板,很像一些我们经常用的vscode、pycharm那样的编程界面,这里面就是给它编写sql语言的。
......至于怎么编写我就不演示了,可以自己试一试,参考SQL语法 编写。
写好语句后Ctrl+S保存,起个名字,我这里是起666:
DQL
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类,DQL(数据查询语言),DR(获取)L。
SELECT语句
SELECT语句是用于查看计算结果、或者查看从数据表中筛选出的数据的。
SELECT语句的基本语法:
1
2
3
SELECT 常量 ;
SELECT 表达式 ;
SELECT 函数 ;
for instance:
1
2
3
SELECT 1 ;
SELECT 9 / 2 ;
SELECT NOW ();
如果要从数据表中筛选数据,需要加FROM子句。FROM指定数据来源。字段列表筛选列。
如果要从数据表中根据条件筛选数据,需要加FROM和WHERE子句。WHERE筛选行。
1
SELECT 字段列表 FROM 表名称 WHERE 条件 ;
完整的SELECT语句后面可以跟7个子句,后面会逐一讲解。
使用别名
在当前select语句中给某个字段或表达式计算结果,或表等取个临时名称,便于当前select语句的编写和理解。这个临时名称称为别名。
1
select 字段名 1 as "别名1" , 字段名 2 as "别名2" from 表名称 as 别名 ;
列的别名有空格时,请加双引号。列的别名中没有空格时,双引号可以加也可以不加 。
表的别名不能加双引号 ,表的别名中间不能包含空格。as大小写都可以,as也完全可以省略。
1
mysql > select * from student ;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set ( 0 . 00 sec )
mysql > select id "学号" , name "姓名" from student ;
+------+------+
| 学号 | 姓名 |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set ( 0 . 00 sec )
mysql > select id 学号 , name 姓名 from student ;
+------+------+
| 学号 | 姓名 |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set ( 0 . 00 sec )
#查询薪资高于15000的员工姓名和薪资
select ename , salary from t_employee where salary > 15000 ;
mysql > select ename , salary from t_employee where salary > 15000 ;
+--------+--------+
| ename | salary |
+--------+--------+
| 孙洪亮 | 28000 |
| 贾宝玉 | 15700 |
| 黄冰茹 | 15678 |
| 李冰冰 | 18760 |
| 谢吉娜 | 18978 |
| 舒淇格 | 16788 |
| 章嘉怡 | 15099 |
+--------+--------+
7 rows in set ( 0 . 00 sec )
#查询薪资正好是9000的员工姓名和薪资
select ename , salary from t_employee where salary = 9000 ;
select ename , salary from t_employee where salary == 9000 ; #错误,不支持== #注意Java中判断用==,mysql判断用=
mysql > select ename , salary from t_employee where salary == 9000 ;
ERROR 1064 ( 42000 ): You have an error in your SQL syntax ;
check the manual that corresponds to your MySQL server version for the right
syntax to use near '== 9000' at line 1
#查询籍贯native_place不是北京的
select * from t_employee where native_place != '北京' ;
select * from t_employee where native_place <> '北京' ;
#查询员工表中部门编号不是1
select * from t_employee where did != 1 ;
select * from t_employee where did <> 1 ;
#查询奖金比例是NULL
select * from t_employee where commission_pct = null ;
mysql > select * from t_employee where commission_pct = null ; #无法用=null判断
Empty set ( 0 . 00 sec )
#mysql中只要有null值参与运算和比较,结果就是null,底层就是0,表示条件不成立。
#查询奖金比例是NULL
select * from t_employee where commission_pct <=> null ;
select * from t_employee where commission_pct is null ;
#查询“李冰冰”、“周旭飞”、“李易峰”这几个员工的信息
select * from t_employee where ename in ( '李冰冰' , '周旭飞' , '李易峰' );
#查询部门编号为2、3的员工信息
select * from t_employee where did in ( 2 , 3 );
#查询部门编号不是2、3的员工信息
select * from t_employee where did not in ( 2 , 3 );
#查询薪资在[10000,15000]之间
select * from t_employee where salary between 10000 and 15000 ;
#查询姓名中第二个字是'冰'的员工
select * from t_employee where ename like '冰' ; #这么写等价于 ename='冰'
select * from t_employee where ename like '_冰%' ;
#这么写匹配的是第二个字是冰,后面可能没有第三个字,或者有好几个字
update t_employee set ename = '王冰' where ename = '李冰冰' ;
select * from t_employee where ename like '_冰_' ;
#这么写匹配的是第二个字是冰,后面有第三个字,且只有三个字
#查询员工的姓名、薪资、奖金比例、实发工资
#实发工资 = 薪资 + 薪资 * 奖金比例
select ename as 姓名 ,
salary as 薪资 ,
commission_pct as 奖金比例 ,
salary + salary * commission_pct as 实发工资
from t_employee ;
#NULL在mysql中比较和计算都有特殊性,所有的计算遇到的null都是null。
#实发工资 = 薪资 + 薪资 * 奖金比例
select ename as 姓名 ,
salary as 薪资 ,
commission_pct as 奖金比例 ,
salary + salary * ifnull ( commission_pct , 0 ) as 实发工资
from t_employee ;
区间或集合范围比较运算符(掌握)
1
2
3
4
区间范围: between x and y
not between x and y
集合范围: in ( x , x , x )
not in ( x , x , x )
1
2
3
4
5
6
7
8
9
10
11
12
#查询薪资在[10000,15000]
select * from t_employee where salary >= 10000 && salary <= 15000 ;
select * from t_employee where salary between 10000 and 15000 ;
#查询籍贯在这几个地方的
select * from t_employee where native_place in ( '北京' , '浙江' , '江西' );
#查询薪资不在[10000,15000]
select * from t_employee where salary not between 10000 and 15000 ;
#查询籍贯不在这几个地方的
select * from t_employee where native_place not in ( '北京' , '浙江' , '江西' );
模糊匹配比较运算符(掌握)
1
2
3
4
5
6
7
8
9
10
11
#查询名字中包含'冰'字
select * from t_employee where ename like '%冰%' ;
#查询名字以‘雷'结尾的
select * from t_employee where ename like '%雷' ;
#查询名字以’李'开头
select * from t_employee where ename like '李%' ;
#查询名字有冰这个字,但是冰的前面只能有1个字
select * from t_employee where ename like '_冰%' ;
1
2
#查询当前mysql数据库的字符集情况
show variables like '%character%' ;
逻辑运算符(掌握)
1
2
3
逻辑与: && 或 and
逻辑或: || 或 or
逻辑非: ! 或 not
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#查询薪资高于15000,并且性别是男的员工
select * from t_employee where salary > 15000 and gender = '男' ;
select * from t_employee where salary > 15000 && gender = '男' ;
select * from t_employee where salary > 15000 & gender = '男' ; #错误 &按位与
select * from t_employee where ( salary > 15000 ) & ( gender = '男' );
#查询薪资高于15000,或者did为1的员工
select * from t_employee where salary > 15000 or did = 1 ;
select * from t_employee where salary > 15000 || did = 1 ;
#查询薪资不在[15000,20000]范围的
select * from t_employee where salary not between 15000 and 20000 ;
select * from t_employee where ! ( salary between 15000 and 20000 );
关于null值的问题(掌握)
1
2
3
4
5
6
7
#(1)判断时
xx is null
xx is not null
xx <=> null
#(2)计算时
ifnull ( xx , 代替值 ) 当 xx是null时 ,用代替值计算
1
2
3
4
5
6
7
#查询奖金比例为null的员工
select * from t_employee where commission_pct = null ; #失败
select * from t_employee where commission_pct = NULL ; #失败
select * from t_employee where commission_pct = 'NULL' ; #失败
select * from t_employee where commission_pct is null ; #成功
select * from t_employee where commission_pct <=> null ; #成功 <=>安全等于
1
2
3
4
5
6
#查询员工的实发工资,实发工资 = 薪资 + 薪资 * 奖金比例
select ename , salary + salary * commission_pct "实发工资" from t_employee ; #失败,
当 commission_pct为null ,结果都为 null
select ename , salary , commission_pct , salary + salary *
ifnull ( commission_pct , 0 ) "实发工资" from t_employee ;
系统预定义函数
函数:代表一个独立的可复用的功能。
和Java中的方法有所不同,不同点在于:MySQL中的函数必须有返回值,参数可以有可以没有。
MySQL中函数分为:
(1)系统预定义函数:MySQL数据库管理软件给我提供好的函数,直接用就可以,任何数据库都可以用公共的函数。
(2)用户自定义函数:由开发人员自己定义的,通过CREATE FUNCTION语句定义,是属于某个数据库的对象。
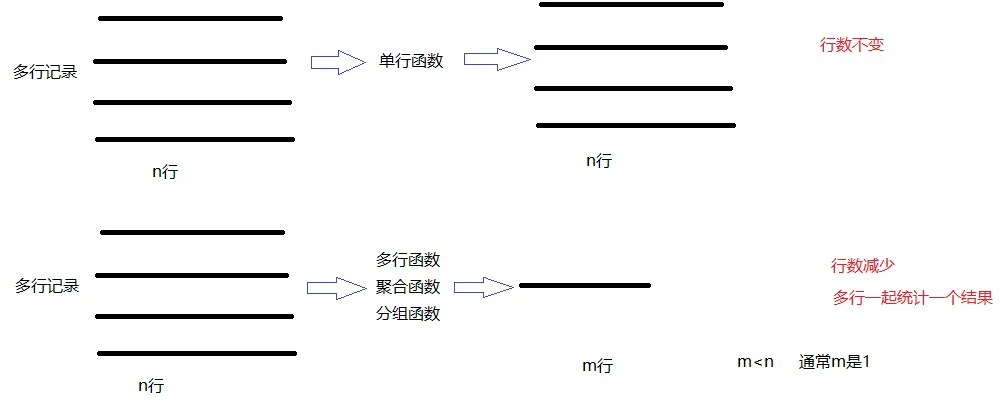
分组函数
调用完函数后,结果的行数变少了,可能得到一行,可能得到少数几行。
分组函数有合并计算过程。
常用分组函数类型
AVG(x) :求平均值SUM(x) :求总和MAX(x) :求最大值MIN(x) :求最小值COUNT(x) :统计记录数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#演示分组函数,聚合函数,多行函数
#统计t_employee表的员工的数量
SELECT COUNT ( * ) FROM t_employee ;
SELECT COUNT ( 1 ) FROM t_employee ;
SELECT COUNT ( eid ) FROM t_employee ;
SELECT COUNT ( commission_pct ) FROM t_employee ;
/*
count(*)或count(常量值):都是统计实际的行数。
count(字段/表达式):只统计“字段/表达式”部分非NULL值的行数。
*/
#找出t_employee表中最高的薪资值
SELECT MAX ( salary ) FROM t_employee ;
#找出t_employee表中最低的薪资值
SELECT MIN ( salary ) FROM t_employee ;
#统计t_employee表中平均薪资值
SELECT AVG ( salary ) FROM t_employee ;
#统计所有人的薪资总和,财务想看一下,一个月要准备多少钱发工资
SELECT SUM ( salary ) FROM t_employee ; #没有考虑奖金
SELECT SUM ( salary + salary * IFNULL ( commission_pct , 0 )) FROM t_employee ;
#找出年龄最小、最大的员工的出生日期
SELECT MAX ( birthday ), MIN ( birthday ) FROM t_employee ;
#查询最新入职的员工的入职日期
SELECT MAX ( hiredate ) FROM t_employee ;
关联查询(联合查询)
关联查询:两个或更多个表一起查询。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。
比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
关联查询分为几种情况
关联查询的SQL有几种情况
1、内连接:inner join ... on
结果:A表 ∩ B表
2、左连接:A left join B on
(2)A表全部
(3)A表- A∩B
3、右连接:A right join B on
(4)B表全部
(5)B表-A∩B
4、全外连接:full outer join ... on,但是mysql不支持这个关键字,mysql使用union(合并)结果的方式代替
(6)A表∪B表: (2) A表结果 union (4)B表的结果
(7)A∪B - A∩B (3)A表- A∩B结果 union (5)B表-A∩B结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/*
(1)凡是联合查询的两个表,必须有“关联字段”,
关联字段是逻辑意义一样,数据类型一样,名字可以一样也可以不一样的两个字段。
比如:t_employee (A表)中did和t_department(B表)中的did。
发现关联字段其实就是“可以”建外键的字段。当然联合查询不要求一定建外键。
(2)联合查询必须写关联条件,关联条件的个数 = n - 1.
n是联合查询的表的数量。
如果2个表一起联合查询,关联条件数量是1,
如果3个表一起联合查询,关联条件数量是2,
如果4个表一起联合查询,关联条件数量是3,
。。。。
否则就会出现笛卡尔积现象,这是应该避免的。
(3)关联条件可以用on子句编写,也可以写到where中。
但是建议用on单独编写,这样呢,可读性更好。
每一个join后面都要加on子句
A inner|left|right join B on 条件
A inner|left|right join B on 条件 inner|left|right jon C on 条件。
内连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
#演示内连接,结果是A∩B
/*
观察数据:
t_employee 看成A表
t_department 看成B表
此时t_employee (A表)中有 李红和周洲的did是NULL,没有对应部门,
t_department(B表)中有 测试部,在员工表中找不到对应记录的。
*/
#查询所有员工的姓名,部门编号,部门名称
#如果员工没有部门的,不要
#如果部门没有员工的,不要
/*
员工的姓名在t_employee (A表)中
部门的编号,在t_employee (A表)和t_department(B表)都有
部门名称在t_department(B表)中
所以需要联合两个表一起查询。
*/
SELECT ename , did , dname
FROM t_employee INNER JOIN t_department ;
#错误Column 'did' in field list is ambiguous
#因为did在两个表中都有,名字相同,它不知道取哪个表中字段了
#有同学说,它俩都是部门编号,随便取一个不就可以吗?
#mysql不这么认为,有可能存在两个表都有did,但是did的意义不同的情况。
#为了避免这种情况,需要在编写sql的时候,明确指出是用哪个表的did
SELECT ename , t_department . did , dname
FROM t_employee INNER JOIN t_department ;
#语法对,结果不太对
#结果出现“笛卡尔积”现象, A表记录 * B表记录
/*
(1)凡是联合查询的两个表,必须有“关联字段”,
关联字段是逻辑意义一样,数据类型一样,名字可以一样也可以不一样的两个字段。
比如:t_employee (A表)中did和t_department(B表)中的did。
发现关联字段其实就是可以建外键的字段。当然联合查询不要求一定建外键。
(2)联合查询必须写关联条件,关联条件的个数 = n - 1。
n是联合查询的表的数量。
如果2个表一起联合查询,关联条件数量是1,
如果3个表一起联合查询,关联条件数量是2,
如果4个表一起联合查询,关联条件数量是3,
。。。。
否则就会出现笛卡尔积现象,这是应该避免的。
(3)关联条件可以用on子句编写,也可以写到where中。
但是建议用on单独编写,这样呢,可读性更好。
每一个join后面都要加on子句
A inner|left|right join B on 条件
A inner|left|right join B on 条件 inner|left|right jon C on 条件
*/
SELECT ename , t_department . did , dname
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
#查询部门编号为1的女员工的姓名、部门编号、部门名称、薪资等情况
SELECT ename , gender , t_department . did , dname , salary
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did
WHERE t_department . did = 1 AND gender = '女' ;
#查询部门编号为1的员工姓名、部门编号、部门名称、薪资、职位编号、职位名称等情况
SELECT ename , gender , t_department . did , dname , salary , job_id , jname
FROM t_employee INNER JOIN t_department ON t_employee . did = t_department . did
INNER JOIN t_job ON t_employee . ` job_id ` = t_job . ` jid `
WHERE t_department . did = 1 ;
左连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#演示左连接
/*
(2)A
(3)A-A∩B
*/
/*
观察数据:
t_employee 看成A表
t_department 看成B表
此时t_employee (A表)中有 李红和周洲的did是NULL,没有对应部门,
t_department(B表)中有 测试部,在员工表中找不到对应记录的。
*/
#查询所有员工,包括没有指定部门的员工,他们的姓名、薪资、部门编号、部门名称
SELECT ename , salary , t_department . did , dname
FROM t_employee LEFT JOIN t_department
ON t_employee . did = t_department . did ;
#查询的是A结果 A left join B
#查询没有部门的员工信息
SELECT ename , salary , t_department . did , dname
FROM t_employee LEFT JOIN t_department
ON t_employee . did = t_department . did
WHERE t_employee . did IS NULL ;
#查询的结果是A - A∩B
#此时的where条件,建议写子表的关联字段is null,这样更准确一点。
#如果要建外键,它们肯定有子表和父表的角色,写子表的关联字段is null
#因为父表中这个字段一般是主键,不会为null。
右连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
/*
右连接
(4)B
(5)B - A∩B
*/
#演示右连接
/*
观察数据:
t_employee 看成A表
t_department 看成B表
此时t_employee (A表)中有 李红和周洲的did是NULL,没有对应部门,
t_department(B表)中有 测试部,在员工表中找不到对应记录的。
*/
#查询所有部门,包括没有对应员工的部门,他们的姓名、薪资、部门编号、部门名称
SELECT ename , salary , t_department . did , dname
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did ;
#查询的是B结果 A RIGHT join B
#查询没有员工部门的信息
SELECT ename , salary , t_department . did , dname
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
WHERE t_employee . did IS NULL ;
#查询的结果是B - A∩B
#此时的where条件,建议写子表的关联字段is null,这样更准确一点。
#如果要建外键,它们肯定有子表和父表的角色,写子表的关联字段is null
#因为父表中这个字段一般是主键,不会为null。
#查询所有员工,包括没有指定部门的员工,他们的姓名、薪资、部门编号、部门名称
SELECT ename , salary , t_department . did , dname
FROM t_department RIGHT JOIN t_employee
ON t_employee . did = t_department . did ;
#查询的是B结果 A RIGHT join B
#查询没有部门的员工信息
SELECT ename , salary , t_department . did , dname
FROM t_department RIGHT JOIN t_employee
ON t_employee . did = t_department . did
WHERE t_employee . did IS NULL ;
#查询的结果是B - A∩B A right join B
#此时的where条件,建议写子表的关联字段is null,这样更准确一点。
#如果要建外键,它们肯定有子表和父表的角色,写子表的关联字段is null
#因为父表中这个字段一般是主键,不会为null。
union
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
/*
union实现
(6)A∪B
(7)A∪B - A∩B
A-A∩B ∪ B-A∩B
*/
#演示用union合并两个查询结果实现A∪B 和A∪B - A∩B
/*
union合并时要注意:
(1)两个表要查询的结果字段是一样的
(2)UNION ALL表示直接合并结果,如果有重复的记录一并显示
ALL去掉表示合并结果时,如果有重复记录,去掉。
(3)要实现A∪B的结果,那么必须是合并 查询是A表结果和查询是B表结果的select语句。
同样要实现A∪B - A∩B的结果,那么必须是合并查询是A-A∩B结果和查询是B-A∩B的select语句。
*/
#查询所有员工和所有部门,包括没有指定部门的员工和没有分配员工的部门。
SELECT *
FROM t_employee LEFT JOIN t_department
ON t_employee . did = t_department . did
UNION
SELECT *
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did ;
#以下union会报错
SELECT * FROM t_employee
UNION
SELECT * FROM t_department ;
/*
错误代码: 1222
The used SELECT statements have a different number of columns
两个Select语句的列数是不同的。
column:列,表中的字段。
columns:很多的字段,即字段列表
select 字段列表 from 表名称;
*/
#联合 查询结果是A表的select 和查询结果是A∩B的select语句,是得不到A∪B
SELECT *
FROM t_employee LEFT JOIN t_department
ON t_employee . did = t_department . did
UNION
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
#查询那些没有分配部门的员工和没有指定员工的部门,即A表和B表在对方那里找不到对应记录的数据。
SELECT *
FROM t_employee LEFT JOIN t_department
ON t_employee . did = t_department . did
WHERE t_employee . did IS NULL
UNION
SELECT *
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
WHERE t_employee . did IS NULL ;
联合查询字段连表问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#查询字段的问题
#查询每一个员工及其所在部门的信息
#要求:显示员工的编号,姓名,部门编号,部门名称
SELECT eid , ename , did , dname
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
/*
错误代码: 1052
Column 'did' in field list is ambiguous(模糊不清的;引起歧义的)
*/
SELECT eid , ename , t_employee . did , dname
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
#查询每一个员工及其所在部门的信息
#要求,显示员工的编号,姓名,部门表的所有字段
SELECT eid , ename , t_department . *
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ;
select的七大子句
大字句顺序
(1)from:从哪些表中筛选
(2)on:关联多表查询时,去除笛卡尔积
(3)where:从表中筛选的条件
(4)group by:分组依据
(5)having:在统计结果中再次筛选(with rollup)
(6)order by:排序
(7)limit:分页
必须按照(1)-(7)的顺序编写子句。
from子句
1
2
3
#1、from子句
SELECT *
FROM t_employee ; #表示从某个表中筛选数据
on子句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#2、on子句
/*
(1)on必须配合join使用
(2)on后面只写关联条件
所谓关联条件是两个表的关联字段的关系
(3)有n张表关联,就有n-1个关联条件
两张表关联,就有1个关联条件
三张表关联,就有2个关联条件
*/
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did ; #1个关联条件
#查询员工的编号,姓名,职位编号,职位名称,部门编号,部门名称
#需要t_employee员工表,t_department部门表,t_job职位表
SELECT eid , ename , t_job . job_id , t_job . job_name ,
` t_department ` . ` did ` , ` t_department ` . ` dname `
FROM t_employee INNER JOIN t_department INNER JOIN t_job
ON t_employee . did = t_department . did AND t_employee . job_id = t_job . job_id ;
where子句
1
2
3
4
5
6
#3、where子句,在查询结果中筛选
#查询女员工的信息,以及女员工的部门信息
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee . did = t_department . did
WHERE gender = '女' ;
group by子句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#4、group by分组
#查询所有员工的平均薪资
SELECT AVG ( salary ) FROM t_employee ;
#查询每一个部门的平均薪资
SELECT did , ROUND ( AVG ( salary ), 2 )
FROM t_employee
GROUP BY did ;
#查询每一个部门的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
SELECT t_department . did , dname , ROUND ( AVG ( salary ), 2 )
FROM t_department LEFT JOIN t_employee
ON t_department . did = t_employee . did
GROUP BY t_department . did ;
#查询每一个部门的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
SELECT t_department . did , dname , IFNULL ( ROUND ( AVG ( salary ), 2 ), 0 )
FROM t_department LEFT JOIN t_employee
ON t_department . did = t_employee . did
GROUP BY t_department . did ;
#查询每一个部门的女员工的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
SELECT t_department . did , dname , IFNULL ( ROUND ( AVG ( salary ), 2 ), 0 )
FROM t_department LEFT JOIN t_employee
ON t_department . did = t_employee . did
WHERE gender = '女'
GROUP BY t_department . did ;
问题1:合计,WITH ROLLUP,加在group by后面
1
2
3
4
5
6
7
8
#问题1:合计,WITH ROLLUP,加在group by后面
#按照部门统计人数
SELECT did , COUNT ( * ) FROM t_employee GROUP BY did ;
#按照部门统计人数,并合计总数
SELECT did , COUNT ( * ) FROM t_employee GROUP BY did WITH ROLLUP ;
SELECT IFNULL ( did , '合计' ), COUNT ( * ) FROM t_employee GROUP BY did WITH ROLLUP ;
SELECT IFNULL ( did , '合计' ) AS "部门编号" , COUNT ( * ) AS "人数" FROM t_employee GROUP
BY did WITH ROLLUP ;
问题2:是否可以按照多个字段分组统计
1
2
3
4
5
#问题2:是否可以按照多个字段分组统计
#按照不同的部门,不同的职位,分别统计男和女的员工人数
SELECT did , job_id , gender , COUNT ( * )
FROM t_employee
GROUP BY did , job_id , gender ;
问题3:分组统计时,select后面字段列表的问题
1
2
3
4
5
6
7
8
9
#问题3:分组统计时,select后面字段列表的问题
SELECT eid , ename , did , COUNT ( * ) FROM t_employee ;
#eid,ename, did此时和count(*),不应该出现在select后面
SELECT eid , ename , did , COUNT ( * ) FROM t_employee GROUP BY did ;
#eid,ename此时和count(*),不应该出现在select后面
SELECT did , COUNT ( * ) FROM t_employee GROUP BY did ;
#分组统计时,select后面只写和分组统计有关的字段,其他无关字段不要出现,否则会引起歧义
having子句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#5、having
/*
having子句也写条件
where的条件是针对原表中的记录的筛选。where后面不能出现分组函数。
having子句是对统计结果(分组函数计算后)的筛选。having可以加分组函数。
*/
#查询每一个部门的女员工的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
#最后只显示平均薪资高于12000的部门信息
SELECT t_department . did , dname , IFNULL ( ROUND ( AVG ( salary ), 2 ), 0 )
FROM t_department LEFT JOIN t_employee
ON t_department . did = t_employee . did
WHERE gender = '女'
GROUP BY t_department . did
HAVING IFNULL ( ROUND ( AVG ( salary ), 2 ), 0 ) > 12000 ;
#查询每一个部门的男和女员工的人数
SELECT did , gender , COUNT ( * )
FROM t_employee
GROUP BY did , gender ;
#查询每一个部门的男和女员工的人数,显示部门编号,部门的名称,性别,人数
SELECT t_department . did , dname , gender , COUNT ( eid )
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
GROUP BY t_department . did , gender ;
#查询每一个部门薪资超过10000的男和女员工的人数,显示部门编号,部门的名称,性别,人数
#只显示人数低于3人
SELECT t_department . did , dname , gender , COUNT ( eid )
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
WHERE salary > 10000
GROUP BY t_department . did , gender
HAVING COUNT ( eid ) < 3 ;
order by子句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#6、排序 order by
/*
升序和降序,默认是升序
asc代表升序
desc 代表降序
*/
#查询员工信息,按照薪资从高到低
SELECT * FROM t_employee
ORDER BY salary DESC ;
#查询每一个部门薪资超过10000的男和女员工的人数,显示部门编号,部门的名称,性别,人数
#只显示人数低于3人,按照人数升序排列
SELECT t_department . did , dname , gender , COUNT ( eid )
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
WHERE salary > 10000
GROUP BY t_department . did , gender
HAVING COUNT ( eid ) < 3
ORDER BY COUNT ( eid );
#查询员工的薪资,按照薪资从低到高,薪资相同按照员工编号从高到低
SELECT *
FROM t_employee
ORDER BY salary ASC , eid DESC ;
limit子句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#演示limit子句
/*
limit子句是用于分页显示结果。
limit m,n
n:表示最多该页显示几行
m:表示从第几行开始取记录,第一个行的索引是0
m = (page-1)*n page表示第几页
每页最多显示5条,n=5
第1页,page=1,m = (1-1)*5 = 0; limit 0,5
第2页,page=2,m = (2-1)*5 = 5; limit 5,5
第3页,page=3,m = (3-1)*5 = 10; limit 10,5
*/
#查询员工表的数据,分页显示,每页显示5条记录
#第1页
SELECT * FROM t_employee LIMIT 0 , 5 ;
#第2页
SELECT * FROM t_employee LIMIT 5 , 5 ;
#第3页
SELECT * FROM t_employee LIMIT 10 , 5 ;
#第4页
SELECT * FROM t_employee LIMIT 15 , 5 ;
#第5页
SELECT * FROM t_employee LIMIT 20 , 5 ;
#第6页
SELECT * FROM t_employee LIMIT 25 , 5 ;
#查询所有的男员工信息,分页显示,每页显示3条,第2页
#limit m,n n=3,page=2,m=(page-1)*n=3
SELECT *
FROM t_employee
WHERE gender = '男'
LIMIT 3 , 3
#查询每一个编号为偶数的部门,显示部门编号,名称,员工数量,
#只显示员工数量>=2的结果,按照员工数量升序排列,
#每页显示2条,显示第1页
SELECT t_department . did , dname , COUNT ( eid )
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
WHERE t_department . did % 2 = 0
GROUP BY t_department . did
HAVING COUNT ( eid ) >= 2
ORDER BY COUNT ( eid )
LIMIT 0 , 2 ;
子查询
SELECT的SELECT中嵌套子查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/*
子查询:嵌套在另一个SQL语句中的查询。
SELECT语句可以嵌套在另一个SELECT中,UPDATE,DELETE,INSERT,CREATE语句等。
(1)SELECT的SELECT中嵌套子查询
*/
#(1)在“t_employee”表中查询每个人薪资和公司平均薪资的差值,
#并显示员工薪资和公司平均薪资相差5000元以上的记录。
SELECT ename AS "姓名" ,
salary AS "薪资" ,
ROUND (( SELECT AVG ( salary ) FROM t_employee ), 2 ) AS "全公司平均薪资" ,
ROUND ( salary - ( SELECT AVG ( salary ) FROM t_employee ), 2 ) AS "差值"
FROM t_employee
WHERE ABS ( ROUND ( salary - ( SELECT AVG ( salary ) FROM t_employee ), 2 )) > 5000 ;
#(2)在“t_employee”表中查询每个部门平均薪资和公司平均薪资的差值。
SELECT did , AVG ( salary ),
AVG ( salary ) - ( SELECT AVG ( salary ) FROM t_employee )
FROM t_employee
GROUP BY did ;
SELECT的WHERE或HAVING中嵌套子查询
当子查询结果作为外层另一个SQL的过滤条件,通常把子查询嵌入到WHERE或HAVING中。根据子查询结果的情况,分为如下三种情况。
当子查询的结果是单列单个值,那么可以直接使用比较运算符,如“<”、“<=”、“>”、“>=”、“=”、“!=”等与子查询结果进行比较。
当子查询的结果是单列多个值,那么可以使用比较运算符IN或NOT IN进行比较。
当子查询的结果是单列多个值,还可以使用比较运算符, 如“<”、“<=”、“>”、“>=”、“=”、“!=”等搭配ANY、SOME、ALL等关键字与查询结果进行比较。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
/*
子查询嵌套在where后面。
在where或having后面的子查询结果是:
(1)单个值,那么可以用=,>,<,>=,<=,!=这样的运算符和子查询的结果做比较
(2)多个值,那么需要用in,not in, >all,>any....形式做比较
如“<”、“<=”、“>”、“>=”、“=”、“!=”等搭配ANY、SOME、ALL等关键字与查询结果进行比较
*/
#(1)在“t_employee”表中查询薪资最高的员工姓名(ename)和薪资(salary)。
#SELECT ename,MAX(salary) FROM t_employee;#错误
#取表中第一行员工的姓名和全公司最高的薪资值一起显示。
SELECT ename , salary
FROM t_employee
WHERE salary = ( SELECT MAX ( salary ) FROM t_employee );
#(2)在“t_employee”表中查询比全公司平均薪资高的男员工姓名和薪资。
SELECT ename , salary
FROM t_employee
WHERE salary > ( SELECT AVG ( salary ) FROM t_employee ) AND gender = '男' ;
#(3)在“t_employee”表中查询和“白露”,“谢吉娜”同一部门的员工姓名和电话。
SELECT ename , tel , did
FROM t_employee
WHERE did IN ( SELECT did FROM t_employee WHERE ename = '白露' || ename = '谢吉娜' );
SELECT ename , tel , did
FROM t_employee
WHERE did = ANY ( SELECT did FROM t_employee WHERE ename = '白露' || ename = '谢吉娜' );
#(4)在“t_employee”表中查询薪资比“白露”,“李诗雨”,“黄冰茹”三个人的薪资都要高的员工姓名和薪
资。
SELECT ename , salary
FROM t_employee
WHERE salary > ALL ( SELECT salary FROM t_employee WHERE ename IN ( '白露' , '李诗雨' , '黄
冰茹' ));
#(5)查询“t_employee”和“t_department”表,按部门统计平均工资,
#显示部门平均工资比全公司的总平均工资高的部门编号、部门名称、部门平均薪资,
#并按照部门平均薪资升序排列。
SELECT t_department . did , dname , AVG ( salary )
FROM t_employee RIGHT JOIN t_department
ON t_employee . did = t_department . did
GROUP BY t_department . did
HAVING AVG ( salary ) > ( SELECT AVG ( salary ) FROM t_employee )
ORDER BY AVG ( salary );
SELECT中的EXISTS型子查询
EXISTS型子查询也是存在外层SELECT的WHERE子句中,不过它和上面的WHERE型子查询的工作模式不相同,所以这里单独讨论它。
如果EXISTS关键字后面的参数是一个任意的子查询,系统将对子查询进行运算以判断它是否返回行,如果至少返回一行,那么EXISTS的结果为true,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么EXISTS的结果为false,此时外层查询语句不进行查询。EXISTS和NOT EXISTS的结果只取决于是否返回行,而不取决于这些行的内容,所以这个子查询输入列表通常是无关紧要的。
如果EXISTS关键字后面的参数是一个关联子查询,即子查询的WHERE条件中包含与外层查询表的关联条件,那么此时将对外层查询表做循环,即在筛选外层查询表的每一条记录时,都看这条记录是否满足子查询的条件,如果满足就再用外层查询的其他WHERE条件对该记录进行筛选,否则就丢弃这行记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#exist型子查询
/*
(1)exists()中的子查询和外面的查询没有联合的情况下,
如果exists()中的子查询没有返回任何行,那么外面的子查询就不查了。
(2)exists()中的子查询与外面的查询有联合工作的情况下,
循环进行把外面查询表的每一行记录的值,代入()中子查询,如果可以查到结果,
就留下外面查询的这条记录,否则就舍去。
*/
#(1)查询“t_employee”表中是否存在部门编号为NULL的员工,
#如果存在,查询“t_department”表的部门编号、部门名称。
SELECT * FROM t_department
WHERE EXISTS ( SELECT * FROM t_employee WHERE did IS NULL );
#(2)查询“t_department”表是否存在与“t_employee”表相同部门编号的记录,
#如果存在,查询这些部门的编号和名称。
SELECT * FROM t_department
WHERE EXISTS ( SELECT * FROM t_employee WHERE t_employee . did = t_department . did );
#查询结果等价于下面的sql
SELECT DISTINCT t_department . *
FROM t_department INNER JOIN t_employee
ON t_department . did = t_employee . did ;
SELECT的FROM中嵌套子查询
当子查询结果是多列的结果时,通常将子查询放到FROM后面,然后采用给子查询结果取别名的方式,把子查询结果当成一张“动态生成的临时表”使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#子查询嵌套在from后面
/*
当一个查询要基于另一个查询结果来筛选的时候,
另一个查询还是多行多列的结果,那么就可以把这个查询结果当成一张临时表,
放在from后面进行再次筛选。
*/
#(1)在“t_employee”表中,查询每个部门的平均薪资,
#然后与“t_department”表联合查询
#所有部门的部门编号、部门名称、部门平均薪资。
SELECT did , AVG ( salary ) FROM t_employee GROUP BY did ;
+------+-------------+
| did | AVG ( salary ) |
+------+-------------+
| 1 | 11479 . 3125 |
| 2 | 13978 |
| 3 | 37858 . 25 |
| 4 | 12332 |
| 5 | 11725 |
+------+-------------+
5 ROWS IN SET ( 0 . 00 sec )
#用上面的查询结果,当成一张临时表,与t_department部门表做联合查询
#要给这样的子查询取别名的方式来当临时表用,不取别名是不可以的。
#而且此时的别名不能加""
#字段的别名可以加"",表的别名不能加""
SELECT t_department . did , dname , AVG ( salary )
FROM t_department LEFT JOIN ( SELECT did , AVG ( salary ) FROM t_employee GROUP BY
did ) temp
ON t_department . did = temp . did ;
#错误,from后面的t_department和temp表都没有salary字段,
#SELECT t_department.did ,dname,AVG(salary)出现AVG(salary)是错误的
SELECT t_department . did , dname , pingjun
FROM t_department LEFT JOIN ( SELECT did , AVG ( salary ) AS pingjun FROM t_employee
GROUP BY did ) temp
ON t_department . did = temp . did ;
#(2)在“t_employee”表中查询每个部门中薪资排名前2的员工姓名、部门编号和薪资。
SELECT * FROM (
SELECT ename , did , salary ,
DENSE_RANK () over ( PARTITION BY did ORDER BY salary DESC ) AS paiming
FROM t_employee ) temp
WHERE temp . paiming <= 2 ;
SQL示例演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
#演示和数据表相关的DDL语句
#为了方便接下来的演示,最好在前面确定针对哪个数据库的表格演示
#使用数据库
use test ;
#查看当前登录用户在本库下能够看到的所有表格
show tables ;
#如果前面没有use语句,或者在当前use语句下,要查看另一个数据库的表格。
show tables from 数据库名 ;
#例如:查看当前数据库的表格
show tables ;
#例如:在当前use atguigu;下面,查看mysql库的表格
show tables from mysql ;
#创建表格
create table 表名称 (
字段名 1 数据类型 1 ,
字段名 2 数据类型 2 #如果后面没有其他字段或约束的定义,后面就不用加,
);
#例如:创建一个teacher表
/*
包含编号、姓名、性别、出生日期、薪资、电话号码
*/
create table teacher (
id int ,
name varchar ( 20 ),
gender enum ( '男' , '女' ),
birthday date ,
salary double ,
tel varchar ( 11 )
);
#查看表结构
desc 表名称 ;
describe 表名称 ;
#例如:查看teacher表的结构
desc teacher ;
describe teacher ;
mysql > describe teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
6 rows in set ( 0 . 00 sec )
#查看表格的详细定义
show create table 表名称 ;
#例如:查看teacher表的定义语句
show create table teacher ;
mysql > show create table teacher \ G
*************************** 1 . row ***************************
Table : teacher
Create Table : CREATE TABLE ` teacher ` (
` id ` int DEFAULT NULL ,
` name ` varchar ( 20 ) DEFAULT NULL ,
` gender ` enum ( '男' , '女' ) DEFAULT NULL ,
` birthday ` date DEFAULT NULL ,
` salary ` double DEFAULT NULL ,
` tel ` varchar ( 11 ) DEFAULT NULL
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci
1 row in set ( 0 . 00 sec )
#修改表结构
#增加一个字段
alter table 表名称 add column 字段名 数据类型 ;
#column表示列,字段,可以省略
#例如:给teacher表增加一个address varchar(100)字段
alter table teacher add column address varchar ( 100 );
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
7 rows in set ( 0 . 00 sec )
#在某个字段后面增加一个字段
alter table 表名称 add column 字段名 数据类型 after 另一个字段 ;
#column表示列,字段,可以省略
#例如:给teacher表增加一个cardid char(18)字段,增加到name后面
alter table teacher add column cardid char ( 18 ) after name ;
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
8 rows in set ( 0 . 00 sec )
#增加一个字段,称为第一个字段
alter table 表名称 add column 字段名 数据类型 first ;
#column表示列,字段,可以省略
#例如:给teacher表增加一个age int字段,增加到id前面
alter table teacher add column age int first ;
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| age | int | YES | | NULL | |
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
9 rows in set ( 0 . 01 sec )
#删除字段
alter table 表名称 drop column 字段名 ;
#column可以省略
#例如:删除teacher表的age字段
alter table teacher drop column age ;
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
8 rows in set ( 0 . 00 sec )
#修改字段的数据类型
alter table 表名称 modify column 字段名 新的数据类型 ;
#例如:修改teacher表的salary字段,数据类型修改为double(10,2)
alter table teacher modify column salary double ( 10 , 2 );
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double ( 10 , 2 ) | YES | | NULL | |
| tel | varchar ( 11 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
8 rows in set ( 0 . 00 sec )
#修改字段的名称
alter table 表名称 change column 旧字段名 新的字段名 数据类型 ;
#例如:修改teacher表的tel字段,字段名修改为telphone
alter table teacher change column tel telphone char ( 18 );
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double ( 10 , 2 ) | YES | | NULL | |
| telphone | char ( 18 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
8 rows in set ( 0 . 01 sec )
#修改字段的顺序
alter table 表名称 modify column 字段名 数据类型 after 另一个字段 ;
alter table 表名称 modify column 字段名 数据类型 first ;
#例如,把teacher表的salary调整到telphone后面
alter table teacher modify column salary double ( 10 , 2 ) after telphone ;
mysql > desc teacher ;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-----------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| cardid | char ( 18 ) | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| telphone | char ( 18 ) | YES | | NULL | |
| salary | double ( 10 , 2 ) | YES | | NULL | |
| address | varchar ( 100 ) | YES | | NULL | |
+----------+-----------------+------+-----+---------+-------+
8 rows in set ( 0 . 00 sec )
#修改表名称
rename table 旧表名称 to 新表名称 ;
alter table 表名称 rename 新表名称 ;
#把teacher表重命名为jiaoshi
rename table teacher to jiaoshi ;
#把jiaoshi表重命名为teacher
alter table jiaoshi rename teacher ;
#删除表结构(数据一并删除)
drop table 表名称 ;
#删除teacher表格
drop table teacher ;
DML
添加语句
(1)添加一条记录到某个表中
1
insert into 表名称 values ( 值列表 ); #值列表中的值的顺序、类型、个数必须与表结构一一对应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
mysql > desc teacher ;
+----------+------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+------------------------+------+-----+---------+-------+
| tid | int ( 11 ) | YES | | NULL | |
| tname | varchar ( 5 ) | YES | | NULL | |
| salary | double | YES | | NULL | |
| weight | double | YES | | NULL | |
| birthday | date | YES | | NULL | |
| gender | enum ( '男' , '女' ) | YES | | NULL | |
| blood | enum ( 'A' , 'B' , 'AB' , 'O' ) | YES | | NULL | |
| phone | char ( 11 ) | YES | | NULL | |
+----------+------------------------+------+-----+---------+-------+
8 rows in set ( 0 . 00 sec )
1
2
insert into teacher values ( 1 , '张三' , 15000 , 120 . 5 , '1990-5-
1' , '男' , 'O' , '13789586859' );
1
2
3
4
5
insert into teacher values ( 2 , '李四' , 15000 , '1990-5-1' , '男' , 'O' , '13789586859' ); #缺
体重 weight的值
ERROR 1136 ( 21 S01 ): Column (列) count (数量) doesn 't match(不匹配) value(值)
count(数量) at row 1
(2)添加一条记录到某个表中
1
insert into 表名称 ( 字段列表 ) values ( 值列表 ); #值列表中的值的顺序、类型、个数必须与(字段列表)一一对应
1
insert into teacher ( tid , tname , salary , phone ) values ( 3 , '王五' , 16000 , '15789546586' );
(3)添加多条记录到某个表中
1
insert into 表名称 values ( 值列表 ),( 值列表 ),( 值列表 ); #值列表中的值的顺序、类型、个数必须与表结构一一对应
1
insert into 表名称 ( 字段列表 ) values ( 值列表 ),( 值列表 ),( 值列表 ); #值列表中的值的顺序、类型、个数必须与(字段列表)一一对应
1
2
3
4
insert into teacher ( tid , tname , salary , phone )
values ( 4 , '赵六' , 16000 , '15789546586' ),
( 5 , '汪飞' , 18000 , '15789548886' ),
( 6 , '天琪' , 19000 , '15909546586' );
(4)示例演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
#演示基本的,简单的DML语句
#基于tempdb数据库演示
create database tempdb ;
use tempdb ;
#创建teacher表
create table teacher (
id int ,
name varchar ( 20 ),
gender enum ( 'm' , 'f' ),
birthday date ,
salary double ,
tel varchar ( 11 )
);
#查看teacher表结构
mysql > desc teacher ;
+----------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar ( 20 ) | YES | | NULL | |
| gender | enum ( 'm' , 'f' ) | YES | | NULL | |
| birthday | date | YES | | NULL | |
| salary | double | YES | | NULL | |
| tel | char ( 18 ) | YES | | NULL | |
+----------+---------------+------+-----+---------+-------+
6 rows in set ( 0 . 01 sec )
#添加数据
#(1)第一种情况,给所有字段赋值
insert into 表名称 values ( 值列表 );
#这种情况要求(值列表)的每一个值的类型、顺序与表结构一一对应
#表中有几个字段,(值列表)必须有几个值,不能多也不能少
#值如果是字符串或日期类型,需要加单引号
#例如:添加一条记录到teacher表
insert into teacher values
( 1 , '张三' , 'm' , '1998-7-8' , 15000 . 0 , '18256953685' );
#例如:添加一条记录到teacher表
insert into teacher values
( 2 , '李四' , 'f' , '1998-7-8' , 15000 . 0 ); #少了电话号码
mysql > insert into teacher values
-> ( 2 , '李四' , 'f' , '1998-7-8' , 15000 . 0 );
ERROR 1136 ( 21 S01 ): Column count doesn 't match value count at row 1'
#(值列表)中值的数量和表结构中column列的数量不一致。
#例如:添加一条记录到teacher表
insert into teacher values
( 2 , '李四' , 'f' , '北京宏福苑' , 15000 . 0 , '18256953685' ); #把生日写称为地址
mysql > insert into teacher values
-> ( 2 , '李四' , 'f' , '北京宏福苑' , 15000 . 0 , '18256953685' );
ERROR 1292 ( 22007 ): Incorrect date value : '北京宏福苑' for column 'birthday' at
row 1
#日期格式不对
#(2)第二种情况,给部分字段赋值
insert into 表名称 ( 部分字段列表 ) values ( 值列表 );
#此时(值列表)中的值的数量、格式、顺序与(部分字段列表)对应即可
#例如:添加一条记录到teacher表,只给id和name字段赋值
insert into teacher ( id , name ) values ( 2 , '李四' );
mysql > select * from teacher ;
+------+------+--------+------------+--------+-------------+
| id | name | gender | birthday | salary | tel |
+------+------+--------+------------+--------+-------------+
| 1 | 张三 | m | 1998 - 07 - 08 | 15000 | 18256953685 |
| 2 | 李四 | NULL | NULL | NULL | NULL |
+------+------+--------+------------+--------+-------------+
2 rows in set ( 0 . 00 sec )
#没有赋值的字段都是默认值,此时默认值是NULL
#这种情况,当某个字段设置了“非空NOT NULL”约束,又没有提前指定“默认值”,
#那么在添加时没有赋值的话,会报错。明天演示非空约束。
#(3)一次添加多条记录
insert into 表名称 values ( 值列表 1 ),( 值列表 2 )...;
insert into 表名称 ( 部分字段列表 ) values ( 值列表 ),( 值列表 2 )...;
#上面一个insert语句有几个(值列表)就表示添加几行记录。
#每一个值列表直接使用逗号分隔
#添加多条记录到teacher表
insert into teacher ( id , name ) values
( 3 , '王五' ),
( 4 , '宋鑫' ),
( 5 , '赵志浩' ),
( 6 , '杨业行' ),
( 7 , '牛钰琪' );
#查看数据
mysql > select * from teacher ;
+------+--------+--------+------------+--------+-------------+
| id | name | gender | birthday | salary | tel |
+------+--------+--------+------------+--------+-------------+
| 1 | 张三 | m | 1998 - 07 - 08 | 15000 | 18256953685 |
| 2 | 李四 | NULL | NULL | NULL | NULL |
| 3 | 王五 | NULL | NULL | NULL | NULL |
| 4 | 宋鑫 | NULL | NULL | NULL | NULL |
| 5 | 赵志浩 | NULL | NULL | NULL | NULL |
| 6 | 杨业行 | NULL | NULL | NULL | NULL |
| 7 | 牛钰琪 | NULL | NULL | NULL | NULL |
+------+--------+--------+------------+--------+-------------+
7 rows in set ( 0 . 00 sec )
修改语句
修改所有行
1
update 表名称 set 字段名 = 值 , 字段名 = 值 ; #给所有行修改
1
2
#修改所有人的薪资,都涨了1000
update teacher set salary = salary + 1000 ;
修改部分行
1
update 表名称 set 字段名 = 值 , 字段名 = 值 where 条件 ; #给满足条件的行修改
1
2
#修改天琪的薪资降低5000
update teacher set salary = salary - 5000 where tname = '天琪' ;
删除
删除部分行
1
delete from 表名称 where 条件 ;
1
delete from teacher where tname = '天琪' ;
删除整张表的数据,但表结构留下
截断表,清空表中的数据,只有表结构
truncate表和delete表的区别:
delete是一条一条删除记录的。如果在事务中,事务提交之前支持回滚。(后面会讲事务)。
truncate是把整个表drop,新建一张,效率更高。就算在事务中,也无法回滚。
同学问:是否可以删除salary字段的值,字段留着,值删掉
可以实现,但是不是用delete,用update
同学问:是否可以删除salary字段,连同字段和这个字段的数据都是删除
可以实现,但是不是用delete,用alter table 表名称 drop column 字段名;
同学问:只删除某个单元格的值
可以实现,但是不是用delete,用update
数据库SQL语言使用案例
操作数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
/*
查询所有数据库
标准语法:
SHOW DATABASES;
*/
-- 查询所有数据库
SHOW DATABASES ;
/*
查询某个数据库的创建语句
标准语法:
SHOW CREATE DATABASE 数据库名称;
*/
-- 查询mysql数据库的创建语句
SHOW CREATE DATABASE mysql ;
/*
创建数据库
标准语法:
CREATE DATABASE 数据库名称;
*/
-- 创建db1数据库
CREATE DATABASE db1 ;
/*
创建数据库,判断、如果不存在则创建
标准语法:
CREATE DATABASE IF NOT EXISTS 数据库名称;
*/
-- 创建数据库db2(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS db2 ;
/*
创建数据库、并指定字符集
标准语法:
CREATE DATABASE 数据库名称 CHARACTER SET 字符集名称;
*/
-- 创建数据库db3、并指定字符集utf8
CREATE DATABASE db3 CHARACTER SET utf8 ;
-- 查看db3数据库的字符集
SHOW CREATE DATABASE db3 ;
-- 练习:创建db4数据库、如果不存在则创建,指定字符集为gbk操作数据表
CREATE DATABASE IF NOT EXISTS db4 CHARACTER SET gbk ;
-- 查看db4数据库的字符集
SHOW CREATE DATABASE db4 ;
/*
修改数据库的字符集
标准语法:
ALTER DATABASE 数据库名称 CHARACTER SET 字符集名称;
*/
-- 修改数据库db4的字符集为utf8
ALTER DATABASE db4 CHARACTER SET utf8 ;
-- 查看db4数据库的字符集
SHOW CREATE DATABASE db4 ;
/*
删除数据库
标准语法:
DROP DATABASE 数据库名称;
*/
-- 删除db1数据库
DROP DATABASE db1 ;
/*
删除数据库,判断、如果存在则删除
标准语法:
DROP DATABASE IF EXISTS 数据库名称;
*/
-- 删除数据库db2,如果存在
DROP DATABASE IF EXISTS db2 ;
/*
使用数据库
标准语法:
USE 数据库名称;
*/
-- 使用db4数据库
USE db4 ;
/*
查询当前使用的数据库
标准语法:
SELECT DATABASE();
*/
-- 查询当前正在使用的数据库
SELECT DATABASE ();
操作数据表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
-- 使用mysql数据库
USE mysql ;
/*
查询所有数据表
标准语法:
SHOW TABLES;
*/
-- 查询库中所有的表
SHOW TABLES ;
/*
查询表结构
标准语法:
DESC 表名;
*/
-- 查询user表结构
DESC USER ;
/*
查询数据表的字符集
标准语法:
SHOW TABLE STATUS FROM 数据库名称 LIKE '表名';
*/
-- 查看mysql数据库中user表字符集
SHOW TABLE STATUS FROM mysql LIKE 'user' ;
/*
创建数据表
标准语法:
CREATE TABLE 表名(
列名 数据类型 约束,
列名 数据类型 约束,
...
列名 数据类型 约束
);
*/
-- 创建一个product商品表(商品编号、商品名称、商品价格、商品库存、上架时间)
CREATE TABLE product (
id INT ,
NAME VARCHAR ( 20 ),
price DOUBLE ,
stock INT ,
insert_time DATE
);
-- 查看product表详细结构
DESC product ;
/*
修改表名
标准语法:
ALTER TABLE 旧表名 RENAME TO 新表名;
*/
-- 修改product表名为product2
ALTER TABLE product RENAME TO product2 ;
/*
修改表的字符集
标准语法:
ALTER TABLE 表名 CHARACTER SET 字符集名称;
*/
-- 查看db3数据库中product2数据表字符集
SHOW TABLE STATUS FROM db3 LIKE 'product2' ;
-- 修改product2数据表字符集为gbk
ALTER TABLE product2 CHARACTER SET gbk ;
/*
给表添加列
标准语法:
ALTER TABLE 表名 ADD 列名 数据类型;
*/
-- 给product2表添加一列color
ALTER TABLE product2 ADD color VARCHAR ( 10 );
/*
修改表中列的数据类型
标准语法:
ALTER TABLE 表名 MODIFY 列名 数据类型;
*/
-- 将color数据类型修改为int
ALTER TABLE product2 MODIFY color INT ;
-- 查看product2表详细信息
DESC product2 ;
/*
修改表中列的名称和数据类型
标准语法:
ALTER TABLE 表名 CHANGE 旧列名 新列名 数据类型;
*/
-- 将color修改为address
ALTER TABLE product2 CHANGE color address VARCHAR ( 200 );
-- 查看product2表详细信息
/*
删除表中的列
标准语法:
ALTER TABLE 表名 DROP 列名;
*/
-- 删除address列
ALTER TABLE product2 DROP address ;
/*
删除表
标准语法:
DROP TABLE 表名;
*/
-- 删除product2表
DROP TABLE product2 ;
/*
删除表,判断、如果存在则删除
标准语法:
DROP TABLE IF EXISTS 表名;
*/
-- 删除product2表,如果存在则删除
DROP TABLE IF EXISTS product2 ;
新增表数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/*
给指定列添加数据
标准语法:
INSERT INTO 表名(列名1,列名2,...) VALUES (值1,值2,...);
*/
-- 向product表添加一条数据
INSERT INTO product ( id , NAME , price , stock , insert_time ) VALUES ( 1 , '手
机' , 1999 . 99 , 25 , '2020-02-02' );
-- 向product表添加指定列数据
INSERT INTO product ( id , NAME , price ) VALUES ( 2 , '电脑' , 3999 . 99 );
/*
给全部列添加数据
标准语法:
INSERT INTO 表名 VALUES (值1,值2,值3,...);
*/
-- 默认给全部列添加数据
INSERT INTO product VALUES ( 3 , '冰箱' , 1500 , 35 , '2030-03-03' );
/*
批量添加所有列数据
标准语法:
INSERT INTO 表名 VALUES (值1,值2,值3,...),(值1,值2,值3,...),(1,值2,值3,...);
*/
-- 批量添加数据
INSERT INTO product VALUES ( 4 , '洗衣机' , 800 , 15 , '2030-05-05' ),( 5 , '微波
炉' , 300 , 45 , '2030-06-06' );
修改和删除表数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/*
修改表数据
标准语法:
UPDATE 表名 SET 列名1 = 值1,列名2 = 值2,... [where 条件];
*/
-- 修改手机的价格为3500
UPDATE product SET price = 3500 WHERE NAME = '手机' ;
-- 修改电脑的价格为1800、库存为36
UPDATE product SET price = 1800 , stock = 36 WHERE NAME = '电脑' ;
/*
删除表数据
标准语法:
DELETE FROM 表名 [WHERE 条件];
*/
-- 删除product表中的微波炉信息
DELETE FROM product WHERE NAME = '微波炉' ;
-- 删除product表中库存为10的商品信息
DELETE FROM product WHERE stock = 10 ;
查询_数据准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
-- 创建db1数据库
CREATE DATABASE db1 ;
-- 使用db1数据库
USE db1 ;
-- 创建数据表
CREATE TABLE product (
id INT , -- 商品编号
NAME VARCHAR ( 20 ), -- 商品名称
price DOUBLE , -- 商品价格
brand VARCHAR ( 10 ), -- 商品品牌
stock INT , -- 商品库存
insert_time DATE -- 添加时间
);
-- 添加数据
INSERT INTO product VALUES
( 1 , '华为手机' , 3999 , '华为' , 23 , '2088-03-10' ),
( 2 , '小米手机' , 2999 , '小米' , 30 , '2088-05-15' ),
( 3 , '苹果手机' , 5999 , '苹果' , 18 , '2088-08-20' ),
( 4 , '华为电脑' , 6999 , '华为' , 14 , '2088-06-16' ),
( 5 , '小米电脑' , 4999 , '小米' , 26 , '2088-07-08' ),
( 6 , '苹果电脑' , 8999 , '苹果' , 15 , '2088-10-25' ),
( 7 , '联想电脑' , 7999 , '联想' , NULL , '2088-11-11' );
查询_查询全部
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
/*
查询全部数据
标准语法:
SELECT * FROM 表名;
*/
-- 查询product表所有数据
SELECT * FROM product ;
/*
查询指定列
标准语法:
SELECT 列名1,列名2,... FROM 表名;
*/
-- 查询名称、价格、品牌
SELECT NAME , price , brand FROM product ;
/*
去除重复查询
标准语法:
SELECT DISTINCT 列名1,列名2,... FROM 表名;
*/
-- 查询品牌
SELECT brand FROM product ;
-- 查询品牌,去除重复
SELECT DISTINCT brand FROM product ;
/*
计算列的值
标准语法:
SELECT 列名1 运算符(+ - * /) 列名2 FROM 表名;
如果某一列为null,可以进行替换
ifnull(表达式1,表达式2)
表达式1:想替换的列
表达式2:想替换的值
*/
-- 查询商品名称和库存,库存数量在原有基础上加10
SELECT NAME , stock + 10 FROM product ;
-- 查询商品名称和库存,库存数量在原有基础上加10。进行null值判断
SELECT NAME , IFNULL ( stock , 0 ) + 10 FROM product ;
/*
起别名
标准语法:
SELECT 列名1,列名2,... AS 别名 FROM 表名;
*/
-- 查询商品名称和库存,库存数量在原有基础上加10。进行null值判断。起别名为getSum
SELECT NAME , IFNULL ( stock , 0 ) + 10 AS getSum FROM product ;
SELECT NAME , IFNULL ( stock , 0 ) + 10 getSum FROM product ;
查询_条件查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/*
条件查询
标准语法:
SELECT 列名列表 FROM 表名 WHERE 条件;
*/
-- 查询库存大于20的商品信息
SELECT * FROM product WHERE stock > 20 ;
-- 查询品牌为华为的商品信息
SELECT * FROM product WHERE brand = '华为' ;
-- 查询金额在4000 ~ 6000之间的商品信息
SELECT * FROM product WHERE price >= 4000 AND price <= 6000 ;
SELECT * FROM product WHERE price BETWEEN 4000 AND 6000 ;
-- 查询库存为14、30、23的商品信息
SELECT * FROM product WHERE stock = 14 OR stock = 30 OR stock = 23 ;
SELECT * FROM product WHERE stock IN ( 14 , 30 , 23 );
-- 查询库存为null的商品信息
SELECT * FROM product WHERE stock IS NULL ;
-- 查询库存不为null的商品信息
SELECT * FROM product WHERE stock IS NOT NULL ;
-- 查询名称以小米为开头的商品信息
SELECT * FROM product WHERE NAME LIKE '小米%' ;
-- 查询名称第二个字是为的商品信息
SELECT * FROM product WHERE NAME LIKE '_为%' ;
-- 查询名称为四个字符的商品信息
SELECT * FROM product WHERE NAME LIKE '____' ;
-- 查询名称中包含电脑的商品信息
SELECT * FROM product WHERE NAME LIKE '%电脑%' ;
查询_聚合函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/*
聚合函数
标准语法:
SELECT 函数名(列名) FROM 表名 [WHERE 条件];
*/
-- 计算product表中总记录条数
SELECT COUNT ( * ) FROM product ;
-- 获取最高价格
SELECT MAX ( price ) FROM product ;
-- 获取最低库存
SELECT MIN ( stock ) FROM product ;
-- 获取总库存数量
SELECT SUM ( stock ) FROM product ;
-- 获取品牌为苹果的总库存数量
SELECT SUM ( stock ) FROM product WHERE brand = '苹果' ;
-- 获取品牌为小米的平均商品价格
SELECT AVG ( price ) FROM product WHERE brand = '小米' ;
查询_排序查询
1
2
3
4
5
6
7
8
9
10
11
12
13
/*
排序查询
标准语法:
SELECT 列名 FROM 表名 [WHERE 条件] ORDER BY 列名1 排序方式1,列名2 排序方式2;
*/
-- 按照库存升序排序
SELECT * FROM product ORDER BY stock ASC ;
-- 查询名称中包含手机的商品信息。按照金额降序排序
SELECT * FROM product WHERE NAME LIKE '%手机%' ORDER BY price DESC ;
-- 按照金额升序排序,如果金额相同,按照库存降序排列
SELECT * FROM product ORDER BY price ASC , stock DESC ;
查询_分组查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/*
分组查询
标准语法:
SELECT 列名 FROM 表名 [WHERE 条件] GROUP BY 分组列名 [HAVING 分组后条件过滤]
[ORDER BY 排序列名 排序方式];
*/
-- 按照品牌分组,获取每组商品的总金额
SELECT brand , SUM ( price ) FROM product GROUP BY brand ;
-- 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额
SELECT brand , SUM ( price ) FROM product WHERE price > 4000 GROUP BY brand ;
-- 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额,只显示总金额大于7000元的
SELECT brand , SUM ( price ) getSum FROM product WHERE price > 4000 GROUP BY brand
HAVING getSum > 7000 ;
-- 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额,只显示总金额大于7000元的、并按照总金额的降序排列
SELECT brand , SUM ( price ) getSum FROM product
WHERE price > 4000
GROUP BY brand
HAVING getSum > 7000
ORDER BY getSum DESC ;
查询_分页查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/*
分页查询
标准语法:
SELECT 列名 FROM 表名
[WHERE 条件]
[GROUP BY 分组列名]
[HAVING 分组后条件过滤]
[ORDER BY 排序列名 排序方式]
LIMIT 当前页数,每页显示的条数;
LIMIT 当前页数,每页显示的条数;
公式:当前页数 = (当前页数-1) * 每页显示的条数
*/
-- 每页显示3条数据
-- 第1页 当前页数=(1-1) * 3
SELECT * FROM product LIMIT 0 , 3 ;
-- 第2页 当前页数=(2-1) * 3
SELECT * FROM product LIMIT 3 , 3 ;
-- 第3页 当前页数=(3-1) * 3
SELECT * FROM product LIMIT 6 , 3 ;
约束_主键约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 创建学生表(编号、姓名、年龄) 编号设为主键
CREATE TABLE student (
id INT PRIMARY KEY ,
NAME VARCHAR ( 30 ),
age INT
);
-- 查询学生表的详细信息
DESC student ;
-- 添加数据
INSERT INTO student VALUES ( 1 , '张三' , 23 );
INSERT INTO student VALUES ( 2 , '李四' , 24 );
-- 删除主键
ALTER TABLE student DROP PRIMARY KEY ;
-- 建表后单独添加主键约束
ALTER TABLE student MODIFY id INT PRIMARY KEY ;
约束_主键自增约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 创建学生表(编号、姓名、年龄) 编号设为主键自增
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR ( 30 ),
age INT
);
-- 查询学生表的详细信息
DESC student ;
-- 添加数据
INSERT INTO student VALUES ( NULL , '张三' , 23 ),( NULL , '李四' , 24 );
-- 删除自增约束
ALTER TABLE student MODIFY id INT ;
INSERT INTO student VALUES ( NULL , '张三' , 23 );
-- 建表后单独添加自增约束
ALTER TABLE student MODIFY id INT AUTO_INCREMENT ;
约束_唯一约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 创建学生表(编号、姓名、年龄) 编号设为主键自增,年龄设为唯一
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR ( 30 ),
age INT UNIQUE
);
-- 查询学生表的详细信息
DESC student ;
-- 添加数据
INSERT INTO student VALUES ( NULL , '张三' , 23 );
INSERT INTO student VALUES ( NULL , '李四' , 23 );
-- 删除唯一约束
ALTER TABLE student DROP INDEX age ;
-- 建表后单独添加唯一约束
ALTER TABLE student MODIFY age INT UNIQUE ;
约束_非空约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 创建学生表(编号、姓名、年龄) 编号设为主键自增,姓名设为非空,年龄设为唯一
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR ( 30 ) NOT NULL ,
age INT UNIQUE
);
-- 查询学生表的详细信息
DESC student ;
-- 添加数据
INSERT INTO student VALUES ( NULL , '张三' , 23 );
-- 删除非空约束
ALTER TABLE student MODIFY NAME VARCHAR ( 30 );
INSERT INTO student VALUES ( NULL , NULL , 25 );
-- 建表后单独添加非空约束
ALTER TABLE student MODIFY NAME VARCHAR ( 30 ) NOT NULL ;
约束_外键约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
-- 创建db2数据库
CREATE DATABASE db2 ;
-- 使用db2数据库
USE db2 ;
/*
外键约束
标准语法:
CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主表主键列名)
*/
-- 建表时添加外键约束
-- 创建user用户表
CREATE TABLE USER (
id INT PRIMARY KEY AUTO_INCREMENT , -- id
NAME VARCHAR ( 20 ) NOT NULL -- 姓名
);
-- 添加用户数据
INSERT INTO USER VALUES ( NULL , '张三' ),( NULL , '李四' );
-- 创建orderlist订单表
CREATE TABLE orderlist (
id INT PRIMARY KEY AUTO_INCREMENT , -- id
number VARCHAR ( 20 ) NOT NULL , -- 订单编号
uid INT , -- 外键列
CONSTRAINT ou_fk1 FOREIGN KEY ( uid ) REFERENCES USER ( id )
);
-- 添加订单数据
INSERT INTO orderlist VALUES ( NULL , 'hm001' , 1 ),( NULL , 'hm002' , 1 ),
( NULL , 'hm003' , 2 ),( NULL , 'hm004' , 2 );
-- 添加一个订单,但是没有真实用户。添加失败
INSERT INTO orderlist VALUES ( NULL , 'hm005' , 3 );
-- 删除李四用户。删除失败
DELETE FROM USER WHERE NAME = '李四' ;
/*
删除外键约束
标准语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
*/
-- 删除外键约束
ALTER TABLE orderlist DROP FOREIGN KEY ou_fk1 ;
/*
建表后单独添加外键约束
标准语法:
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES
主表名(主键列名);
*/
-- 添加外键约束
ALTER TABLE orderlist ADD CONSTRAINT ou_fk1 FOREIGN KEY ( uid ) REFERENCES
USER ( id );
外键级联操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
/*
添加外键约束,同时添加级联更新 标准语法:
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名)
ON UPDATE CASCADE;
添加外键约束,同时添加级联删除 标准语法:
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名)
ON DELETE CASCADE;
添加外键约束,同时添加级联更新和级联删除 标准语法:
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名)REFERENCES 主表
名(主键列名)
ON UPDATE CASCADE ON DELETE CASCADE;
*/
-- 删除外键约束
ALTER TABLE orderlist DROP FOREIGN KEY ou_fk1 ;
-- 添加外键约束,同时添加级联更新和级联删除
ALTER TABLE orderlist ADD CONSTRAINT ou_fk1 FOREIGN KEY ( uid ) REFERENCES
USER ( id )
ON UPDATE CASCADE ON DELETE CASCADE ;
-- 将李四这个用户的id修改为3,订单表中的uid也自动修改
UPDATE USER SET id = 3 WHERE id = 2 ;
-- 将李四这个用户删除,订单表中的该用户所属的订单也自动删除
DELETE FROM USER WHERE id = 3 ;
表关系_一对一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
-- 创建db3数据库
CREATE DATABASE db3 ;
-- 使用db3数据库
USE db3 ;
-- 创建person表
CREATE TABLE person (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 20 ) -- 姓名
);
-- 添加数据
INSERT INTO person VALUES ( NULL , '张三' ),( NULL , '李四' );
-- 创建card表
CREATE TABLE card (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
number VARCHAR ( 20 ) UNIQUE NOT NULL , -- 身份证号
pid INT UNIQUE , -- 外键列
CONSTRAINT cp_fk1 FOREIGN KEY ( pid ) REFERENCES person ( id )
);
-- 添加数据
INSERT INTO card VALUES ( NULL , '12345' , 1 ),( NULL , '56789' , 2 );
表关系_一对多
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
-- 创建user表
CREATE TABLE USER (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 20 ) -- 姓名
);
-- 添加数据
INSERT INTO USER VALUES ( NULL , '张三' ),( NULL , '李四' );
-- 创建orderlist表
CREATE TABLE orderlist (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
number VARCHAR ( 20 ), -- 订单编号
uid INT , -- 外键列
CONSTRAINT ou_fk1 FOREIGN KEY ( uid ) REFERENCES USER ( id )
);
-- 添加数据
INSERT INTO orderlist VALUES ( NULL , 'hm001' , 1 ),( NULL , 'hm002' , 1 )( NULL , 'hm003' , 2 ),( NULL , 'hm004' , 2 );
/*
商品分类和商品
*/
-- 创建category表
CREATE TABLE category (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 10 ) -- 分类名称
);
-- 添加数据
INSERT INTO category VALUES ( NULL , '手机数码' ),( NULL , '电脑办公' );
-- 创建product表
CREATE TABLE product (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 30 ), -- 商品名称
cid INT , -- 外键列
CONSTRAINT pc_fk1 FOREIGN KEY ( cid ) REFERENCES category ( id )
);
-- 添加数据
INSERT INTO product VALUES ( NULL , '华为P30' , 1 ),( NULL , '小米note3' , 1 ),( NULL , '联想电脑' , 2 ),( NULL , '苹果电脑' , 2 );
表关系_多对多
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
-- 创建student表
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 20 ) -- 学生姓名
);
-- 添加数据
INSERT INTO student VALUES ( NULL , '张三' ),( NULL , '李四' );
-- 创建course表
CREATE TABLE course (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
NAME VARCHAR ( 10 ) -- 课程名称
);
-- 添加数据
INSERT INTO course VALUES ( NULL , '语文' ),( NULL , '数学' );
-- 创建中间表
CREATE TABLE stu_course (
id INT PRIMARY KEY AUTO_INCREMENT , -- 主键id
sid INT , -- 用于和student表中的id进行外键关联
cid INT , -- 用于和course表中的id进行外键关联
CONSTRAINT sc_fk1 FOREIGN KEY ( sid ) REFERENCES student ( id ), -- 添加外键约束
CONSTRAINT sc_fk2 FOREIGN KEY ( cid ) REFERENCES course ( id ) -- 添加外键约束
);
-- 添加数据
INSERT INTO stu_course VALUES ( NULL , 1 , 1 ),( NULL , 1 , 2 ),( NULL , 2 , 1 ),( NULL , 2 , 2 );
多表查询_数据准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
-- 创建db4数据库
CREATE DATABASE db4 ;
-- 使用db4数据库
USE db4 ;
-- 创建user表
CREATE TABLE USER (
id INT PRIMARY KEY AUTO_INCREMENT , -- 用户id
NAME VARCHAR ( 20 ), -- 用户姓名
age INT -- 用户年龄
);
-- 添加数据
INSERT INTO USER VALUES ( 1 , '张三' , 23 );
INSERT INTO USER VALUES ( 2 , '李四' , 24 );
INSERT INTO USER VALUES ( 3 , '王五' , 25 );
INSERT INTO USER VALUES ( 4 , '赵六' , 26 );
-- 订单表
CREATE TABLE orderlist (
id INT PRIMARY KEY AUTO_INCREMENT , -- 订单id
number VARCHAR ( 30 ), -- 订单编号
uid INT , -- 外键字段
CONSTRAINT ou_fk1 FOREIGN KEY ( uid ) REFERENCES USER ( id )
);
-- 添加数据
INSERT INTO orderlist VALUES ( 1 , 'hm001' , 1 );
INSERT INTO orderlist VALUES ( 2 , 'hm002' , 1 );
INSERT INTO orderlist VALUES ( 3 , 'hm003' , 2 );
INSERT INTO orderlist VALUES ( 4 , 'hm004' , 2 );
INSERT INTO orderlist VALUES ( 5 , 'hm005' , 3 );
INSERT INTO orderlist VALUES ( 6 , 'hm006' , 3 );
INSERT INTO orderlist VALUES ( 7 , 'hm007' , NULL );
-- 商品分类表
CREATE TABLE category (
id INT PRIMARY KEY AUTO_INCREMENT , -- 商品分类id
NAME VARCHAR ( 10 ) -- 商品分类名称
);
-- 添加数据
INSERT INTO category VALUES ( 1 , '手机数码' );
INSERT INTO category VALUES ( 2 , '电脑办公' );
INSERT INTO category VALUES ( 3 , '烟酒茶糖' );
INSERT INTO category VALUES ( 4 , '鞋靴箱包' );
-- 商品表
CREATE TABLE product (
id INT PRIMARY KEY AUTO_INCREMENT , -- 商品id
NAME VARCHAR ( 30 ), -- 商品名称
cid INT , -- 外键字段
CONSTRAINT cp_fk1 FOREIGN KEY ( cid ) REFERENCES category ( id )
);
-- 添加数据
INSERT INTO product VALUES ( 1 , '华为手机' , 1 );
INSERT INTO product VALUES ( 2 , '小米手机' , 1 );
INSERT INTO product VALUES ( 3 , '联想电脑' , 2 );
INSERT INTO product VALUES ( 4 , '苹果电脑' , 2 );
INSERT INTO product VALUES ( 5 , '中华香烟' , 3 );
INSERT INTO product VALUES ( 6 , '玉溪香烟' , 3 );
INSERT INTO product VALUES ( 7 , '计生用品' , NULL );
-- 中间表
CREATE TABLE us_pro (
upid INT PRIMARY KEY AUTO_INCREMENT , -- 中间表id
uid INT , -- 外键字段。需要和用户表的主键产生关联
pid INT , -- 外键字段。需要和商品表的主键产生关联
CONSTRAINT up_fk1 FOREIGN KEY ( uid ) REFERENCES USER ( id ),
CONSTRAINT up_fk2 FOREIGN KEY ( pid ) REFERENCES product ( id )
);
-- 添加数据
INSERT INTO us_pro VALUES ( NULL , 1 , 1 );
INSERT INTO us_pro VALUES ( NULL , 1 , 2 );
INSERT INTO us_pro VALUES ( NULL , 1 , 3 );
INSERT INTO us_pro VALUES ( NULL , 1 , 4 );
INSERT INTO us_pro VALUES ( NULL , 1 , 5 );
INSERT INTO us_pro VALUES ( NULL , 1 , 6 );
INSERT INTO us_pro VALUES ( NULL , 1 , 7 );
INSERT INTO us_pro VALUES ( NULL , 2 , 1 );
INSERT INTO us_pro VALUES ( NULL , 2 , 2 );
INSERT INTO us_pro VALUES ( NULL , 2 , 3 );
INSERT INTO us_pro VALUES ( NULL , 2 , 4 );
INSERT INTO us_pro VALUES ( NULL , 2 , 5 );
INSERT INTO us_pro VALUES ( NULL , 2 , 6 );
INSERT INTO us_pro VALUES ( NULL , 2 , 7 );
INSERT INTO us_pro VALUES ( NULL , 3 , 1 );
INSERT INTO us_pro VALUES ( NULL , 3 , 2 );
INSERT INTO us_pro VALUES ( NULL , 3 , 3 );
INSERT INTO us_pro VALUES ( NULL , 3 , 4 );
INSERT INTO us_pro VALUES ( NULL , 3 , 5 );
INSERT INTO us_pro VALUES ( NULL , 3 , 6 );
INSERT INTO us_pro VALUES ( NULL , 3 , 7 );
INSERT INTO us_pro VALUES ( NULL , 4 , 1 );
INSERT INTO us_pro VALUES ( NULL , 4 , 2 );
INSERT INTO us_pro VALUES ( NULL , 4 , 3 );
INSERT INTO us_pro VALUES ( NULL , 4 , 4 );
INSERT INTO us_pro VALUES ( NULL , 4 , 5 );
INSERT INTO us_pro VALUES ( NULL , 4 , 6 );
INSERT INTO us_pro VALUES ( NULL , 4 , 7 );
多表查询_内连接查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
/*
显示内连接
标准语法:
SELECT 列名 FROM 表名1 [INNER] JOIN 表名2 ON 关联条件;
*/
-- 查询用户信息和对应的订单信息
SELECT * FROM USER INNER JOIN orderlist ON orderlist . uid = user . id ;
-- 查询用户信息和对应的订单信息,起别名
SELECT * FROM USER u INNER JOIN orderlist o ON o . uid = u . id ;
-- 查询用户姓名,年龄。和订单编号
SELECT
u . name , -- 用户姓名
u . age , -- 用户年龄
o . number -- 订单编号
FROM
USER u -- 用户表
INNER JOIN
orderlist o -- 订单表
ON
o . uid = u . id ;
/*
隐式内连接
标准语法:
SELECT 列名 FROM 表名1,表名2 WHERE 关联条件;
*/
-- 查询用户姓名,年龄。和订单编号
SELECT
u . name , -- 用户姓名
u . age , -- 用户年龄
o . number -- 订单编号
FROM
USER u , -- 用户表
orderlist o -- 订单表
WHERE
o . uid = u . id ;
多表查询_外连接查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/*
左外连接
标准语法:
SELECT 列名 FROM 表名1 LEFT [OUTER] JOIN 表名2 ON 条件;
*/
-- 查询所有用户信息,以及用户对应的订单信息
SELECT
u . * ,
o . number
FROM
USER u
LEFT OUTER JOIN
orderlist o
ON
o . uid = u . id ;
/*
右外连接
标准语法:
SELECT 列名 FROM 表名1 RIGHT [OUTER] JOIN 表名2 ON 条件;
*/
-- 查询所有订单信息,以及订单所属的用户信息
SELECT
o . * ,
u . name
FROM
USER u
RIGHT OUTER JOIN
orderlist o
ON
o . uid = u . id ;
多表查询_子查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/*
结果是单行单列的
标准语法:
SELECT 列名 FROM 表名 WHERE 列名=(SELECT 列名 FROM 表名 [WHERE 条件]);
*/
-- 查询年龄最高的用户姓名
SELECT MAX ( age ) FROM USER ;
SELECT NAME , age FROM USER WHERE age = ( SELECT MAX ( age ) FROM USER );
/*
结果是多行单列的
标准语法:
SELECT 列名 FROM 表名 WHERE 列名 [NOT] IN (SELECT 列名 FROM 表名 [WHERE 条
件]);
*/
-- 查询张三和李四的订单信息
SELECT * FROM orderlist WHERE uid IN ( 1 , 2 );
SELECT id FROM USER WHERE NAME IN ( '张三' , '李四' );
SELECT * FROM orderlist WHERE uid IN ( SELECT id FROM USER WHERE NAME IN ( '张三' , '李四' ));
/*
结果是多行多列的
标准语法:
SELECT 列名 FROM 表名 [别名],(SELECT 列名 FROM 表名 [WHERE 条件]) [别名]
[WHERE 条件];
*/
-- 查询订单表中id大于4的订单信息和所属用户信息
SELECT * FROM orderlist WHERE id > 4 ;
SELECT
u . name ,
o . number
FROM
USER u ,
( SELECT * FROM orderlist WHERE id > 4 ) o
WHERE
o . uid = u . id ;
多表查询_多表查询练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
-- 1.查询用户的编号、姓名、年龄。订单编号
/*
分析
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id=orderlist.uid
*/
SELECT
u . id ,
u . name ,
u . age ,
o . number
FROM
USER u ,
orderlist o
WHERE
u . id = o . uid ;
-- 2.查询所有的用户。用户的编号、姓名、年龄。订单编号
/*
分析
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id=orderlist.uid
查询所有的用户,左外连接
*/
SELECT
u . id ,
u . name ,
u . age ,
o . number
FROM
USER u
LEFT OUTER JOIN
orderlist o
ON
u . id = o . uid ;
-- 3.查询所有的订单。用户的编号、姓名、年龄。订单编号
/*
分析
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id=orderlist.uid
查询所有的订单,右外连接
*/
SELECT
u . id ,
u . name ,
u . age ,
o . number
FROM
USER u
RIGHT OUTER JOIN
orderlist o
ON
u . id = o . uid ;
-- 4.查询用户年龄大于23岁的信息。显示用户的编号、姓名、年龄。订单编号
/*
分析
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id=orderlist.uid AND user.age > 23
*/
SELECT
u . id ,
u . name ,
u . age ,
o . number
FROM
USER u ,
orderlist o
WHERE
u . id = o . uid
AND
u . age > 23 ;
-- 5.查询张三和李四用户的信息。显示用户的编号、姓名、年龄。订单编号
/*
分析
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id=orderlist.uid AND user.name IN ('张三','李四')
*/
SELECT
u . id ,
u . name ,
u . age ,
o . number
FROM
USER u ,
orderlist o
WHERE
u . id = o . uid
AND
u . name IN ( '张三' , '李四' );
-- 6.查询商品分类的编号、分类名称。分类下的商品名称
/*
分析
商品分类的编号、分类名称 category表 商品名称 product表
条件:category.id=product.cid
*/
SELECT
c . id ,
c . name ,
p . name
FROM
category c ,
product p
WHERE
c . id = p . cid ;
-- 7.查询所有的商品分类。商品分类的编号、分类名称。分类下的商品名称
/*
分析
商品分类的编号、分类名称 category表 商品名称 product表
条件:category.id=product.cid
查询所有的商品分类,左外连接
*/
SELECT
c . id ,
c . name ,
p . name
FROM
category c
LEFT OUTER JOIN
product p
ON
c . id = p . cid ;
-- 8.查询所有的商品信息。商品分类的编号、分类名称。分类下的商品名称
/*
分析
商品分类的编号、分类名称 category表 商品名称 product表
条件:category.id=product.cid
查询所有的商品信息,右外连接
*/
SELECT
c . id ,
c . name ,
p . name
FROM
category c
RIGHT OUTER JOIN
product p
ON
c . id = p . cid ;
-- 9.查询所有的用户和该用户能查看的所有的商品。显示用户的编号、姓名、年龄。商品名称
/*
分析
用户的编号、姓名、年龄 user表 商品名称 product表 中间表 us_pro
条件:us_pro.uid=user.id AND us_pro.pid=product.id
*/
SELECT
u . id ,
u . name ,
u . age ,
p . name
FROM
USER u ,
product p ,
us_pro up
WHERE
up . uid = u . id
AND
up . pid = p . id ;
-- 10.查询张三和李四这两个用户可以看到的商品。显示用户的编号、姓名、年龄。商品名称
/*
分析
用户的编号、姓名、年龄 user表 商品名称 product表 中间表 us_pro
条件:us_pro.uid=user.id AND us_pro.pid=product.id AND user.name IN ('张三','李
四')
*/
SELECT
u . id ,
u . name ,
u . age ,
p . name
FROM
USER u ,
product p ,
us_pro up
WHERE
up . uid = u . id
AND
up . pid = p . id
AND
u . name IN ( '张三' , '李四' );
结尾